SQL Interview Questions You Must Prepare: The Ultimate Guide

Categories:
 Written by:
Written by:Nathan Rosidi
This ultimate guide will take you through the top SQL interview questions for various data positions and tips to approach your next interview.
SQL has been a must-have tool in the arsenal of any aspiring data scientist for years and still is in 2025.
However, employers are now prioritizing real-world problem-solving over textbook syntax. Also, recent years have brought the rise of platforms that allow live coding, so the technical interviews have increasingly become timed, interactive, and pair-programmed with a live engineer or recruiter.
And the question itself? The golden era of companies hiring anyone who knows how to turn on the computer for a data science role is long gone. Companies are forced to focus on efficiency in recent years, and that’s reflected in the coding questions: they are more performance-focused. This means it’s not enough anymore to write a code that works; you’ll also have to think about how to optimize it.
As collected data increases, up with it goes the data messiness, so expect for a lot of SQL interview questions to be about data cleaning and analysis preparation.
In the following sections, we will provide you with an outline for learning, preparing, and acing your next SQL interview for a data science role.
We will explore why SQL is so widely used even in 2025, with all the cloud technology and AI surges.
Then, we will give you a breakdown of SQL skills needed by each role – Data Analyst, Data Scientist, Machine Learning Engineer, etc.
Further, we provide you with real interview examples from the StrataScratch platform illustrating a few of these skills and provide you with a step-by-step learning guide to become proficient with SQL even if you are not too familiar with SQL concepts and get your dream job.
So, let us start off by explaining why SQL is so widely used in the data science world.
The Prevalence of SQL
Relational databases are still the most popular types of databases, as shown in the image below.
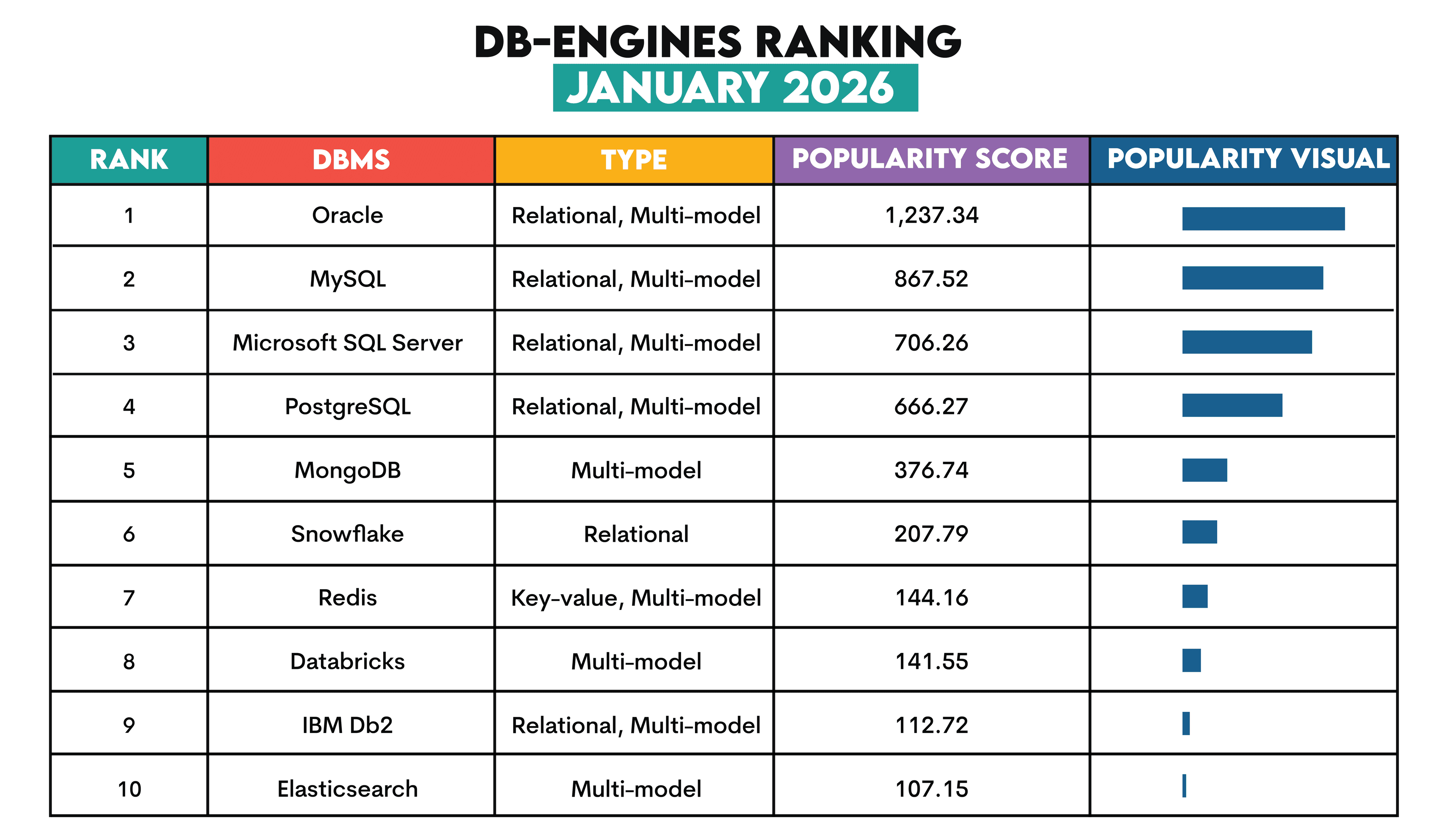
NoSQL databases like MongoDB and Redis have gained traction for big data, real-time applications, and the increasing prevalence of unstructured data.
However, there’s no running away from the facts: four out of the five most popular database engines are relational databases. In the top ten, relational databases take five places (six if you count Snowflake in).
They maintain popularity because they are optimized for storing structured data, which is still everywhere. Relational databases’ tabular format for data storage makes it easy to visualize databases as large spreadsheets with millions and millions of rows and columns.
NoSQL databases won’t be discarding SQL. In fact, NoSQL databases have positioned themselves as such to highlight their support for SQL and increase their acceptance in organizations where traditional SQL-based databases are already used. (It’s a common misconception that NoSQL means literally ‘no SQL’, when in fact it means ‘not only SQL’).
And SQL? It’s a programming language created specifically for handling data in relational databases, which makes its popularity self-explanatory: relational databases stay popular, SQL consequently does, too.
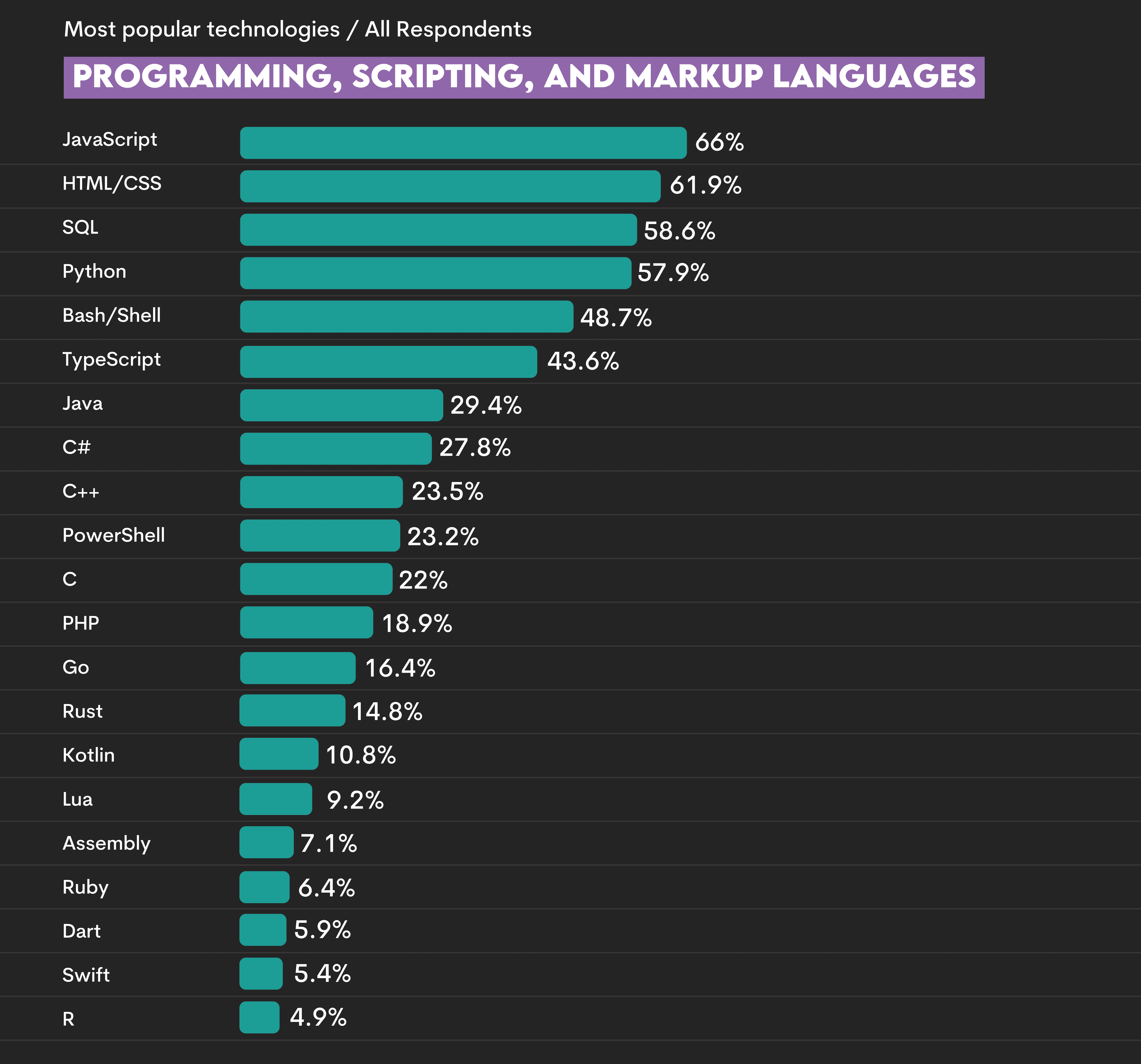
The 2025 Stack Overflow Developer Survey shows that SQL is the third most-popular language.
