Understanding SQL's INTERSECT Command


Categories:
 Written by:
Written by:Nathan Rosidi
What is INTERSECT in SQL? How does it work? When to use it? How to write an INTERSECT query? You can find all these questions answered in this article.
The diversity of SQL’s set of commands is widely celebrated, as it offers so many possibilities to SQL users. However, there’s one drawback: some operators get unjustly talked about less and neglected.
One such operator is INTERSECT. I will use this article to try and right this wrong.
What Is an INTERSECT Operator in SQL?
The INTERSECT in SQL is one of the four set operators in SQL. The other three are:
- UNION
- UNION ALL
- EXCEPT
(INTERSECT ALL can sometimes be added to this list, but more on that later.)
The set operators combine the outputs of two or more queries into one result. SQL INTERSECT does that by finding common data between the query outputs. In other words, it returns an intersection of data. It inherently removes duplicates.
It comes in handy when you want to identify overlapping data between multiple tables or queries.
Some database systems also support INTERSECT ALL. It does the same thing as INTERSECT, only it doesn’t remove duplicates.
Syntax of INTERSECT Operator in SQL
The basic syntax of SQL INTERSECT is quite simple.
SELECT column_1,
column_2
FROM table_1
INTERSECT
SELECT column_1,
column_2
FROM table_2;
If you want to collate more datasets, simply write the INTERSECT keyword between each SELECT statement. Or use INTERSECT ALL if you want to include duplicates.
How SQL INTERSECT Works
Like other set operators, INTERSECT compares the results of two or more SELECT statements.
For it to work, there are two important rules you must follow.
- The number of columns must be the same in every SELECT.
- The columns across the SELECT statements must be the same data type. Explained differently, column_1 in the first SELECT must be the same data type as column_1 in the second SELECT. This is logical as the columns will be vertically merged into one dataset.
Let me show you an example of how INTERSECT works. We have two tables: employees and ex_employees. We want to find the employees’ IDs and names that are in both tables so we can inspect the data.
The GIF below shows how this works.


Use Cases and Examples
As you already learned, INTERSECT is used to output the intersection of data between two or more queries. This has many practical applications in business, so let’s look at them.
SQL INTERSECT Example #1: Submission Types
The question by MetLife, Credit Acceptance, and Credit Karma wants you to find the user ID of all users that have created at least one ‘Refinance’ submission and at least one ‘InSchool’ submission.
Last Updated: January 2021
Write a query that returns the user ID of all users that have created at least one ‘Refinance’ submission and at least one ‘InSchool’ submission.
Link to the question: https://platform.stratascratch.com/coding/2002-submission-types
Dataset
In this example, you will work with only one table, namely loans. It contains information about loans, such as user ID, date of creation, loan status, and loan type.
Solution & Output
You can now apply what you learned when I explained how SQL INTERSECT works. It’s not much different from this example. Write the first SELECT, which will show user IDs. Additionally, filter data so it shows only those IDs whose loan is categorized as ‘Refinance’.
Write the second SELECT that does the same, only for the ‘InSchool’ category, and separate the two queries with INTERSECT.
SELECT user_id
FROM loans
WHERE type = 'Refinance'
INTERSECT
SELECT user_id
FROM loans
WHERE type = 'InSchool';
The output shows there’s only one user who has loans in both categories.
SQL INTERSECT Example #2: Price Of Wines In Each Country
This question by Wine Magazine asks you to find the minimum, average, and maximum price of the wines per country. However, I’ll change the requirements a bit. Yes, I’ll still output the country name along with the corresponding minimum, maximum, and average prices. But, I want to include in the calculation only wines that are found in both tables of the dataset. We will define that the wines are the same if they come from the same country and have the same price.
Last Updated: February 2020
Find the minimum, average, and maximum price of all wines per country. Assume all wines listed across both datasets are unique. Output the country name along with the corresponding minimum, maximum, and average prices.
