What Is the Purpose of __init__ in Python?

 Written by:
Written by:Nathan Rosidi
The __init__ method in Python initializes an object's attributes at creation, setting up each instance with specific values to keep code organized and scalable.
Why do Python classes always have __init__?
This particular approach extends basic initialization to define how objects are additionally initialized.
This article examines what this is intended to do, how it implements that idea and some best practices for using it in Python.
What is __init__ in Python? Understanding the Role of __init__ in Python?
In Python, the __init__ method is known as the initializer method. It is automatically called when you create a new instance of a class. It allows you to define custom behaviors that set up an object’s initial state, such as defining attributes or performing specific actions at the moment of object creation.
This method is commonly mistaken for a constructor, but in Python, the actual constructor is the __new__ method, which is responsible for creating an instance. The __init__ method focuses on initializing that instance, allowing you to pass values that tailor its properties.
How the __init__ Method Works in Python
In Python, the __init__ method is a class initializer. Before a new object is returned, it executes the __init__ method to initialize its state. It generally takes arguments, e.g., user-defined parameters, to initialize values to instant variables.
Of course, the variables are defined using the self keyword (representing the instance of this object).
So let's create a class Person with an __init__ method like the below code. This method stores arguments (name and age ) in self. name and self. age.
When a new Person object is created, these attributes are automatically assigned to an empty state using the __init__ method. Here is the code.
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
person1 = Person("Alice", 30)
print(person1.name)
print(person1.age)
Here is the output.

So, when we write person1 = Person("Alice", 30), it will call the __init__ with "Alice" and 30.
In the method, the self is assigned to "Alice". name and 30 to self. age.
Therefore, now person1 has a name and age initialised with the given values.
That happens behind the scenes with the __init__ method, which allows objects to be personalized at creation time.
Why Use Python __init__? Common Use Cases
This is important in a ton of real-world situations — you often want your objects to have some attributes or behavior right out of the box. One of the use cases is setting up default values or if we have to initialize each object instance with different data.
Consider an e-commerce platform where you want to instantiate different product objects. Within the _ _ init _ _ function, we can define each product's name, price, and category.
Here’s an example where we use __init__ to create a Product class that initializes each product with specific details:
class Product:
def __init__(self, name, price, category):
self.name = name
self.price = price
self.category = category
# Creating product instances
product1 = Product("Laptop", 999.99, "Electronics")
product2 = Product("Coffee Maker", 49.99, "Appliances")
# Accessing product details
print(product1.name)
print(product2.price)
print(product1.category)
Here is the output.

Comparing __init__ to Other Special Methods in Python
Even though __init__ is the most popular particular method in Python, it isn't the only one. Python has a bunch of so-called Python Magic Methods, sometimes also called dunder methods (due to their double underscores), that let you implement custom behavior for your classes.
Top selected plugins include the like of:
- __new__ : This is the actual constructor, which creates a new class instance.
- __str__: This method defines what string representation of the object will be returned when you print it as an argument.
- __repr__: Return a string representing the object, which can be helpful for debugging.
- __del__: Called when an object is about to be destroyed, cleaning up any resources.
Let's compare __init__ with different unique methods. To apply the above knowledge, we will create a class to show you how __init__, __str__ and __repr__ affect the behavior (creation) of an object:
class Car:
def __init__(self, make, model, year):
self.make = make
self.model = model
self.year = year
def __str__(self):
return f"{self.year} {self.make} {self.model}"
def __repr__(self):
return f"Car('{self.make}', '{self.model}', {self.year})"
# Creating an instance of Car
my_car = Car("Toyota", "Corolla", 2020)
# Using __str__ method (when printing the object)
print(my_car) # Output: 2020 Toyota Corolla
# Using __repr__ method (for representation in interactive mode or debugging)
print(repr(my_car)) # Output: Car('Toyota', 'Corolla', 2020)
Here is the output.

This method constructs the object when you instantiate a Car instance and sets its make, model, and year attributes.
- __str__ is an object’s saying: “When you print this, here’s how it should look.
- The __repr__ method returns a more formal string representation suitable for debugging and development.
