SQL UNION vs UNION ALL: Differences You Need to Know

Categories:
 Written by:
Written by:Irakli Tchigladze
In this article, we’ll discuss differences and similarities between UNION vs UNION ALL, possible use cases, and compare the performance of two set operators.
There are various ways to combine data from different sources in SQL. JOINs combine data horizontally by increasing the number of columns.
Set operators like UNION and UNION ALL allow you to combine datasets vertically. They don’t change the number of columns but stack records from multiple datasets in one table.
In this article, we will explain the differences between two set operators - UNION vs UNION ALL. We’ll go over their syntax and show how to best use these SQL features. Finally, we’ll walk you through answers to actual interview questions that involve UNION and UNION ALL.
We will also refresh your memory on two set operators. The set operators section in our SQL Cheat Sheet is quite informative as well.
What is UNION?
UNION is a set operator. It is used to vertically combine multiple datasets by stacking them on top of one another.
One important feature of UNION is that it removes duplicate rows from the combined data. If you want to ensure that combined datasets don't have duplicate records, use UNION.
UNION removes duplicate rows, not duplicate values. If a row has 5 columns, all 5 values must be the same for UNION to remove that row.
What is UNION ALL?
It is a set operator that combines two datasets by stacking them on top of one another without checking if each record is unique or not.
UNION ALL is useful when:
- You’re sure that datasets you are combining don’t have duplicate rows
- Keeping duplicate records is necessary for the task at hand.
As a rule of thumb, UNION ALL is useful for creating copies of a certain dataset.
Later in this “UNION vs UNION ALL” guide, we’ll walk you through two answers to interview questions. One of them asks you to return two copies of a certain dataset, so it’s a good question to demonstrate the usefulness of UNION ALL.
UNION vs UNION ALL in SQL - Differences and Similarities
The image below gives an overview of the differences and similarities between UNION and UNION ALL.
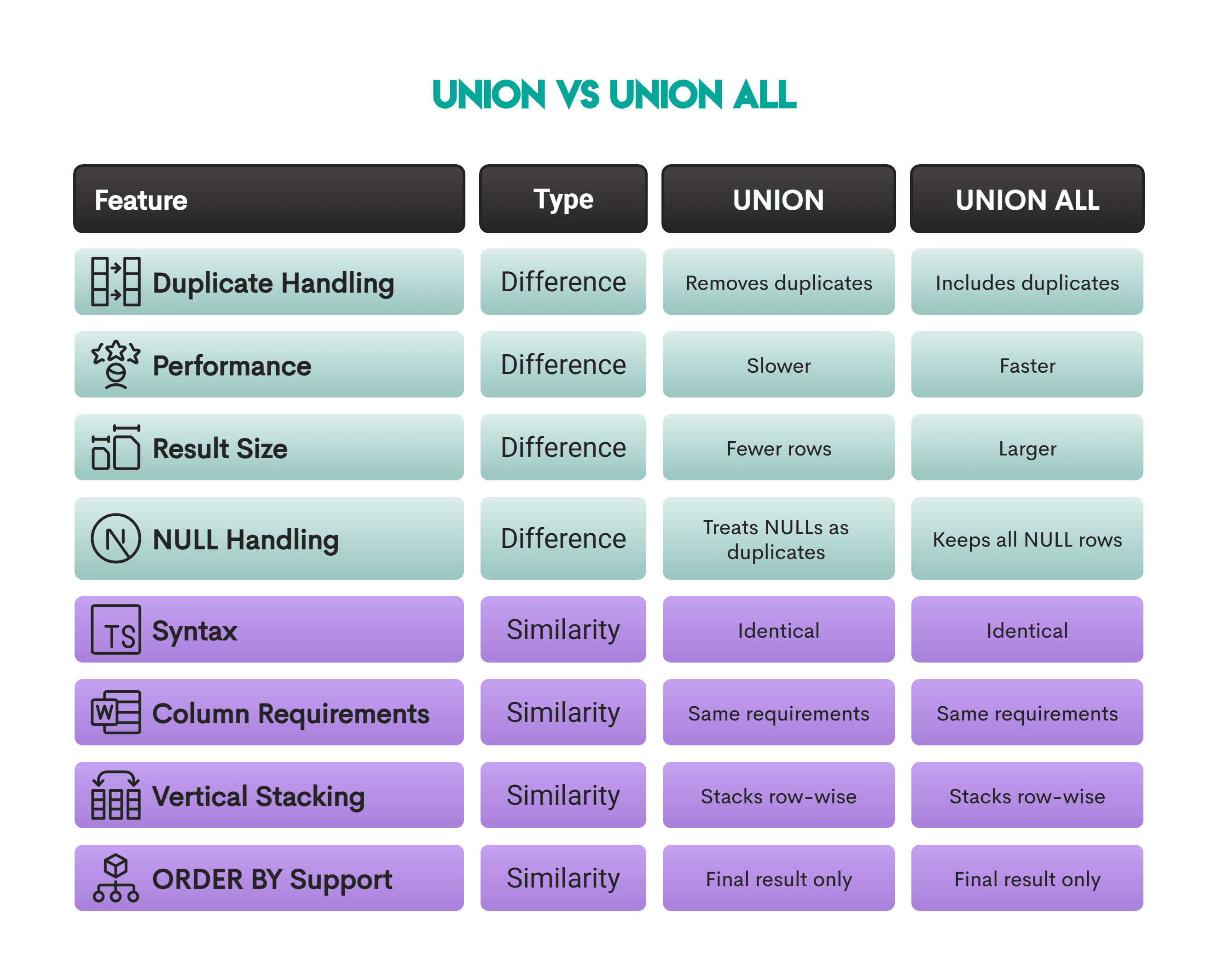
Let’s now talk a bit more about each difference and similarity.
Differences
Handling duplicates: The main difference between UNION vs UNION ALL is their approach to duplicate rows. After UNION combines datasets, it also checks for duplicate records and removes them. UNION ALL only combines them and stops there.
Performance: Because UNION takes the extra step of removing duplicate values, generally, it is considered slower than UNION ALL, but that’s not always the case. We’ll compare their performance in a later section.