One additional reason for its popularity is the ease of use. The syntax is very easy to understand, and anyone can pick it up very quickly. It is very easy to comprehend what the following statements do.
SELECT name FROM EMPLOYEES;SELECT name FROM EMPLOYEES
WHERE age >= 35;SELECT state, AVG(age) as average_age FROM EMPLOYEES
WHERE age >= 35
GROUP BY state;With this popularity among data scientists, virtually every job interview will test your SQL skills. But which ones?
SQL Usage in Data Science by Role

Not every position in Data Science uses the same SQL concepts. While some roles will focus heavily on queries and query optimization, others will tend towards data architecture and ETL processes. One can divide SQL Commands asked in Data Science Interviews into the following categories.
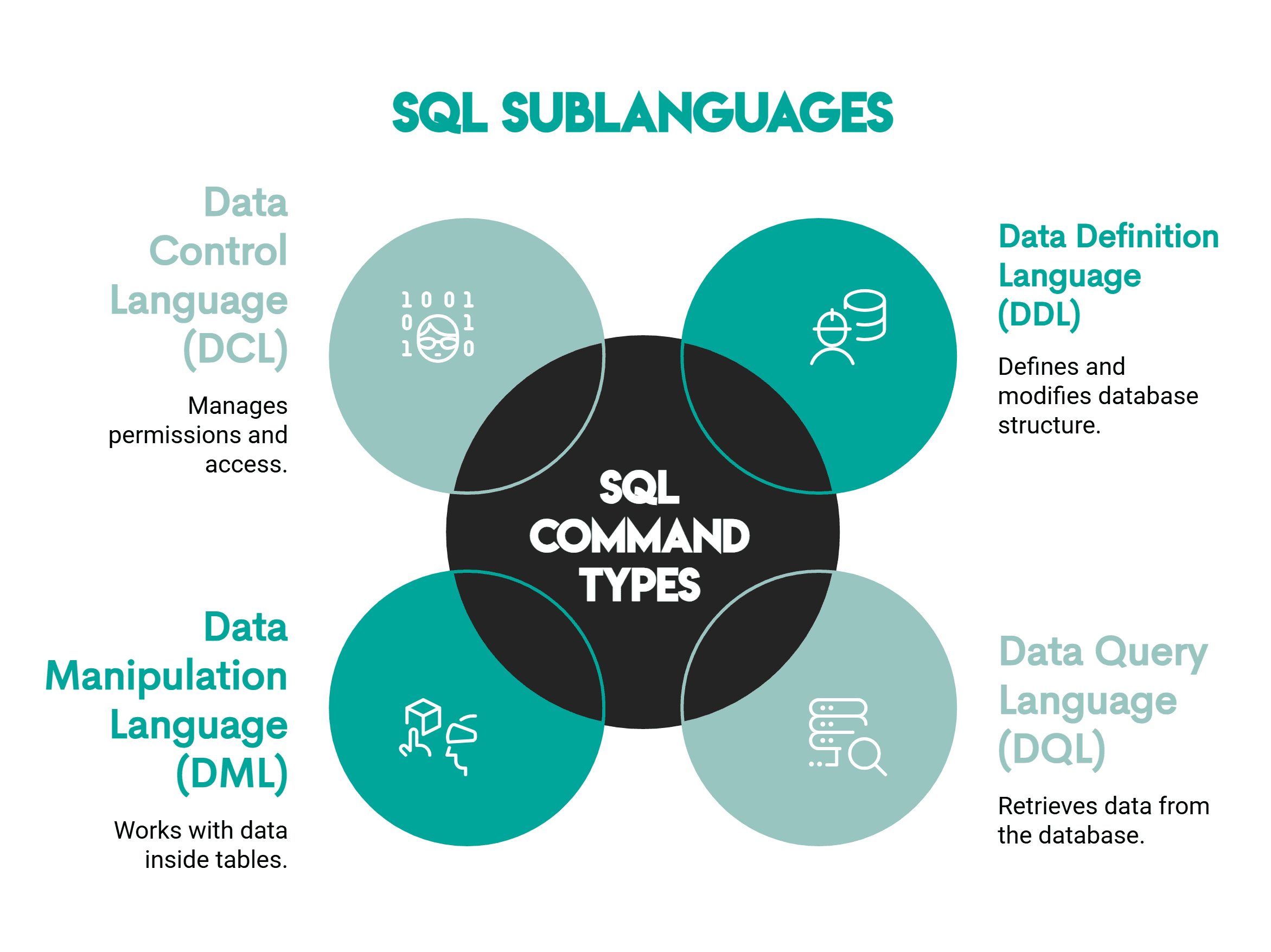
Here’s a more detailed breakdown of each command.