- While __init__ helps initialize an object, these methods are essentially designed to work in conjunction with __init__ so that you have more control over how your objects act and look from a user and Python environment perspective.
Best Practices for Using Python __init__ in Data Science

When working on data science projects, whether building models, handling data, or creating visualizations, the __init__ method can be essential to organizing your code. Here’s how you can adapt the best practices for everyday tasks in data science.
Data Project: Black Friday Purchases

To do that, we’ll use the Black Friday Purchase data project.
Walmart wanted to understand customer purchasing behavior, specifically the relationship between gender and purchasing habits.
Link to this data project: https://platform.stratascratch.com/data-projects/black-friday-purchases
1. Keep __init__ Simple
So, the first thing we will do is create a simple data loader class. Here, the __init__ method will only be used to initialize the file path and load this dataset. Any data exploration or manipulation tasks will be done using a different function.
Here is the code.
class WalmartDataLoader:
def __init__(self, file_path):
self.file_path = file_path
self.data = None
def load_data(self):
self.data = pd.read_csv(self.file_path)
def get_head(self):
return self.data.head()
# Instantiate the data loader
walmart_loader = WalmartDataLoader("walmart_data.csv")
walmart_loader.load_data()
# Display the first few rows
walmart_loader.get_head()
Here is the output.
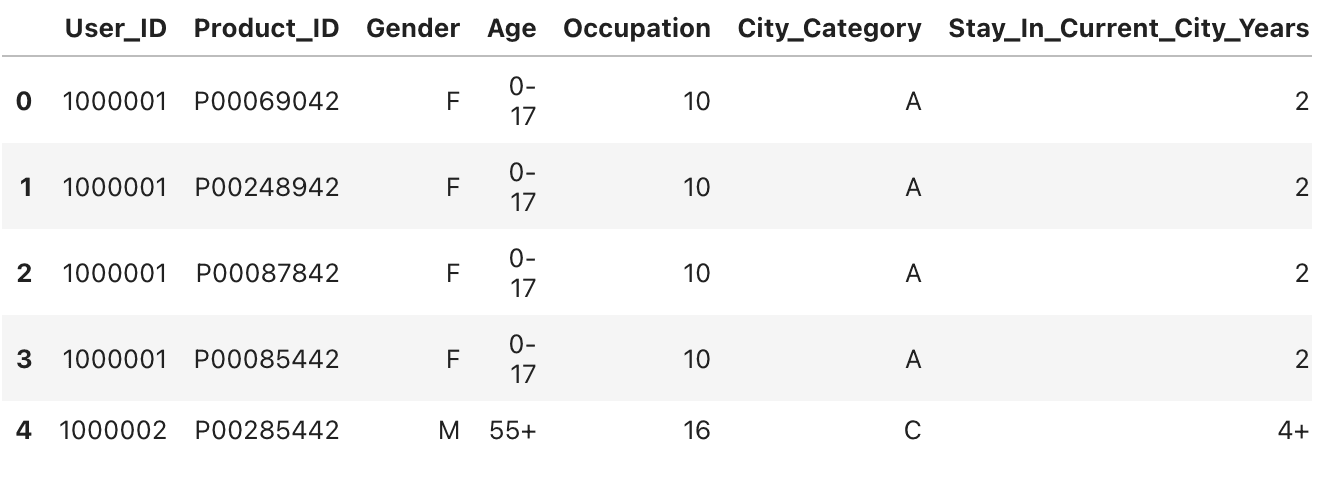
In the __init__ method, we just set the file path, and loading and exploration data are done in the load_data and get_head methods. That way, we keep the initialization simple and leave more complex operations for later.
2. Use Default Values
If you are creating a class for data visualization, then it could be beneficial to have default chart types so your team can generate fast insights. In this example, I show you how to use the Black Friday dataset to show gender spending.