Result size: As UNION ALL keeps the duplicates, it typically produces larger datasets than UNION.
NULL handling: The UNION operator treats NULLs as duplicates, meaning it removes them if all column values (including NULL) match. On the other hand, UNION ALL keeps all rows with NULLs, even if they appear identical.
Similarities
Syntax: UNION and UNION ALL basically have the identical syntax. The only difference is that you write the keyword UNION in the first case. In the second case, the keyword is – well, obviously – UNION ALL.
Column requirements: UNION and UNION ALL operations also follow the same rules - for datasets to be combined, they must have the same type, number, and order of columns.
Vertical stacking: The previous similarity is also because of the way UNION and UNION ALL combine. They both do it by vertically stacking datasets on top of one another. Unlike JOINs, merging two datasets doesn’t increase the number of columns, but the number of rows.
ORDER BY support: If you use ORDER BY in the query with either UNION or UNION ALL, it must be placed at the end of the combined query, and it sorts the final merged result set.
SQL UNION vs UNION ALL: Syntax
Let’s go over the syntax rules for UNION and UNION ALL.
Basics
Minimum number of datasets is two, with a set operator (UNION or UNION ALL) placed between them.
SELECT *
FROM sales
UNION ALL
SELECT *
FROM orders;Note that both datasets must SELECT the same number, type, and order of columns, or it will throw an SQL error.
Set operators to combine identical datasets
In the previous example, we SELECT data from two different tables. Datasets can be identical as well.
In this example, we combine two identical SELECT statements.
SELECT *
FROM sales
UNION ALL
SELECT *
FROM sales;As a result, we’ll have two copies of the same data from one table.
Set operators to combine two complex queries
Datasets you combine can be as simple as a pair of SELECT/FROM statements or very complex. It’s okay to filter, group, or aggregate data from the source table, as long as two datasets have the right number, type, and order of columns.
Let’s look at an example where we combine two filtered datasets with a WHERE clause.
SELECT *
FROM domestic_sales
WHERE total_revenue > 100
UNION ALL
SELECT *
FROM international_sales
WHERE total_revenue > 300;Column names
Two datasets don’t need to have the same column names to be combined.
As long as it’s the correct number, type, and logical order of columns, names from the first query don’t have to match those of the second one.
SELECT total_revenue,
units_sold
FROM domestic_sales
UNION ALL
SELECT aggregate_revenue,
pcs_ordered
FROM international_sales;
As you can see, both datasets have the same number of columns.