Link to the question: https://platform.stratascratch.com/coding/10029-price-of-wines-in-each-country
Dataset
The question provides you with the tables winemag_p1 and winemag_p2. They both hold various info about the wines.
Solution & Output
The official solution uses UNION ALL. However, since I modified the question, I’ll use INTERSECT instead.
Let me first write the subquery part and then build the solution from there. So, the subquery part consists of two SELECT statements with INTERSECT. I use it to get the countries and prices from both tables. This way, I get only the wines that can be found in both tables.
I also convert the price values to decimal numbers. This is because I’ll use them in aggregations later. While it makes no difference with the MIN() and MAX() functions, it does with AVG() as it sums the values and divides them with the number of occurrences.
Additionally, I want to remove all the records with no price, as I don’t want to consider all NULLs as one wine. This is to build a robust code that considers the edge case where the price is NULL. (I know for a fact that there are some rows without a price.)
SELECT country,
price::NUMERIC
FROM winemag_p1
WHERE price IS NOT NULL
INTERSECT
SELECT country,
price::NUMERIC
FROM winemag_p2
WHERE price IS NOT NULL;
This is now a list of countries and prices of wines that can be found in both tables.
Now, I’ll use this result in the main query. I select the country from the subquery part and then calculate the minimum, average, and maximum wine price.
We use WHERE to exclude the countries whose names are missing. This is not necessary with our dataset, but again, let’s build a robust query that will survive edge cases.
As a final step, I group the output by country to get all the calculations for each country separately.
SELECT country,
MIN(price) AS min_price,
AVG(price) AS avg_price,
MAX(price) AS max_price
FROM
(SELECT country,
price::NUMERIC
FROM winemag_p1
WHERE price IS NOT NULL
INTERSECT
SELECT country,
price::NUMERIC
FROM winemag_p2
WHERE price IS NOT NULL) tmp
WHERE country <> ''
GROUP BY country;
The code gives us five countries and the minimum, average, and maximum prices for the wines from both tables.
SQL INTERSECT Example #3: Find the List of Intersections Between Both Word Lists
The question by Google asks you to find the list of intersections between both word lists. The wording here is quite straightforward: it mentions the list of intersections, so it’s an obvious clue we should use INTERSECT.
Find the list of intersections between both word lists.
Link to the question: https://platform.stratascratch.com/coding/9816-find-the-list-of-intersections-between-both-word-lists
Dataset
There’s only one table in this question: google_word_lists. It gives you a list of words separated by a comma in both words1 and words2 columns.
Solution & Output
The most complicated part is not INTERSECT, but how to turn the list of words from each column into one word per row. Luckily, there are two functions in PostgreSQL you can combine to do that.
First, use the STRING_TO_ARRAY() function that does the obvious: turns the string values into an array. You specify the column word1 and the separator (a comma in this case) in the function.
Second, embed this function in the UNNEST() function. It’s a function used to explode the array into a set of rows.
Then, use INTERSECT and repeat all the steps above, but this time for column words2.
SELECT UNNEST(STRING_TO_ARRAY(words1, ',')) AS word
FROM google_word_lists
INTERSECT
SELECT UNNEST(STRING_TO_ARRAY(words2, ',')) AS word
FROM google_word_lists;
The output shows all the words that can be found in both columns of the provided table.
Differences Between INTERSECT and Other SQL Operations
Sometimes, it can be difficult for beginners to discern the difference between INTERSECT, other set operators, and JOINs in SQL.
Let me talk about those differences and show you the examples.
INTERSECT vs. UNION ALL
While INTERSECT finds the common data from two or more SELECT statements, UNION ALL the queries’ result sets, including duplicates. In other words, it just merges all the data vertically.
Let’s go back to the first INTERSECT example. This is a code we used to output the loan submission types.
SELECT user_id
FROM loans
WHERE type = 'Refinance'
INTERSECT
SELECT user_id
FROM loans
WHERE type = 'InSchool';
The code returns only one user whose loan submissions belong to both the ‘Refinance’ and ‘InSchool’ categories.