Here is the code.
import matplotlib.pyplot as plt
class PurchasePlotter:
def __init__(self, data, x_column="Gender", y_column="Purchase", plot_type="bar"):
self.data = data
self.x_column = x_column
self.y_column = y_column
self.plot_type = plot_type
def plot(self):
grouped_data = self.data.groupby(self.x_column)[self.y_column].sum().reset_index()
if self.plot_type == "bar":
plt.bar(grouped_data[self.x_column], grouped_data[self.y_column])
elif self.plot_type == "line":
plt.plot(grouped_data[self.x_column], grouped_data[self.y_column])
plt.xlabel(self.x_column)
plt.ylabel(self.y_column)
plt.show()
# Using PurchasePlotter with default bar plot
plotter = PurchasePlotter(walmart_loader.data)
plotter.plot()
Here is the output.
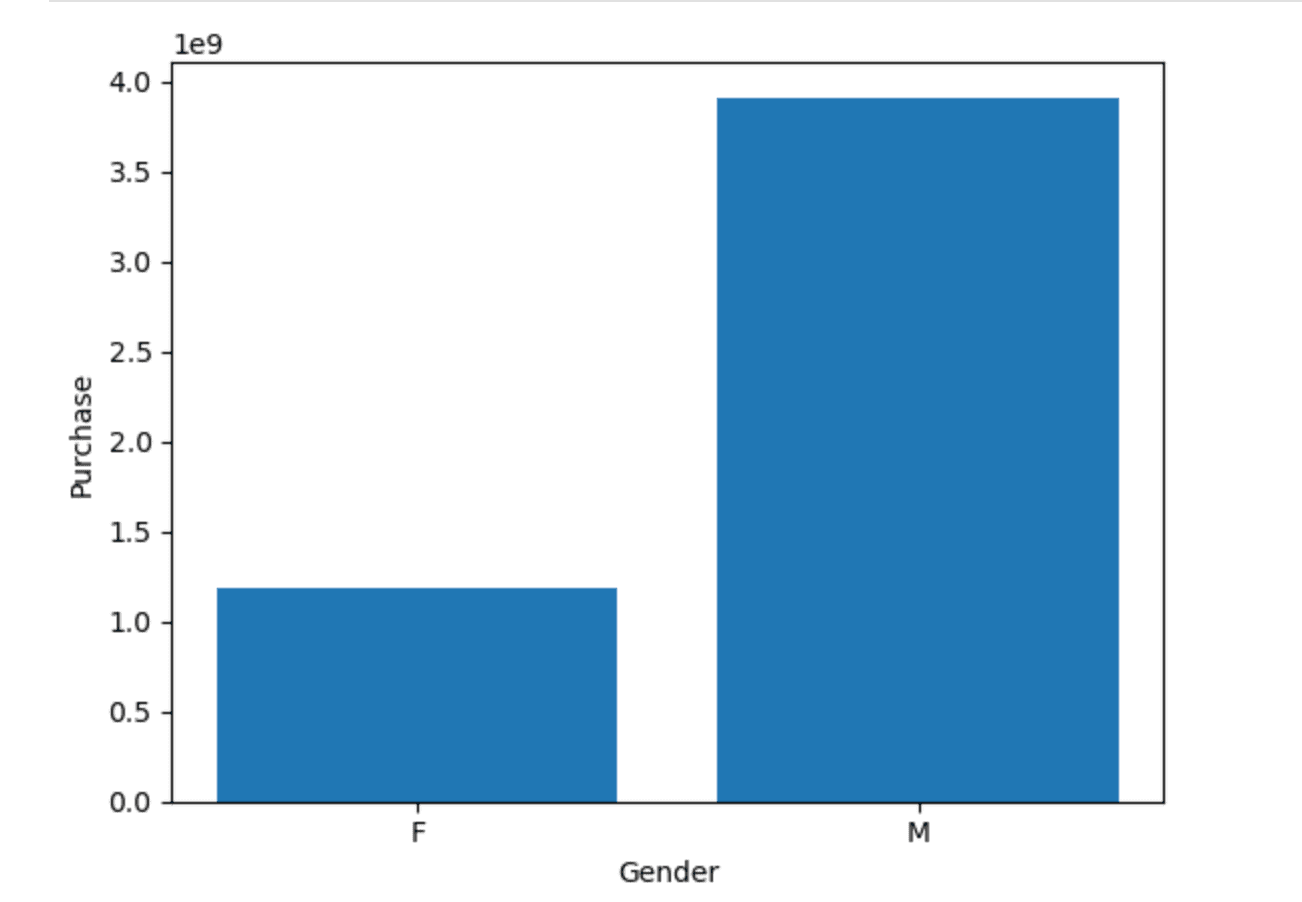
This class provides default scalar values for x_column, y_column, and plot_type so that the user can make minimal changes per his requirements to get a quick and helpful visualization.