For two datasets to be successfully combined, total_revenue and aggregate_revenue columns need to have the same type (or implicitly convertible) values. The same applies to units_sold and pcs_ordered columns.
The combined dataset will have column names of the first query - total_revenue and units_sold.
You can specify column names for the final table using the AS keyword.
SELECT total_revenue AS total,
units_sold AS sold
FROM domestic_sales
UNION ALL
SELECT aggregate_revenue,
pcs_ordered
FROM international_sales;
Logical order of columns
When using UNION to combine datasets vertically, mixing up the logical order of columns can skew final data.
For example, let’s imagine you have three columns, labeled: thousands, hundreds, and tens. Each record is supposed to describe a number like 1560, where thousands is 1, hundreds is 5, and tens is 6.
Let’s look at this example:
SELECT thousands,
hundreds,
tens
FROM table
UNION ALL
SELECT tens,
thousands,
hundreds
FROM table;In this case, UNION itself won’t throw an error because you have three columns of integer type.
However, tens values from the second dataset will be aligned with thousands values from the first. Other columns will be misaligned as well, which can seriously disrupt accuracy of your data.
SQL UNION vs UNION ALL: In Practice

In this “UNION vs UNION ALL” guide, we’ll continue the StrataScratch blog tradition of breaking down SQL Interview Questions to help you understand various SQL features.
Let’s review two interview questions where UNION and UNION ALL play an integral role in finding a solution.
UNION question: Wine Variety Revenues
In this interview question from Wine Magazine, candidates have to work with sales data to find total sales for each region.
Wine Variety Revenues
Last Updated: February 2020
You have a dataset containing information about wines, including their regions, varieties, and prices. Some wines have two regions listed (region_1 and region_2). Calculate the total cost of wines for each combination of region and variety, using both region columns.
Because there are two regions listed, first combine the data from both region columns, making sure to remove any duplicate entries and excluding any records with missing prices or regions. Then, sum the prices for each unique combination of region and variety and present the results, showing the region, variety, and total price. Order the final result from the highest total price to the lowest.
Link to the question: https://platform.stratascratch.com/coding/10033-wine-variety-revenues
Understand the question
This question can be confusing, especially after looking at the table.
The important takeaway is that we need to aggregate wine revenue for each region. Every record in the winemag_p1 table has two region columns.
We’ll need to create two datasets, each consisting of region, price and variety values. We will be aggregating total revenue for each region, so we need to avoid counting the same sales record more than once. We need to find and remove duplicate records in the table. This is why we need to use UNION instead of UNION ALL.
Analyze data
To solve this question, candidates need to work with the winemag_p1 table.
This table contains information about wine sales in two regions. We’ll need to separate records so that there is just one region value in each record.
The table has many columns. At this point, we can only make assumptions:
- id identifies each sale
- country, region, province, winery values probably represent the origin of the wine.
- description, designation columns give us broad information about the wine.
- points values are probably used for wine ranking at Wine Magazine
- price most likely represents the price of each unit. Most likely, we’ll have to aggregate values in this column to get the total revenue per region.
- region_1 and region_2 specify the region of the wine. We’ll have to generate datasets with the region, price, variety values for both regions.
- variety column specifies the type of wine.
Looking at the available data, you might notice that some records don’t have either region_1 or region_2 values, and some are missing price values as well. Since we are aggregating price values for each region, records without region and price values will need to be filtered out.
Plan your approach
As you can see, each record contains information about wine sales in two regions. We’ll use the available data to create two separate datasets, one for each region.
Because both datasets are sourced from the same table, some records might be duplicates.
We obviously need UNION, not UNION ALL, for this task. Because it allows us to:
- Merge two datasets into one to prepare it for aggregation
- Automatically remove identical records
Next, we need to filter. As you can see, some records in the winemag_p1 table are missing region_1, region_2, and price values. We can use the WHERE clause to make sure the combined table doesn’t have any records with empty values.
Finally, we’ll have to use the SQL GROUP BY statement and SUM() aggregate function to find the aggregate revenue for each region.
Write the code
1. UNION two datasets
Each record in the winemag_p1 table contains information about two regions.
We need to use the SELECT statement to create two datasets, one for each region. For the first dataset, we’ll SELECT values from region_1, variety, and price. For the second dataset - region_2, variety, price.