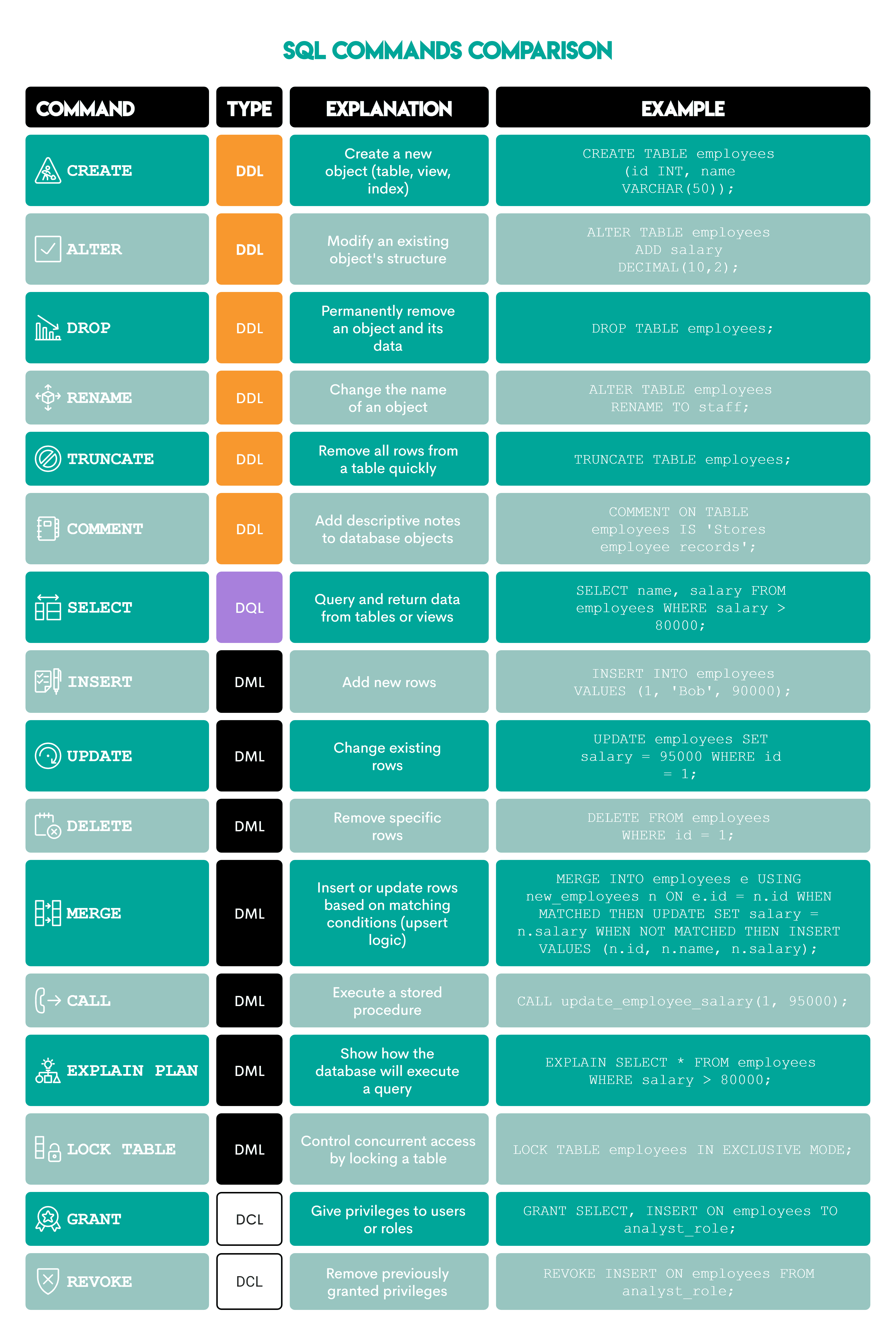
SQL for Data Analysts & Data Scientists
A Data Analyst or a Data Scientist will be expected to mostly be working with the SELECT statement and associated advanced level concepts like subqueries, Grouping / Rollups, Window Functions and CTEs. If you work as an analyst, you probably already use SQL.
It does not matter if you are a data analyst, reporting analyst, product analyst, or even financial analyst. Your position generally requires handling the raw data and using your skills to provide the management and other stakeholders with the decision-making insight.
SQL for Data Engineers
Data engineers work closely with data scientists and data analysts. Their main task is building and maintaining the data architecture and creating algorithms to allow data scientists and analysts easier access to data. By doing their job, they are helping data scientists to do their job too.
As a data engineer, you cannot avoid knowing SQL, often at an advanced level compared to data analysts and scientists. To be a good data engineer, you need to be an SQL master. That is why some of the questions you will be asked are the same as those asked of data analysts and scientists.
Besides the DQL commands, you are expected to be proficient in database modeling; hence, you should know the DDL, DML, and DCL commands in detail.
SQL for Machine Learning Engineers
Machine learning engineers are hybrid experts who are bridging the gap between data scientists and software engineers. As they serve as a bridge between those two positions, they need to have a certain set of skills from both worlds. They use those skills to design, build, and maintain the machine learning systems. To achieve that, they usually use several sets of skills:
- statistics
- mathematics
- data mining
- data analysis
- predictive analytics
Machine learning engineers usually need to know Python and/or R. However, since machine learning engineers and data scientists share some skills (data mining, data analysis), it is often required that machine learning engineers know SQL as well. That way, they can perform their own analyses and use the data as needed. They do not need some intermediary who’ll pull out the data and analyze it for them. For example, here is a question from Uber on creating a Naive Forecasting Model.
Naive Forecasting
Last Updated: December 2020
Some forecasting methods are extremely simple and surprisingly effective. Naïve forecast is one of them; we simply set all forecasts to be the value of the last observation. Our goal is to develop a naïve forecast for a new metric called "distance per dollar" defined as the (distance_to_travel/monetary_cost) in our dataset and measure its accuracy.
Our dataset includes both successful and failed requests. For this task, include all rows regardless of request status when aggregating values.
To develop this forecast, sum "distance to travel" and "monetary cost" values at a monthly level before calculating "distance per dollar". This value becomes your actual value for the current month. The next step is to populate the forecasted value for each month. This can be achieved simply by getting the previous month's value in a separate column. Now, we have actual and forecasted values. This is your naïve forecast. Let’s evaluate our model by calculating an error matrix called root mean squared error (RMSE). RMSE is defined as sqrt(mean(square(actual - forecast)). Report out the RMSE rounded to the 2nd decimal spot.
Develop a naive forecast for a new metric: "distance per dollar". Distance Per Dollar is defined as the (distance_to_travel/monetary_cost) in our dataset. Calculate the metric and measure its accuracy.
Solution Approach:
"Sum the "distance to travel" and "monetary cost" values at a monthly level and calculate "distance per dollar". This is the actual value for the current month.
Next, populate the forecasted value for each month. To achieve this, take the previous month’s value.
Now, we have actual and forecasted values. This is our naive forecast. Now evaluate our model by calculating the root mean squared error (RMSE). RMSE is the square root of the mean of squared differences between the actual and the forecast values. Report the RMSE rounded to the 2nd decimal place."
Here’s the SQL solution.
You have reached your daily limit for code executions on StrataScratch.
Please login/register for unlimited code executions.
This question is just one example of SQL scenario-based interview questions.
SQL for Software Engineers
SQL interviews for software engineers are also usually at an intersection of various skill sets, such as computer science, engineering, and mathematics. They use those different disciplines to design, write, test, and maintain the software. Like the machine learning engineers, they will also need to work with various departments and clients. That is why they too need a high level of business and technical skills, even though their primary task is not data analysis. Why is that? When they build the interface, they have to rely on the database(s) running in the background. They need to use those databases and analyze data during the implementation of new software.
You can refer to this excellent article on the various roles and responsibilities in Data Science to learn more. The article breaks down the most common requirements for each role that you can expect daily.
Let us look at the most frequent SQL areas tested in Data Science Interviews.
Technical Concepts tested in SQL Interview Questions
Since SQL roles differ widely, the testing areas vary quite a bit as well. Depending on the type of role that you are applying for and the organization, you can expect one or more of these SQL data science interview question types.

Fundamental SQL Concepts
The emphasis of these SQL interview questions is on your understanding and knowledge of basic database and SQL terminology. One is not required to write any code. These are the broad concepts and some example questions that one should be familiar with.
- General information about SQL
- What is SQL?
- What are the different flavors of SQL?
- What is a primary key?
- Relational Databases and how they work?
- What are the top RDBMS engines?
- How is an RDBMS different from a No-SQL database?
- SQL sublanguages and their main keywords
- What do DDL, DCL, and DML stand for?
- Give examples of commands for each.
- Data types and how SQL handles it (including blanks and NULLs)
- What are the common data types in SQL?
- Does an SQLite database support date time objects?
- Attribute constraints
- What are attribute constraints, and explain them?
- types of JOINs
- What is the difference between inner join and left outer join?
- What is the difference between UNION and UNION ALL?
- Aggregation and Rollup functions
- When should one use a CTE over a subquery?
- What are window functions?
- Knowledge of various SQL functions
- What is the difference between WHERE and HAVING? Examples of where one should use one over the other
- What does the COALESCE function do?
While one may not find them in the interviews initially, these SQL interview questions might be asked as follow up questions to the coding solutions submitted by you. For example, if you used an inner join in your solution, you might be asked why you did not use a left join or what would have happened if you did?
SQL Basics Interview Questions
The SQL basics questions will require you to put some of the above theoretical concepts into practice. That doesn’t necessarily mean that these questions have to be coding questions. They can be descriptive, too. But they usually cover concepts you will need to know if you want to write code.
Those concepts are shown in the image below.

Questions Example
Here is an example from a Postmates SQL Data Science Interview
SQL Interview Question #1: Customer Average Orders
Customer Average Orders
Last Updated: February 2021
How many customers placed an order and what is the average order amount?
Solution: To answer this SQL interview question you’ll have to use the table postmates_orders.
SELECT count(DISTINCT customer_id), avg(amount)
FROM postmates_ordersYou have reached your daily limit for code executions on StrataScratch.
Please login/register for unlimited code executions.
As one can see, this is really an easy one. It tests the aggregate functions COUNT() and AVG(), and it also requires the knowledge of how to use the DISTINCT clause.