3. Avoid Side Effects
Similarly, we can define a class for machine learning where __init__ is defined to initialize parameters related to the model, and actual training is defined in another function. This way, the training is not carried out as soon as the class is created, which might cause a resource burn.
Here is the code.
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import mean_squared_error
class PurchasePredictor:
def __init__(self, data):
self.data = data
self.model = LinearRegression()
def preprocess_data(self):
# Encode categorical variables into numerical values
label_encoder = LabelEncoder()
# Encoding 'Gender', 'Age', and 'City_Category' as they are categorical
self.data['Gender'] = label_encoder.fit_transform(self.data['Gender'])
self.data['Age'] = label_encoder.fit_transform(self.data['Age'])
self.data['City_Category'] = label_encoder.fit_transform(self.data['City_Category'])
X = self.data[['Gender', 'Age', 'Occupation', 'Marital_Status']]
y = self.data['Purchase']
return train_test_split(X, y, test_size=0.3, random_state=42)
def train_model(self, X_train, y_train):
self.model.fit(X_train, y_train)
def evaluate_model(self, X_test, y_test):
# Predict the values for the test set
y_pred = self.model.predict(X_test)
# Calculate the Mean Squared Error (MSE) to evaluate the model
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse}")
# Display some predicted vs actual values for a quick comparison
for i in range(5): # Print first 5 predictions
print(f"Predicted: {y_pred[i]:.2f}, Actual: {y_test.iloc[i]}")
# Initialize PurchasePredictor with the loaded data
predictor = PurchasePredictor(walmart_loader.data)
# Preprocess the data
X_train, X_test, y_train, y_test = predictor.preprocess_data()
# Train the model
predictor.train_model(X_train, y_train)
# Evaluate the model
predictor.evaluate_model(X_test, y_test)
Here is the output.

In this case, the model initialization is made in the __init__ method, and the actual training in scope during fit to avoid performance-heavy operations when executing __init__.
4. Document Parameter Expectations
If you use complex datasets, making it clear in your __init__ method how the parameters are expected can save you and others an hour's worth of debugging. Here is an example of working with the Black Friday dataset using Data exploration.
Here is the code.
class DataExplorer:
"""
A class for exploring customer data.
Parameters:
data (pd.DataFrame): The customer transactional dataset.
"""
def __init__(self, data):
self.data = data
def describe_data(self):
return self.data.describe()
explorer = DataExplorer(walmart_loader.data)
explorer.describe_data()
Here is the output.
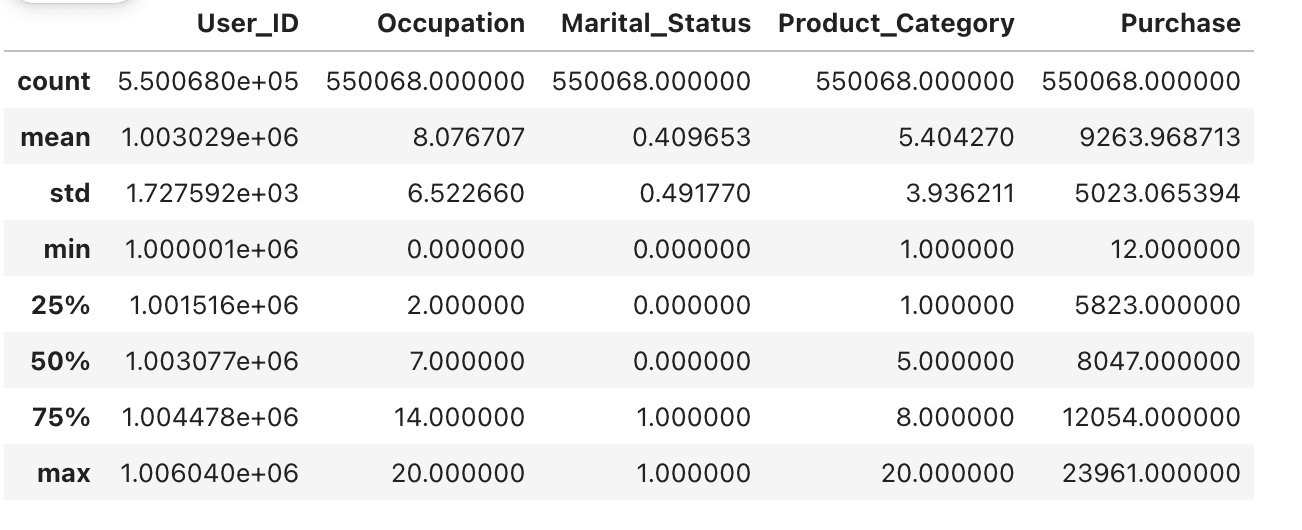
This class is well-documented and clearly outlines what users should expect of the __init__ method and the data it will take.