Now, if I wanted to rewrite this code using UNION ALL, this is how it would look.
SELECT user_id
FROM loans
WHERE type = 'Refinance'
UNION ALL
SELECT user_id
FROM loans
WHERE type = 'InSchool';
The output shows ID 108 from the INTERSECT query and all other IDs, including duplicates.
INTERSECT vs. UNION
The UNION set operator does the same thing as UNION ALL; only it excludes duplicates.
So, again, I can rework the query by using UNION.
SELECT user_id
FROM loans
WHERE type = 'Refinance'
UNION
SELECT user_id
FROM loans
WHERE type = 'InSchool';
The output shows the ID 108 – like the INTERSECT query – and all other IDs, like UNION ALL, but without duplicate values.
INTERSECT vs. EXCEPT
EXCEPT is the opposite version of INTERSECT. Whereas INTERSECT returns the common data between the query outputs, EXCEPT returns only data from the first data set that does not exist in the second dataset.
If we rework the previous queries this way
SELECT user_id
FROM loans
WHERE type = 'Refinance'
EXCEPT
SELECT user_id
FROM loans
WHERE type = 'InSchool';
it will output all the users with the ‘Refinance’ loan submissions that don’t have the ‘InSchool’ submissions.
INTERSECT vs. JOINs
INTERSECT finds common rows in query outputs and combines data vertically. On the other hand, JOIN operations combine rows and columns from two or more tables and stack data horizontally.
The INTERSECT solution to the submission types of interview questions can be rewritten this way.
I gave the loans table two different aliases (l_1 and l_2) so I can join the table with itself. The tables are joined on the common column, which is user_id.
I’m looking for the distinct user_id, so I’ll remove duplicates using the DISTINCT keyword.
Also, I’ll set the conditions regarding the submission types in the WHERE clause.
SELECT DISTINCT l_1.user_id
FROM loans l_1
INNER JOIN loans l_2 ON l_1.user_id = l_2.user_id
WHERE l_1.type = 'Refinance' AND l_2.type = 'InSchool';
The output is the same as with INTERSECT. In other words, the interview question can be solved using INNER JOIN instead of INTERSECT.
Tips for Optimizing Queries That Use INTERSECT
While SQL INTERSECT is a very helpful tool, you should also have in mind that optimizing the queries that use it might be crucial for getting the best from it.
Here are some tips on how to do this.


1. Indexing: Ensure that the columns used in INTERSECT are indexed. This is particularly important for columns that are part of the WHERE clause in the individual SELECT statements. Indexes can significantly speed up the process of finding and intersecting rows.
2. Limit Columns in SELECT Statements: Try to limit the number of columns in the SELECT statements that are part of the INTERSECT. The more columns you include, the more work the database has to do to compare each row. If possible, only include the columns that are absolutely necessary for the intersection.
3. Simplify Conditions: Simplify the conditions in the WHERE clause as much as possible. Complex conditions can slow down the query. If you have complex filters, consider whether they can be simplified or if some can be applied after the INTERSECT operation.
4. Use Subqueries Effectively: If your INTERSECT query involves large tables, it might be beneficial to use subqueries first to reduce the dataset size on which INTERSECT operates. By filtering the data in each table to a smaller subset, the INTERSECT will have less data to process.
5. Consider INTERSECT Alternatives: In some cases, alternative SQL constructs like INNER JOIN, EXISTS, or even temporary tables might perform better than INTERSECT, depending on the specific database system and the data involved. Testing different approaches can help identify the most efficient one.
6. Optimize Individual Queries: Ensure each query used in the INTERSECT is optimized individually. This includes using efficient joins, avoiding unnecessary columns, and applying filters early.
7. Analyze Execution Plans: Use your database system's query execution plan tool to understand how your query is being executed. The execution plan provides insights into how indexes are used, how joins are performed, and where potential bottlenecks lie.
8. Database-Specific Features: Different databases may have specific optimizations or settings that can impact the performance of INTERSECT queries. Check your database's documentation for any such features or recommendations.