Here’s another one, this time from Credit Karma:
SQL Interview Question #2: Submission Types
Submission Types
Last Updated: January 2021
Write a query that returns the user ID of all users that have created at least one ‘Refinance’ submission and at least one ‘InSchool’ submission.
Solution: To answer this interview question, you’ll need to use the loans table.
SELECT user_id
FROM loans
WHERE TYPE in ('Refinance', 'InSchool')
GROUP BY user_id
HAVING count(DISTINCT TYPE) =2You have reached your daily limit for code executions on StrataScratch.
Please login/register for unlimited code executions.
The code selects the column user_id from the table loans where the value equals one of the two values: “Refinance” and “InSchool”. Since we need to ensure that there are submissions in each type, we need to use the DISTINCT clause. One also needs to appreciate the difference between WHERE and HAVING. Since we are using the DISTINCT clause in the aggregate function, we have used HAVING instead of WHERE, which can’t be used after the aggregation.
SQL Aggregation Interview Questions
Aggregation functions are widely used for reporting metrics and evaluating summary results, something data analysts and data scientists do a lot.
The purpose of aggregation is to transform data into information. This information is presented as reports, dashboards, and charts. What you report are different metrics that need to be monitored. So, basically, your two main tasks will be aggregating and filtering data and performing various calculations on that data.
Strictly speaking, data analysts and data scientists are not reporting but analyzing the data. However, there are a lot of instances where one needs to monitor and report metrics on a regular basis.
If you are interviewing for an SQL data analyst or data scientist position, you are expected to be familiar with the concepts below.

Questions Example
This is a moderate SQL interview question from Zillow that tests your understanding of aggregations functions
SQL Interview Question #3: Cities With The Most Expensive Homes
Cities With The Most Expensive Homes
Last Updated: December 2020
Write a query that identifies cities with higher than average home prices when compared to the national average. Output the city names.
Solution: To answer this question you’ll have to use the table zillow_transactions.
SELECT city
FROM zillow_transactions a
GROUP BY city
HAVING avg(a.mkt_price) >
(SELECT avg(mkt_price)
FROM zillow_transactions)
ORDER BY city ASCYou have reached your daily limit for code executions on StrataScratch.
Please login/register for unlimited code executions.
To answer this SQL interview question, we write a subquery in the HAVING clause. The inner query calculates the overall average market price of all the transactions. The main query then filters only those cities where the average market price is greater than the overall average market price. Since we need to report only the cities in the final output, only those metrics are reported.
Here is another one. This one is a little more complex from Lyft.
SQL Interview Question #4: Distances Traveled
Distances Traveled
Last Updated: December 2020
Find the top 10 users that have traveled the greatest distance. Output their id, name and a total distance traveled.
Solution: To answer this SQL interview question you will have to use the tables lyft_rides_log, lyft_users.
SELECT user_id,
name,
traveled_distance
FROM
(SELECT lr.user_id,
lu.name,
SUM(lr.distance) AS traveled_distance,
rank () OVER (
ORDER BY SUM(lr.distance) DESC) AS rank
FROM lyft_users AS lu
INNER JOIN lyft_rides_log AS lr ON lu.id = lr.user_id
GROUP BY lr.user_id,
lu.name
ORDER BY traveled_distance DESC) sq
WHERE rank <= 10;You have reached your daily limit for code executions on StrataScratch.
Please login/register for unlimited code executions.
This SQL question tests subqueries, window functions, and joins. We start off by joining the two tables with an inner join as we need those users who have used the services and remove the rides with incomplete user information. We then proceed to rank the sum of the total distances travelled by these users. We finally select the top 10 users by rank and output their names and total distances travelled.
To improve your coding skills for SQL Data Science Interviews, you can refer to this video where we discuss some top data science interview questions, how to solve them and avoid common mistakes.
Open Ended SQL Interview Questions
You will encounter these types of SQL interview questions in Data Analyst or Data Scientist positions that require some work experience. The greatest challenge in these questions is the lack of any specified metric that needs to be calculated, as in the case of SQL Aggregation Interview Questions. You will still be required to write an SQL query that will return some metric(s) as a result. However, there is one big difference. In the Open-Ended SQL Interview questions, you will be asked to find the insight.
It is entirely up to you to understand your data and what calculation answers what you are being asked. For example, you will have to find out if some product launch campaign succeeded, or new calling procedure saves costs, or if new vehicles improved the users’ satisfaction. You will have to come up with metrics to define “success”, “saving”, or “improvement”.
Compared to the SQL Aggregation questions, these questions have this extra dimension designed to test your thinking in solving the problem. Regarding the coding part of the Open-Ended SQL interview questions, they test all the concepts you will use in the basic level and the SQL Aggregation type questions.
Questions Example
Have a look at a question asked by Uber:
SQL Interview Question #5: Percentage Of Revenue Loss
Percentage Of Revenue Loss
Last Updated: June 2021
For each service, calculate the percentage of incomplete orders along with the percentage of revenue loss from incomplete orders relative to total revenue.
Your output should include:
• The name of the service • The percentage of incomplete orders • The percentage of revenue loss from incomplete orders
Solution: To answer this question, we must use the table uber_orders.
SELECT service_name,
(lost_orders_number/total_orders)*100 AS orders_loss_percent,
(lost_profit/possible_profit)*100 AS profit_loss_percent
FROM
(SELECT service_name,
SUM(number_of_orders) AS total_orders,
SUM(number_of_orders) FILTER (
WHERE status_of_order != 'Completed') AS lost_orders_number,
SUM(monetary_value) AS possible_profit,
SUM(monetary_value) FILTER (
WHERE status_of_order != 'Completed') AS lost_profit
FROM uber_orders
GROUP BY 1) tmp;
You have reached your daily limit for code executions on StrataScratch.
Please login/register for unlimited code executions.
In order to solve this problem, we need to define the revenue loss percentage. Percentage means that two values will be divided, but which two? We should compare the lost revenue with the possible revenue. Now, how to define these two metrics? The possible revenue is the sum of all the orders' monetary value, regardless of their status. Lost revenue will therefore equal the sum of monetary values for all orders that were not completed.
The same needs to be done with the percentage of incomplete orders, but this is more straightforward: divide the number of not completed orders with the number of completed.
The next question is how we define the completed orders? It’s almost a lucky guess to think that the completed orders will have the status ‘Completed’. It could have been something else or even a combination of several statuses. Also, some of the orders with the status ‘Completed’ have a NULL monetary value. Maybe they shouldn’t have been considered as completed?
Based on the definitions, we calculate the metrics in the subquery. It uses the SUM() aggregate function and FILTER modifier. Then, in the main query, we use the subquery’s result to get the required metrics as percentages.
This is an open-ended SQL question because you were not given the meaning of the revenue loss nor how to find the completed orders. Also, the query considers that all the orders with a status other than ‘Completed’ are lost. However, the question doesn’t say only those orders should be considered as completed. You could apply different criteria. For example, there’s also the status ‘Other’. Since we are not told what this status means, it wouldn’t be a mistake to count such orders as completed, too. The important thing is that you state this explicitly in your assumptions.
Data Transformation Interview Questions
These are the SQL interview questions that one can expect to be asked very frequently for a data engineer or a machine learning engineer position. They also may not be out of place in a data scientist interview for positions that require more experience.
Data transformation is extensively performed within an ETL (Extract, Transform and Load) process, which is used to collect data from various sources (extract), changing it according to the business rules (transform), and then loading such extracted and transformed data into a database.
When the data is extracted, it is done so from various data sources that, more often than not, store data in completely different formats.
The data is then transformed into the format appropriate for reporting and analysis. This is done via data aggregation, filtering, sorting, joining, a calculation based on the rules set for business needs, etc.
Such data is loaded into another database or table that the analysts or any other users might use.
The ETL is heavily used in data warehouses, which serve as the central source of the integrated data, with data flowing into it from one or more separate sources. If you want to perform well at the SQL job interview, these are the concepts you need to know.

Question Examples
This is one of the easiest and yet frequently asked questions from the Southwest Airlines Data Science SQL Interview:
SQL Interview Question #6: DELETE and TRUNCATE
DELETE and TRUNCATE
Last Updated: March 2019
What is the difference between DELETE and TRUNCATE?
Answer:
DELETE is a DML statement.
TRUNCATE is a DDL statement.
The DELETE statement can be used to delete all rows or only some rows. To delete some rows, you’ll have to use the WHERE clause. While doing this, every row removed will be logged as an activity by the database.