5. Avoid Using Too Many Parameters
In the scope of datasets like this (Black Friday dataset), passing a lot of attributes directly to the __init__ method can make your code less elegant/maintainable and more complicated to use. You can then group related attributes into smaller classes, which helps make the initialization process cleaner and more organized.
This is how you can handle it:
Here is the code.
import pandas as pd
# Load Black Friday dataset
data = pd.read_csv("walmart_data.csv")
# Define a class for customer demographic information
class Demographics:
def __init__(self, gender, age, occupation, city_category):
self.gender = gender
self.age = age
self.occupation = occupation
self.city_category = city_category
# Define a class for purchase-related details
class PurchaseDetails:
def __init__(self, purchase_amount, product_id):
self.purchase_amount = purchase_amount
self.product_id = product_id
# Define the main Customer class
class Customer:
def __init__(self, customer_id, demographics, purchase_details):
self.customer_id = customer_id
self.demographics = demographics
self.purchase_details = purchase_details
def __str__(self):
return f"Customer {self.customer_id}: {self.demographics.gender}, {self.demographics.age} years old, purchased {self.purchase_details.product_id}."
# Instantiate the Demographics and PurchaseDetails objects
demographics = Demographics(gender="Male", age="26-35", occupation=7, city_category="B")
purchase_details = PurchaseDetails(purchase_amount=12000, product_id="P001")
# Create a Customer instance
customer = Customer(customer_id="C1234", demographics=demographics, purchase_details=purchase_details)
# Print customer details
print(customer)
Here is the output.
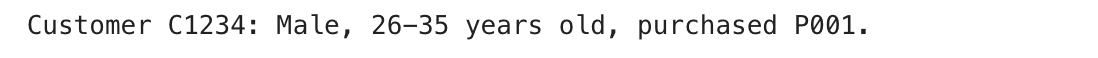
This is what happens in the above code. Instead of passing everything (gender, age, occupation, purchase_amount, and product_id) straight through the __init__ method of our Customer class, we put related attributes into smaller classes: Demographics and PurchaseDetails.
This keeps the number of parameters down a bit and makes your code more maintainable and modular. By doing so:
- The Demographics class includes all the demographic information specific to a customer, including gender, age, and occupation.
- This PurchaseDetails class stores purchase data like purchase_amount and product_id.
- The Customer class then takes these grouped objects and lowers the number of parameters it has to deal with directly.
It cleans up the __init__ method and provides an easy way to handle changes in attributes later. If we ever need to add more data about a customer, we just extend this individual class without cluttering up the Customer class.
Here’s the practical guide if you want to know more about Python class methods.
Conclusion
We examined the meaning of the __init__ method in Python and discussed its importance for instantiating objects. We also went through a couple of good practices, especially if you are going to work on the dataset from data science.
By keeping your __init__ methods concise and organizing parameters in meaningful ways, each practice ensures that your code stays readable and manageable as it scales.
When used consistently, these practices can significantly improve your overall Python development experience and give you much more control when developing a large project.
Share