Next, we need to merge two datasets again, but this time we’ll stack them on top of one another.
We’ll aggregate combined data to find total revenue by region. So we don’t want to count each record more than once. We need to remove duplicates. That’s why we use UNION, which will vertically combine two datasets and remove any rows where all three values are the same.
SELECT region_1 AS region,
variety,
price
FROM winemag_p1
UNION
SELECT region_2 AS region,
variety,
price
FROM winemag_p1
2. Filter table
Looking at the initial table, we can see that some rows have empty region_1, region_2, or price columns. Our datasets will be based on this table, so some of the records in the combined table will be empty as well.
| region | variety | price |
|---|---|---|
| Assyrtiko | 20 | |
| Pinot Noir | 294 | |
| Champagne Blend | 50 | |
| Brunello di Montalcino | Sangiovese | 63 |
| Columbia Valley (WA) | Merlot | 23 |
We need WITH and AS keywords to save and reference the combined table as CTE.
Finally, we pair SELECT with the WHERE clause to filter out records where region and price values are NULL.
WITH CTE AS(
SELECT region_1 AS region,
variety,
price
FROM winemag_p1
UNION
SELECT region_2 AS region,
variety,
price
FROM winemag_p1
)
SELECT region,
variety,
price
FROM CTE
WHERE region IS NOT NULL AND price IS NOT NULL| region | variety | price |
|---|---|---|
| Brunello di Montalcino | Sangiovese | 63 |
| Columbia Valley (WA) | Merlot | 23 |
| Mendoza | Malbec-Syrah | 12 |
| Mazis-Chambertin | Pinot Noir | 294 |
| Sonoma | Zinfandel | 26 |
3. Aggregate sales
We want to aggregate revenue from each type of wine in each region. The logical choice is to find an aggregate of price values.
WITH CTE AS(
SELECT region_1 AS region,
variety,
price
FROM winemag_p1
UNION
SELECT region_2 AS region,
variety,
price
FROM winemag_p1
)
SELECT region,
variety,
SUM(price) AS price_sum
FROM CTE
WHERE region IS NOT NULL AND price IS NOT NULL
GROUP BY region, variety
ORDER BY price_sum DESC;
We use the AS keyword to give the aggregated column a descriptive name, ‘sum’.
Finally, we’ll need a GROUP BY statement to create groups of rows so that SUM() is applied to each region, not the entire table.
Lastly, the question also tells us to order regions by highest total sales to lowest.
Output
Final output should display the total sales for each variety of wine from each region.
| region | variety | sum |
|---|---|---|
| Napa | Cabernet Sauvignon | 1630 |
| Napa Valley | Cabernet Sauvignon | 925 |
| Diamond Mountain District | Cabernet Sauvignon | 350 |
| Mazis-Chambertin | Pinot Noir | 294 |
| Napa Valley | Bordeaux-style Red Blend | 267 |
| Napa | Bordeaux-style Red Blend | 267 |
| Barbaresco | Nebbiolo | 242 |
| Oakville | Cabernet Sauvignon | 200 |
| Rao Negro Valley | Malbec | 177 |
| Central Coast | Pinot Noir | 168 |
| Brunello di Montalcino | Sangiovese | 113 |
| Washington Other | Cabernet Sauvignon | 100 |
| Napa | Red Blend | 100 |
| Rutherford | Red Blend | 100 |
| Washington | Cabernet Sauvignon | 100 |
| Russian River Valley | Pinot Noir | 97 |
| Sonoma | Pinot Noir | 97 |
| Paso Robles | Cabernet Sauvignon | 91 |
| Central Coast | Cabernet Sauvignon | 91 |
| Rutherford | Cabernet Sauvignon | 85 |
| Alexander Valley | Cabernet Sauvignon | 80 |
| Sonoma | Cabernet Sauvignon | 80 |
| Meursault | Chardonnay | 62 |
| Rioja | Tempranillo | 60 |
| Forla‚ | Sauvignon Blanc | 55 |
| Anderson Valley | Pinot Noir | 52 |
| Mendocino/Lake Counties | Pinot Noir | 52 |