On the other hand, TRUNCATE is used only for deleting the whole table, which will be logged as only one action. That’s why TRUNCATE is faster than DELETE, which shows when deleting a table with a huge amount of data. Also, you can’t use TRUNCATE if there’s a foreign key in the table.
Another common SQL interview question to appear is
"How do you change a column name by writing a query in SQL?"
Answer: Assuming you are using PostgreSQL. For a hypothetical table say product, one of the columns is named year, but I want to rename it to description. The query that will do that is:
ALTER TABLE product
RENAME year TO description;Another example of Data Transformation SQL Interview question will be:
"How do you create a stored procedure?"
Answer: We will solve this for Microsoft SQL Server. For example, if you are using a table named employee. Your procedure should help you get the employees that work in a certain department. The code would be:
CREATE PROCEDURE employee_deparment @deparment nvarchar(50)
AS
SELECT * FROM employees WHERE department = @department
GO;Once the procedure is created, I can invoke it in the following manner:
EXEC employee_deparment @department = 'Accounting';Database Modeling Interview Questions
These SQL interview questions are designed to test how good you are at database design or database modeling. What is meant by that? You need to show the ability to design and build the database from scratch according to the business processes and business needs. This requires a high level of both technical and business knowledge. You will be working with both technical and non-technical colleagues. So, you need to understand both the business side of their requirement and how to, in the soundest way, technically cater to their business needs regarding the data. Generally, this is a process that goes through these steps (at least in the ideal world):
- defining the database purpose
- collecting and defining users’ requirements
- creating a conceptual model
- creating the logical model
- creating the physical model
Question Examples
One of the typical questions that occur in the SQL interviews is this one by Audible:
SQL Interview Question #7: Build a Recommendation System
Build a Recommendation System
Last Updated: February 2020
Can you walk us through how you would build a recommendation system?
Answer: Since there is a wide variety of approaches to answer this question, we will leave you to come up with your own way of building one.
The database design question can also include SQL coding, such as this one from Facebook:
SQL Interview Question #8: GROUP or ORDER BY
GROUP or ORDER BY
Last Updated: January 2021
Write a SQL query to compute a frequency table of a certain attribute involving two joins. What if you want to GROUP or ORDER BY some attribute? What changes would you need to make? How would you account for NULLs?
Answer: Due to the nature of the question, we will let you answer this one on your own.
Software Engineering SQL Interview Questions
These questions test your logical skills more than coding skills, even though they require coding knowledge, too.
As a software engineer, you might not be writing SQL code every day. However, you still need to interact with your peers who do use SQL daily. You’re implementing their needs and SQL logic into software development, so you must understand them.
One such SQL interview question that could be asked during your interview could be this one. Imagine you’re working with two tables.
The first table is product, with the following data:
idproduct_namemanufacturer_id
The second table is manufacturer, with the following data:
idmanufacturer
There are 8 records in the first table and 4 in the second one.
How many rows will the following SQL code return:
SELECT *
FROM product, manufacturerAnswer: The query will return 32 rows. Whenever the WHERE clause is omitted, the default result is CROSS JOIN or a Cartesian product. This means the query will return every combination of rows from the first table with every combination of rows from the second table.
The SQL Interview Questions Asked by the FAANG Companies

FAANG is an acronym for the five most famous tech companies: Facebook, Amazon, Apple, Netflix, and Google. Why would you specially prepare for the questions asked by those companies, except being in awe of the possibility of working for them? They might seem or even be attractive, but that is not the main reason why you would pay special attention if you want to work at those companies.
The main reason is their SQL interview questions are a bit different. As tech companies, their business heavily relies on data. And where there is data, there is SQL which the FAANG companies often use. Hence they want to be absolutely certain that their employees know SQL in depth. You will always get SQL interview questions with a little twist. The twist being their questions are more practical and concerning a case study with real problems and data a certain company is facing in their everyday business. These are arguably the next level of the Open Ended SQL Interview Questions that we saw earlier.
Have a look at this example from Google:
SQL Interview Question #9: Activity Rank
Activity Rank
Last Updated: July 2021
Find the email activity rank for each user. Email activity rank is defined by the total number of emails sent. The user with the highest number of emails sent will have a rank of 1, and so on. Output the user, total emails, and their activity rank.
• Order records first by the total emails in descending order. • Then, sort users with the same number of emails in alphabetical order by their username. • In your rankings, return a unique value (i.e., a unique rank) even if multiple users have the same number of emails.
Solution: To answer this question, you’ll need to use the google_gmail_emails table.
SELECT from_user,
COUNT(*) as total_emails,
ROW_NUMBER() OVER (ORDER BY COUNT(*) DESC, from_user ASC)
FROM google_gmail_emails
GROUP BY from_user
ORDER BY 2 DESC, 1
You have reached your daily limit for code executions on StrataScratch.
Please login/register for unlimited code executions.
As you can see, this SQL interview question tests your aggregate functions and window functions knowledge, along with the GROUP BY and ORDER BY clauses. But they also do that on real-life problems you’ll probably have to work on if you get a job.
Here is another example of such question, this time from Netflix:
SQL Interview Question #10: Find the nominee who has won the most Oscars
Find the nominee who has won the most Oscars
Find the nominee who has won the most Oscars. Output the nominee's name alongside the result.
Solution: To answer this question, you must use the oscar_nominees table. As you can see, the code specifically uses the RANK() window function. You could achieve the same result with DENSE_RANK() but not ROW_NUMBER().
WITH cte AS
(SELECT nominee,
RANK() OVER (
ORDER BY count(winner) DESC) AS rnk,
count(winner) AS n_times_won
FROM oscar_nominees
WHERE winner = TRUE
GROUP BY nominee)
SELECT nominee,
n_times_won
FROM cte
WHERE rnk = 1You have reached your daily limit for code executions on StrataScratch.
Please login/register for unlimited code executions.
Here’s a quick overview of the differences between those SQL ranking window functions.
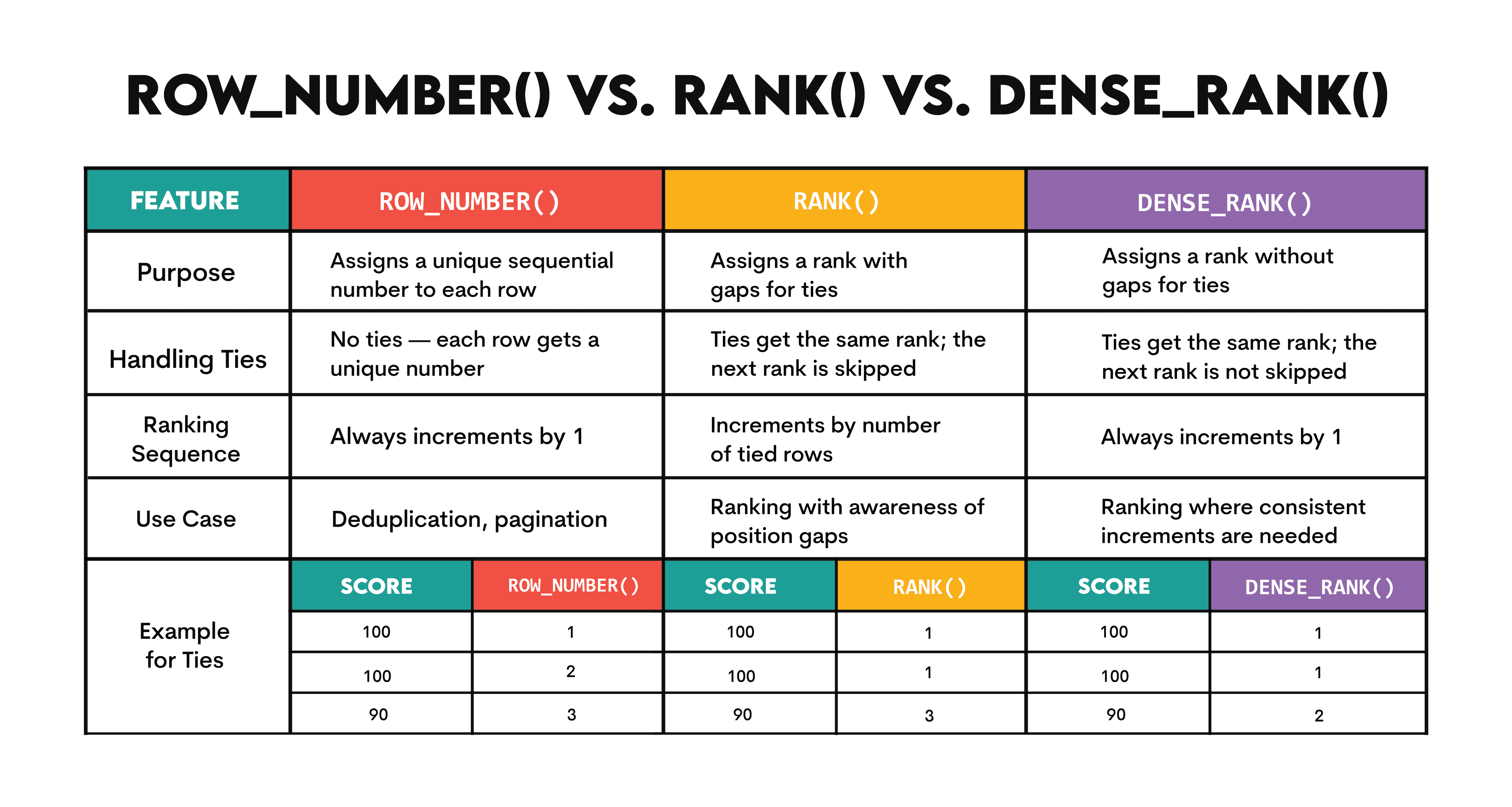
Again, this SQL interview question tests some usual concepts. But the problem set is something that you expect to work on a daily basis. If you work at Netflix on an SQL job, you will for sure analyze some data that contains some Oscar nominations and winners.