9. Keep Statistics Updated: Ensure that the database statistics are up to date. Database query optimizers rely on statistics to choose the best execution plan. Outdated statistics can lead to suboptimal query plans.
10. Reduce Dataset Size: If possible, reduce the size of the datasets being intersected by filtering out unnecessary rows early in the process.
Limitations or Special Considerations When Using INTERSECT in SQL
Some of its limitations might thwart your plans of using INTERSECT in SQL.


1. Column Matching: The SELECT statements involved in INTERSECT must have the same number of columns, and the corresponding columns must have compatible data types. This requirement can sometimes limit the flexibility of using INTERSECT, especially when dealing with tables of different structures.
2. Performance Implications: INTERSECT can be less efficient than other methods, like INNER JOIN or EXISTS, especially with large datasets. The database must process the entire result set of each query involved before the intersection can occur, which can be resource-intensive.
3. Order and Sorting: The order of the rows in the result set of an INTERSECT operation is not guaranteed unless an ORDER BY clause is used. Additionally, applying ORDER BY to large result sets can further impact query performance.
4. Distinct Results: The INTERSECT operator inherently returns distinct rows (similar to SELECT DISTINCT). This means it automatically removes duplicates within each result set before performing the intersection. This behavior is useful for some queries but can be a limitation if you need to consider duplicate rows in your analysis.
5. NULL Handling: In SQL, INTERSECT treats NULL values as equal when comparing columns. This means that two NULL values are considered a match, which might not always be the intended behavior in certain contexts.
6. Combining With Other Operations: When using INTERSECT in conjunction with other set operators like UNION or EXCEPT, it's important to understand the precedence and how these operations are evaluated to ensure the correct results are obtained. Parentheses can be used to define the order explicitly.
7. No Additional Conditions: Unlike JOIN operations, INTERSECT does not allow for specifying additional join conditions. It strictly compares the result sets for identical rows.
8. Subquery Considerations: When using INTERSECT with subqueries, especially correlated subqueries, it's important to be mindful of the potential for increased query complexity and decreased performance.