| Champagne | Champagne Blend | 50 |
| Sta. Rita Hills | Pinot Noir | 48 |
| Mendoza | Malbec | 45 |
| Chalone | Pinot Noir | 44 |
| Chablis | Chardonnay | 42 |
| Long Island | Merlot | 40 |
| Sonoma County | Sauvignon Blanc | 40 |
| Sonoma Coast | Pinot Noir | 40 |
| Sonoma | Sauvignon Blanc | 40 |
| Franciacorta | Chardonnay | 39 |
| Columbia Valley | Syrah | 33 |
| Walla Walla Valley (WA) | Syrah | 33 |
| Virginia | Merlot | 32 |
| Columbia Valley | Cabernet Sauvignon | 30 |
| Edna Valley | Pinot Noir | 30 |
| Walla Walla Valley (WA) | Cabernet Sauvignon | 30 |
| Franciacorta | Sparkling Blend | 29 |
| San Luis Obispo County | Pinot Noir | 29 |
| Napa | Merlot | 27 |
| Rasteau | Rhone-style Red Blend | 27 |
| Napa Valley | Merlot | 27 |
| Shenandoah Valley (CA) | Sangiovese | 26 |
| Sierra Foothills | Sangiovese | 26 |
| Russian River Valley | Zinfandel | 26 |
| Sonoma | Zinfandel | 26 |
| Napa | Moscato | 25 |
| Napa Valley | Moscato | 25 |
| Pouilly-Fuisse | Chardonnay | 25 |
| Columbia Valley | Merlot | 23 |
| Columbia Valley (WA) | Merlot | 23 |
| Montsant | Red Blend | 22 |
| Ribera del Duero | Red Blend | 22 |
| The Hamptons, Long Island | Merlot | 22 |
| Valpolicella Classico | Corvina, Rondinella, Molinara | 22 |
| Willamette Valley | Riesling | 21 |
| Walla Walla Valley (WA) | Semillon | 20 |
| Columbia Valley | Semillon | 20 |
| Alexander Valley | Merlot | 19 |
| Sonoma | Merlot | 19 |
| Prosecco di Valdobbiadene | Prosecco | 19 |
| Soave Classico | Garganega | 18 |
| Luja?n de Cuyo | Malbec | 18 |
| North Fork of Long Island | Merlot | 18 |
| Conegliano Valdobbiadene | Glera | 18 |
| Carinena | Red Blend | 18 |
| California Other | Pinot Noir | 17 |
| Vin Mousseux | White Blend | 17 |
| California | Pinot Noir | 17 |
| Chianti Classico | Sangiovese | 15 |
| San Juan | Malbec | 12 |
| Mendoza | Malbec-Syrah | 12 |
| Sicilia | Nero d'Avola | 12 |
| Uco Valley | Viognier | 12 |
| South Eastern Australia | Chardonnay | 11 |
| Mendoza | Cabernet Sauvignon | 10 |
| Columbia Valley | Gewarztraminer | 9 |
| Columbia Valley (WA) | Gewarztraminer | 9 |
| Pays d'Oc | Merlot | 8 |
| California Other | Sauvignon Blanc | 8 |
| California | Sauvignon Blanc | 8 |
Output when we use UNION ALL instead of UNION
Let’s use UNION ALL instead of UNION to understand the difference between the two.
WITH CTE AS(
SELECT region_1 AS region,
variety,
price
FROM winemag_p1
UNION ALL
SELECT region_2 AS region,
variety,
price
FROM winemag_p1
)
SELECT region,
variety,
SUM(price) AS price_sum
FROM CTE
WHERE region IS NOT NULL AND price IS NOT NULL
GROUP BY region, variety
ORDER BY price_sum DESC;| region | variety | price_sum |
|---|---|---|
| Napa | Cabernet Sauvignon | 1630 |
| Napa Valley | Cabernet Sauvignon | 925 |
| Diamond Mountain District | Cabernet Sauvignon | 350 |
| Mazis-Chambertin | Pinot Noir | 294 |
| Napa Valley | Bordeaux-style Red Blend | 267 |
UNION ALL does not remove duplicates, so it produces a lot more records, which might result in inaccurate aggregate values.
UNION ALL question: HR department employee
In this Amazon interview question, candidates are explicitly asked to return duplicate results. It’s an interesting use case for UNION ALL.
Duplicate HR Department Employees
Generate a list of employees who work in the HR department, including only their first names and department in the output. Each employee should appear twice in the list, meaning their first name and department should be duplicated in the output.