What to study for your SQL Data Science Interviews?

You would have probably noticed that the technical SQL interview questions overlap with other SQL questions. That is because one does not work without the other. There is no point in knowing the theory without being able to put it into practice, i.e., the SQL code. Conversely, you need to describe the technical concepts behind the code that you wrote. While the SQL concepts you should know depend on your position, years of experience, and the company you want to work at, we have looked at some concepts that are useful across roles. While this is not an exhaustive list, it is definitely something that you are expected to know if you are attending an SQL Data Science Interview.
SQL & Database Generalities
SQL definition
SQL stands for “Structured Query Language”. It is a programming language used for creating database structure, retrieving and manipulating data in it.
Types of the SQL commands
(You can find the info about this in the “SQL Usage in Data Science by Role” section)
Relational database
A relational database is one based on the relational data model. This means the database is a collection of relations. Those relations are shown as tables, which consist of columns, rows, and values. The relational database aims to minimize or completely avoid data redundancy, leading to data integrity and speeding up its retrieval.
Relationships in the database
The relationship defines the type of connection between the tables in the database. There are three main types of relationships:

Database normalization
Database normalization is a process of organizing data in the database to achieve its purpose: data integrity, its non-redundancy, and speed of retrieval.
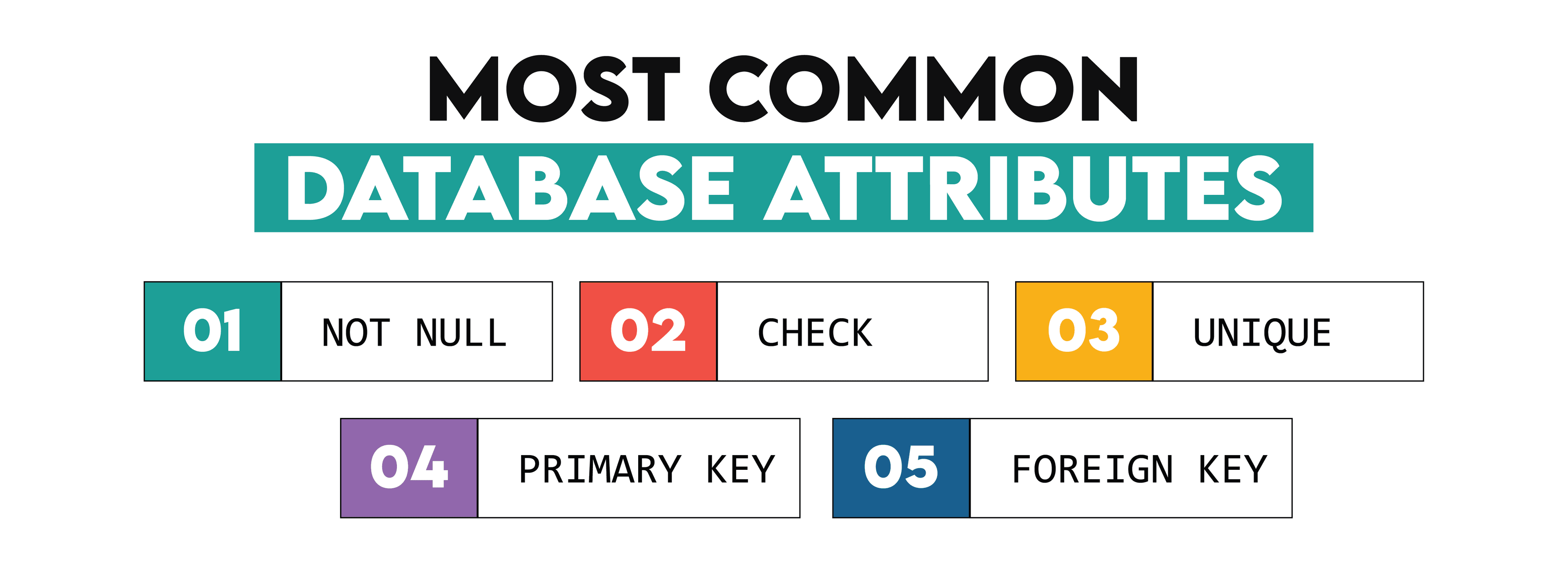
Constraints
The constraints are the rules that define what type of data can and can’t be entered as a value in the database.
These are the most common attributes:
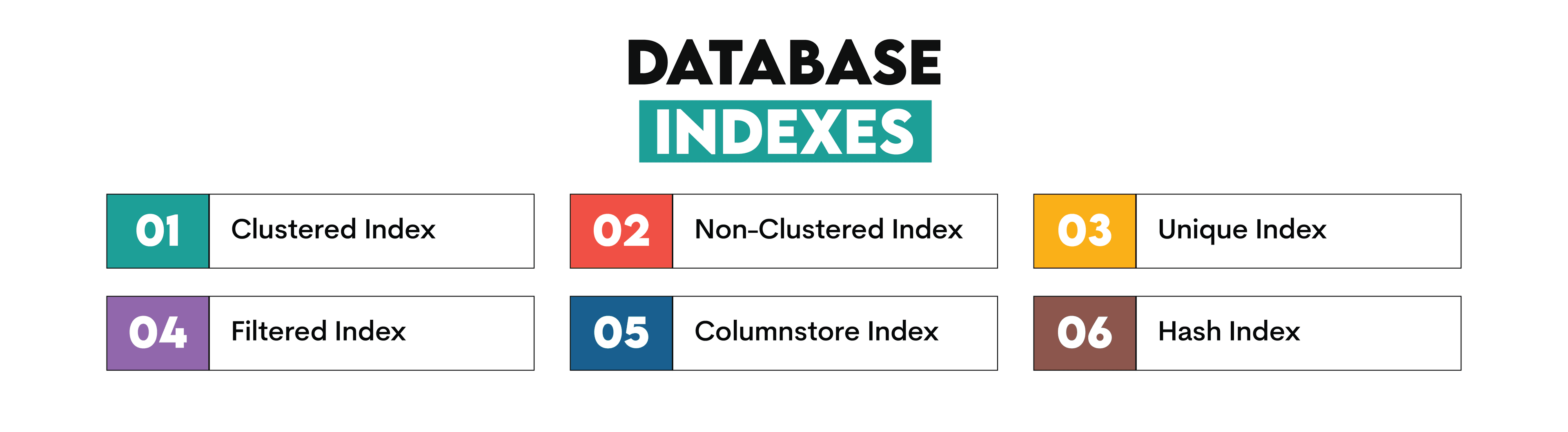
Indexes
The indexes are structures in the databases created to tune the database performance. They are used to speed up data retrieval.
Here are the index types.
View
A view is a virtual table containing data from one or more tables resulting from a SQL statement.
Stored procedure
A stored procedure is an SQL code consisting of one or several SQL statements that are saved and can be called and executed whenever required.
Trigger
A trigger is a special type of a stored procedure. It is automatically executed (triggered) whenever some special event occurs in the database.