9. Use in Complex Queries: In more complex queries, especially those involving multiple set operations or subqueries, INTERSECT can make the query harder to read and understand, which can impact maintainability.
Differences in How INTERSECT Is Implemented Across Various SQL Database Systems
Most popular database systems support INTERSECT.

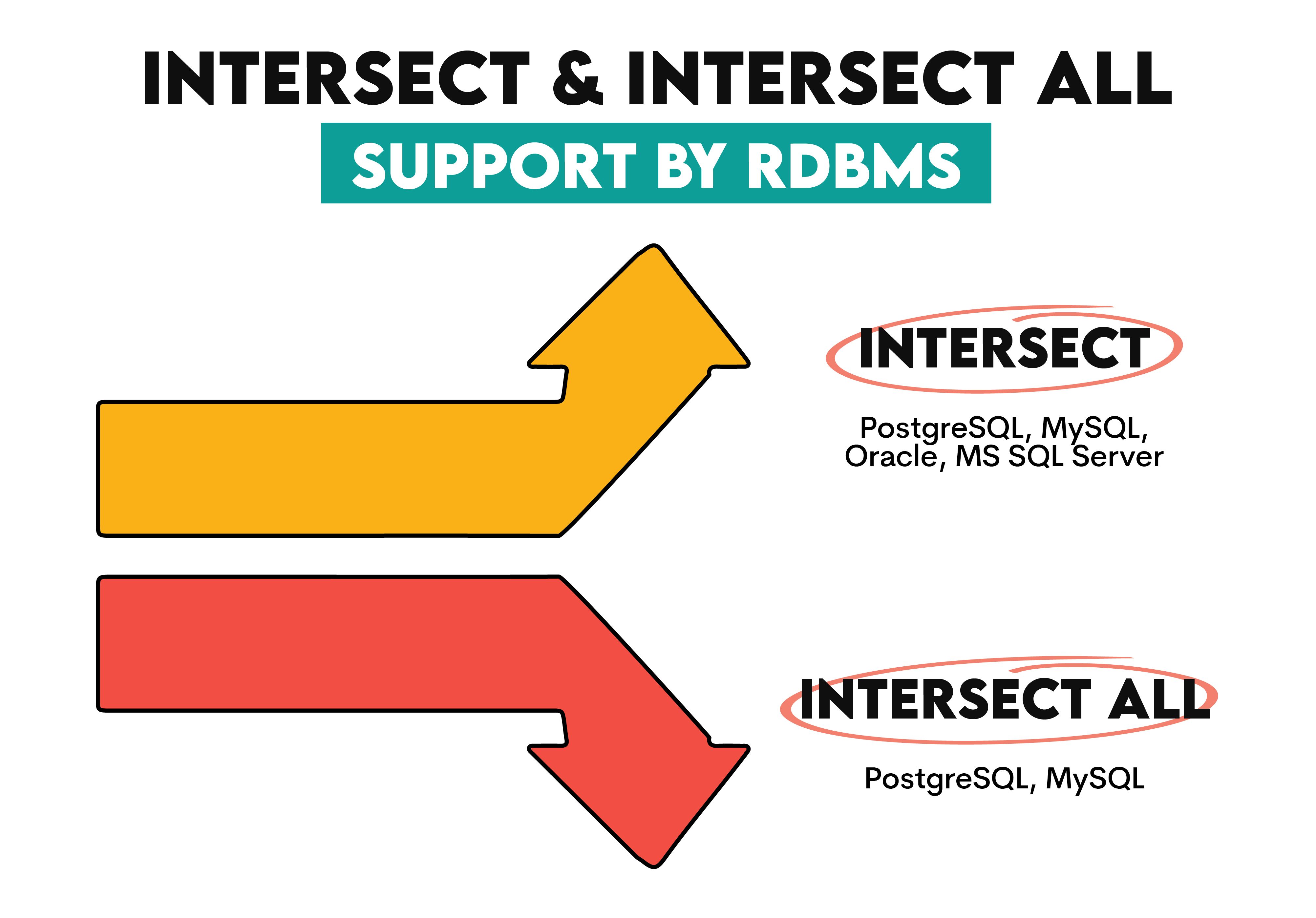
However, there might be differences in how they are implemented and executed.
- PostgreSQL: Fully supports INTERSECT. Its query planner evaluates the most efficient way to execute these queries, which may include different types of join algorithms. PostgreSQL also supports INTERSECT ALL, in case you want to include duplicate rows in your output. Here's the official documentation.
- MySQL: It does support INTERSECT, even though it wasn’t supported for a long time. It was only introduced with the 8.0. 31 release. Same as PostgreSQL, you can use INTERSECT ALL, too. Here’s the official documentation.
- Oracle: Also fully supports INTERSECT, but not INTERSECT ALL. Oracle's optimizer can utilize various strategies to execute INTERSECT queries, such as hash or sort-based approaches, depending on the specific query and data involved. Here's the official documentation.
- MS SQL Server: This database also supports INTERSECT, but not INTERSECT ALL. It performs well in scenarios where the result sets being intersected are large, as it typically employs efficient algorithms for set operations. SQL Server's execution plan may use methods like hashing or sorting to process INTERSECT queries. Here's the official documentation.
Summary
SQL INTERSECT can be a handy tool in your work with data. Of course, you need to know how to use it, when, and when not to use it.
I covered all that in this article, with also several coding examples that can lead you even deeper into practicalities.
In some situations, you can also use INTERSECT alternatives. Again, it’s essential to know how they work and when to use them. All these commands, including INTERSECT, are crucial components of your becoming an advanced SQL user.
To achieve this and get very fluent in SQL, you should write plenty of code. You won’t lack the opportunities for that at StrataScratch, as there are 1,000+ real coding interview questions you can use for practice. And our blog is a rich resource for almost any SQL topic and concept, which is also helpful when solving SQL interview questions.
Share