Link to the question: https://platform.stratascratch.com/coding/9858-find-employees-in-the-hr-department-and-output-the-result-with-one-duplicate
Understand the question
We are provided with information about workers. The question asks us to find workers who belong to the HR department and output their department and first name.
There is one unusual condition - we need to return two copies of the final answer.
Analyze data
Available data for this question is stored in the worker table. Let’s take a closer look at values in each column:
- Integer values in the worker_id column identify each employee.
- first_name and last_name columns contain employees’ first and last names of the varchar (text) type.
- Integer values in the salary column represent workers’ salaries in dollars.
- joining_date datetime values represent the date when the worker first joined
- Text values in the department column refer to each employee’s department. Since the question asks us to find employees in the HR department, we’ll most likely have to filter records by their department value.
It looks like the department column has three possible values: ‘HR’, ‘Admin’, and ‘Account’.
Plan your approach
We need to filter employees by their department and only keep rows where the value is ‘HR’.
The question also specifies that the final output should only include first_name and department values.
Finally, the answer should consist of two copies of HR employee records. There are many ways to do this, but we’ll explore the simplest approach using UNION ALL.
Write the code
1. Find employees of the HR department
First, we should SELECT records from the workers table. Question instructions clearly tell us to output only two columns - first_name and department.
We need the WHERE clause to filter employees by their department. In this case, we need only to return employees from the ‘HR’ department.
SELECT first_name, department
FROM worker
WHERE department = 'HR'2. Return two copies of the dataset
The final answer should have two copies of all HR employees.
UNION ALL vertically combines the results of two queries and does not remove duplicate rows, so it’s a perfect SQL feature to answer this question.
We already have a query that returns all HR employees. We simply need to combine it with itself.
SELECT first_name, department
FROM worker
WHERE department = 'HR'
UNION ALL
SELECT first_name, department
FROM worker
WHERE department = 'HR'Output
Final answer should return two copies of HR employees’ first names and their department.
| first_name | department |
|---|---|
| Monika | HR |
| Vishal | HR |
| Moe | HR |
| Jai | HR |
| Jura | HR |
| Monika | HR |
| Vishal | HR |
| Moe | HR |
| Jai | HR |
| Jura | HR |
Output with UNION instead of UNION ALL
Let’s illustrate the difference between UNION vs UNION ALL by using the former instead of the latter.
SELECT first_name, department
FROM worker
WHERE department = 'HR'
UNION
SELECT first_name, department
FROM worker
WHERE department = 'HR';| first_name | department |
|---|---|
| Jura | HR |
| Moe | HR |
| Jai | HR |
| Vishal | HR |
| Monika | HR |
As you can see, UNION removed all duplicate rows. The question asks us to output duplicate rows, so we need to use UNION ALL.
SQL UNION vs UNION ALL: Performance

UNION vertically combines two data sets, finds duplicate rows, and removes them. UNION ALL also combines datasets, but it doesn’t remove any records, regardless of their uniqueness.
Because of the extra steps involved, UNION is considered to be the slower of the two, especially when applied to large datasets.
This is a simple explanation that makes sense, but it doesn’t always hold up in the real world. There may be other factors involved, like internet speed, which might make UNION ALL slower. But the best is to assess UNION vs UNION ALL choice on a case-by-case basis.
The general rule is if you are confident that the dataset has no duplicates or that keeping duplicates is necessary for the task, go with UNION ALL.
If you need to ensure there are no duplicate records, go with UNION.
SQL UNION vs UNION ALL: Which is better?
Depends on the task at hand and what information you have about each dataset.
UNION ALL is more efficient, but it is only applicable if:
- You know there won’t be any duplicate values to remove
- Keeping duplicates is necessary for the task
If you want to combine two datasets and ensure there are no duplicates in the final table, use UNION instead.
Summary
In this “UNION vs UNION ALL” guide, we described UNION and UNION ALL, their similarities, differences, and tips for using two set operators.
Having a thorough knowledge of UNION and UNION ALL can increase your chances of finding a job. For example, understand how using one set operator instead of the other can change the query's output.
The StrataScratch platform has hundreds of questions where you can practice writing queries with UNION, UNION ALL, and many other SQL features. You can explore answers from the community and the thought process behind each solution. For example, understand the decision behind using UNION instead of UNION ALL to solve a question.
Share