Joining Tables & Queries
Inner join
An Inner join returns only those rows where the data from one table matches the data from the second table.
Left outer join
The left join is a table join that will retrieve all the rows from the left table and only the matching rows from the right table.
Right outer join
This join is the one that returns all the rows from the right table and only the matching rows from the left table.
Full outer join
The full outer join will join the data so that the result will include all the rows from one table and all the rows from the second table.
Cross join
This results in a Cartesian product. This means it will return all the combinations of rows from one table with all the combinations of rows from the other table.
Union
This is an SQL command that will combine the result of one query with the result of another query. Therefore, it will show only unique records.
Union all
This one also combines the results from two or more queries. The difference between UNION and UNION ALL is that it will also include duplicates.
Aggregating and Grouping Data
Aggregate functions
The SQL aggregate functions perform a calculation on a data set and return a single value as a result. Examples of aggregate functions are:

GROUP BY clause
The SQL GROUP BY clause allows you to group data according to the defined (one or more) criteria.
Filtering & Ordering Data
DISTINCT clause
The DISTINCT clause is a clause that will return only distinct or unique values, i.e., there will be no duplicate values in the result.
WHERE clause
The WHERE clause is used to filter data according to the specified criteria.
HAVING clause
The HAVING clause also filters data according to the specified criteria. The difference compared to the WHERE clause is that the HAVING clause works with the aggregate functions. Therefore, if used, it always follows the GROUP BY clause and precedes the ORDER BY clause.
ORDER BY clause
The ORDER BY clause is used to order the query result according to a certain data column.
CASE statement
The SQL CASE statement returns a defined value based on certain criteria. It is the SQL statement that allows you to apply the IF-THEN logic. Instead of IF, you use WHEN. And for THEN, you use THEN. Check out our comprehensive guide to CASE WHEN statements in SQL.
Subqueries, Common Table Expressions (CTEs) & Window Functions
Subquery
A subquery is a query found within the query. It can occur in a SELECT clause, FROM clause, or WHERE clause.
CTE
A SQL CTE or a Common Table Expression is a temporary result set returned by a query and used by another query. In that way, it’s similar to subquery. But the main difference is CTE can be named and can reference itself.
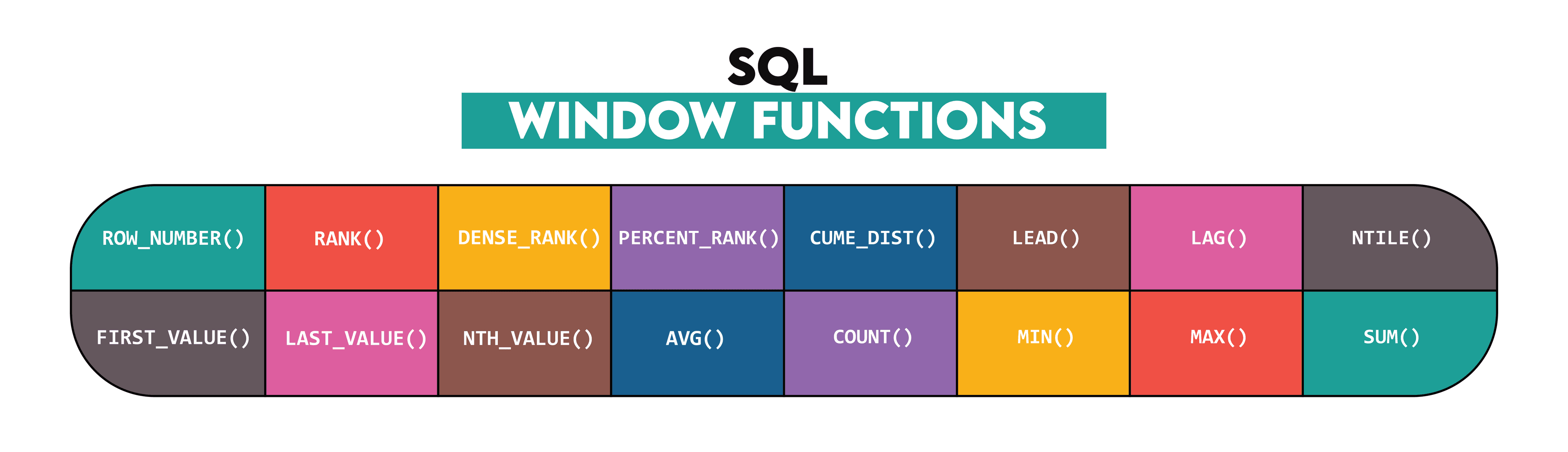
Window functions
The SQL window functions are the functions performing calculations over the defined set of rows (a window). Compared to the aggregate functions, which return a single value as a result, the window functions allow you to add the aggregated value to each row in a separate column. This means the rows are not grouped and all the rows are kept as a query result.
The window functions in SQL are shown below.
How to Organize your SQL Data Science Interview Solution?

Being good at SQL is the prerequisite to do well at the job interview. However, it is not the only skill. Questions can be tricky, designed to put you off or doubt your knowledge by being seemingly too complicated or too simple. That’s why it’s important to have a clear strategy on what to do in certain situations.
1. Make Sure you Understand What is Required
If you don’t understand what the question is and what is expected from you, you will likely get the wrong answer. To avoid that, make sure you understand what is asked of you. Repeat the requirements out loud and ask the interviewer to confirm you understood the question correctly. Don’t be afraid to do that. The interviewers are people too. They can also unintentionally be unclear, make a mistake, or forget to give you enough details for you to answer correctly.
2. Outlay Your Approach
Before you start answering, especially if you are writing SQL code, outlay your approach. That way, you will be able to find the solution faster and or find the holes in the code you intended to write. You should do that to allow the interviewer to lead you through in case you missed the point of the question. It is always better to be corrected before presenting the final solution.
3. Try to Visualize the Output
This is something that can help you in writing the problem-solving code. Sometimes, when you clarify how the output should look and compare it with initial data, the approach and the solution reveal themselves.
4. Write the SQL Code
At some point, you will need to start writing the code. As we discussed, you should not jump headfirst into it. But you cannot keep procrastinating on the best approach to write it. After you have gone through all those previous steps, and you are still not sure if you have the right solution, simply start writing the code.
One of the reasons is, sometimes there is no solution at all. Meaning the question is too complex to be solved in the time you’re being given. In such cases, the interviewer is not interested in your solution. Instead, he or she is interested in your way of thinking and how you approach the problem. There are usually multiple ways to use SQL for problem-solving, and this is what some interviewers are interested in: the process, not the goal.
5. Code in Logical Parts
When you’re writing the code, pay attention to its structure. Divide the code into logical parts. That way, you will make your code easier to read, which is also one of the requirements to get the job. There is no point in writing a correct code that is a mess, and nobody can read it and understand it after you write it. Not even you!! If your code is divided into logical parts, it will be easier for you to explain to the interviewer what you did.
6. Optimize Code
It is also important to have the code optimization in mind. If your code is complex, of course, you are not going to be able to optimize it as you write. But you should pay attention to some general optimization guidelines, so your code is reasonably optimized. You can also discuss with the interviewer what other steps you will have to take to optimize your code in the aftermath. This is also the job requirement, similarly to the previous point. There is no point writing the code that will get you the required result, but takes forever to execute.
7. Explain Your Answer and Assumptions
Even if you did not get the required answer, it does not mean you failed the interview. That is why you should always know why you did something and explain why you did it. Maybe you did not get the answer to the question they asked, but you did get the answer to some questions. So make sure that you state your assumption and explain why you did what you did. Again, they may be looking exactly for that: the right reasoning in line with assumptions, even though the assumptions were wrong. That also shows you know what you are doing, even if it is not what they asked.
Also, one of the reasons for explaining the assumptions is there may be a loophole in the question. So imagine pointing at it right there at the interview by simply explaining why you did something while you thought you were all wrong.
Here is the video where Nate from StrataScratch shares some tips on how to organize your SQL interview solution:
Bonus SQL Interview Tips
Here are some additional tips that might help you to be a success at the upcoming SQL interview.
Get to Know the Your Potential Employer
This is important in general, not only for the SQL part of the interview. It is important to be informed about your future employer, their products, and their industry. It is especially important when the SQL questions are regarded. Why is that?
As we discussed earlier, the FAANG companies will usually ask you very practical SQL coding questions that will have you use the same data and solve the same problems as you would have to when you get employed. The FAANG companies are not the only ones who do that. So when you prepare for the interview, try to think which data is important to this company, how their database could look like, etc. When you practice the SQL interview questions, try to find the real questions from the companies you are interested in or at least from their competitors. If the companies are in the same industry, it’s quite likely the data they use will be more or less the same.
Be Prepared for a Whiteboard
It is quite usual to be asked to write SQL code on a whiteboard. It can be shocking to some people, which is understandable. You are probably used to writing code in a real RDBMS, on real data, which allows you to regularly check if the query works. Not even the greatest masters of SQL can write a code without running it to see if it works at all or if it returns the desired result. However, in the SQL interview, the criteria are a little higher.
While it can be scary, it is also understandable. Writing the code on a whiteboard shows that you know how to write your code. Reading your (or someone else’s code) is also important. This is the skill that is also tested on a whiteboard. If you can read a code and say if it will give you the desired result without relying on the database to tell you that, then working with a real database and SQL environment will be easier for you.
Write a Clean Code
We are not talking about your handwriting. There is not much you can do if your handwriting is messy. But that does not mean your code has to be unreadable. When you write a code, try to format it so that it is easier for you and the interviewers to read it and check your solution.
"Code is read more often than it is written. Code should always be written in a way that promotes readability.
- Guido Van Rossum, the creator of Python"
Regularly use spacing and line breaks to make your code easier to read. If you need to (re)name tables and columns, be consistent with the naming convention you choose. Add comments whenever needed. Try to use aliases whenever possible, but try to make them sound logical and not some random decision when you do.
Here are also some useful tips from Nate on how to organize lengthy SQL codes.
Write in the Company’s SQL Dialect Only if you are comfortable with it
If you have experience with multiple SQL databases (Oracle, PostgreSQL, Microsoft SQL Server, MySQL), try to adapt and write in a dialect of the database that is used at your future employer. That would be nice and could show your versatility, especially if you know what dialect they prefer. However, if you are familiar with only one dialect, do not think that it is the end of the interview. For example, if you were using only PostgreSQL and the company is using Microsoft SQL Server, there may be different keywords for the same command in those two databases. It is also possible that PostgreSQL has some functions that aren’t allowed in Microsoft SQL Server and vice versa.
Ask the interviewer if it is possible to write a code in, say, PostgreSQL instead of Microsoft SQL Server since you are more familiar with it. It is always better if you know several dialects. But it is also better if you write in a familiar dialect, even though “the wrong one”, than mess up the code just because you were too afraid to ask if you can write in a dialect you are comfortable with. The differences between the dialects are not that huge. So if you know SQL, you’ll easily and quickly adapt to a new database.
Communication. Confidence. Collaboration.
While the interview is evaluating you, there are other things that employers look for in an employee besides just coding ability. You will be working as a part of a team and hence your ability to confidently put across your ideas, be open to positive feedback about your codes and ability to work as a team is equally important. Employers try to gage these even during something as technical as coding.
It is vital that you ask for help in case you are stuck. Asking for help shows confidence and is not a sign of weakness. Keep the interviewer in the loop regarding what your thought process is so that she might be able to help you in case you are stuck or omitted some information unintentionally. Listen to any explanations provided to ensure that you have taken care of all the edge cases that might arise.
These are skills that every Data Scientist must possess and unfortunately not a lot of candidates focus on them. An interviewer is more likely to hire a Data Scientist with sound basic understanding of SQL and willing to adapt to changes and pick up additional skills on the way over a prodigious but rigid one. The employer is looking at the potential for a long term relationship. If you give the right signals, you might just land your dream job. We recommend checking out these 5 tips on how to prepare for a Data Science interview.
We have also gathered some advanced-level SQL interview questions asked by real companies in 2021 that you can find in our Advanced SQL Questions You Must Know How to Answer article.
Related Guides
In this article, we looked at the various aspects of an SQL data science interview. We started off by understanding why SQL is so popular in the data science world and the different roles that are available in the industry. We then provided a detailed overview of the types of SQL interview questions you can expect for each position and what to learn to become proficient with SQL for data science Interviews.
However, we can’t cover everything in one article. That’s why here’s an extensive list of our articles that will help you learn different aspects of SQL.
- General SQL interview questions:
- SQL interview questions by position:
- DISTINCT clause:
- Aggregate functions:
- ORDER BY:
- Joins:
- A Comprehensive Step-by-Step Guide to Full Outer Join in SQL
- A Detailed Comparison Between Inner Join vs. Outer Joins
- Different Types of SQL JOINs that You Must Know
- How to Join 3 or More Tables in SQL
- Similarities & Differences: Left Join vs. Left Outer Join
- Joining Multiple Tables in SQL - Examples and Walkthrough
- Illustrated Guide About Self Join in SQL
- SQL JOIN Interview Questions
- Window functions:
- The Ultimate Guide to SQL Window Functions
- An Introduction to the SQL Rank Functions
- Mastering Row Number Handling in SQL Queries
- Mastering SQL DENSE_RANK(): A Comprehensive Guide
- Utilizing DENSE_RANK for Data Deduplication in SQL
- SQL PARTITION BY: Advanced Analytical Insights
- SQL ROW_NUMBER() Function: Syntax and Applications
- SQL Window Functions Interview Questions
- Subqueries & CTEs:
- UNION & UNION ALL:
Pick Your Path: SQL Interview Questions by Company
Solving general SQL interview questions and those focusing on a certain technical concept is a must. That’s why we linked so many additional resources above.
However, if you want a bonus, laser-focused approach, finalize your interview preparation by solving the interview questions from the exact company you’re interviewing at.
Here are some suggestions:
- Microsoft SQL Interview Questions
- Amazon SQL Interview Questions
- Uber SQL Interview Question
- DoorDash SQL Interview Questions
- Google SQL Interview Questions
- LinkedIn Data Scientist Interview Questions
Conclusion
Even if you have just started with SQL, all that it takes to become interview-ready is persistence, patience, and lots of practice. If you have little real-world experience with SQL, it is very important that you practice writing SQL code. Do it often and regularly.
Continuity is very important. Try to answer as many SQL interview questions as possible, be it hypothetical or, even better, the real ones from the company you want to work at. Only by writing a lot of code, you gain experience, grasp some typical problems that need to be solved by SQL, and the syntax will become second nature.
Even if you are vastly experienced in SQL and use it in a business environment, it is always good to prepare for an interview and brush up on your skills. Nobody knows everything about SQL.
Generally, people know what they need and what they use regularly. So it is possible that after several years at your job, you have become a master of a certain aspect of SQL. Do not let it make you think you know it all. Your new job will ask you to know some different SQL functions and possibilities, ones you are not exactly versed in. That’s normal.
Practice Section
We've already shown you many SQL interview questions, including solutions. Now, it’s time for you to roll up your sleeves and solve several questions on your own.
Practice Question #1 (Easy): Salaries Differences
Salaries Differences
Last Updated: November 2020
Calculates the difference between the highest salaries in the marketing and engineering departments. Output just the absolute difference in salaries.
Write & test your solution here:
You have reached your daily limit for code executions on StrataScratch.
Please login/register for unlimited code executions.
Expected output:
| salary_difference |
|---|
| 2400 |
Practice Question #2 (Medium): Users By Average Session Time
Write & test your solution here:
Users By Average Session Time
Last Updated: July 2021
Calculate each user's average session time, where a session is defined as the time difference between a page_load and a page_exit. Assume each user has only one session per day. If there are multiple page_load or page_exit events on the same day, use only the latest page_load and the earliest page_exit. Only consider sessions where the page_load occurs before the page_exit on the same day. Output the user_id and their average session time.
Write & test your solution here:
You have reached your daily limit for code executions on StrataScratch.
Please login/register for unlimited code executions.
Expected output:
| user_id | avg_session_duration |
|---|---|
| 0 | 1852.5 |
| 1 | 35 |
Practice Question #3 (Hard): User Streaks
Write & test your solution here:
User Streaks
Last Updated: October 2022
Provided a table with user id and the dates they visited the platform, find the top 3 users with the longest continuous streak of visiting the platform as of August 10, 2022. Output the user ID and the length of the streak.
In case of a tie, display all users with the top three longest streaks.
Write & test your solution here:
You have reached your daily limit for code executions on StrataScratch.
Please login/register for unlimited code executions.
Expected output:
| user_id | streak_length |
|---|---|
| u004 | 10 |
| u005 | 10 |
| u003 | 5 |
| u001 | 4 |
| u006 | 4 |
Share