Python String Methods: Here is How to Master Them


Categories:
 Written by:
Written by:Nathan Rosidi
Explore practical examples, learn how to effectively clean and format strings, and harness the power of Python’s memory model to master string operations.
The overall idea is that most people feel that Python’s string methods are too technical to understand correctly from the beginning.
However, the reality is that all it takes is a bit of interest and some guidance to excel.
I aim to share the steps and some essential facts that might turn anyone into a relatively professional string manipulator.
Mastering String Wizardry: Starting With Fundamentals
First, I want to introduce you to the concatenation method, which stands for putting sequences of strings one after the other in a non-disconnectable manner. One classic example is the form of welcoming a user with a specific name:
Here is the code.
first_name = "Jane"
last_name = "Doe"
full_greeting = "Hello, " + first_name + " " + last_name + "!"
print(full_greeting)
Here is the output.


In this case, the + operator is the welcomed, experienced tailor who sews the fragmented string into a pleasant greeting.
As you’ve discovered, the repetition can double or even spread a single chain. While working on the fabric of the code, you can place a single chain as follows;
laugh = "ha"
full_laugh = laugh * 3
print(full_laugh)
Here is the output.


The * operator can be likened to a chorus that has repeated the string ha three times to form a gleeful expression of laughter. By combining and repeating strings, developers can forcibly handle linguistic creations as they please.
Then, at that delicate and sensitive level, devs can create even deep, intricate, and delicate overall linguistic unions.
The Art of Accessing Characters and Slicing
Another layer corresponding to the world of Python strings can be character access and slicing excavation, which are sharp tools for precisely extracting and operating substrings.
Accessing Characters: The Key to Each Element
Python string has its elements. They preserved a location described by an index, with each component having a decimal spot from 0 to the number of components in each.
Furthermore, the following is easy to obtain. All one needs to do is open the bracket and provide the index. Here is the code.
greeting = "Hello, World!"
first_character = greeting[0]
exclamation = greeting[-1]
print("First character:", first_character)
print("Last character:", exclamation)
Here is the output.

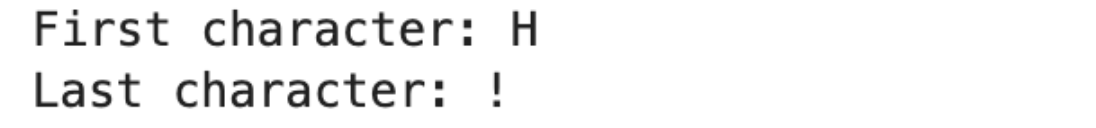
In short, the slice defined the first character and snapped the last one, using just two signs to get to it.
Slicing: Carving Out Substrings
Slicing gets a part of a string marking distinguishing points. It is characterized by its [starting point: sorting] syntax. Here’s the code:
phrase = "Hello, World!"
world = phrase[7:12]
print("Extracted substring:", world)
Here is the output.


I sliced “Hello, the world” from the above example. You can add a step using colons [start:end:step]. Thus, you can extract more complex and take more complex ones, such as reversing the order of the string or obtaining every second letter.
Strings and Python's Memory Model: A Deep Dive
Python strings are immutable. Therefore, any operation that changes a string results in the creation of a new string. By Python maintaining this behavior, it is highly linked with their memory model to maintain the efficiency and integrity of data:
original = "Hello"
modified = original + " World!"
print("Original:", original)
print("Modified:", modified)
Here is the output.


Even though it looks like it changed the original, the modified version is an entirely new string in memory. Strings' immutability is a fundamental factor in most other string manipulation operations in Python and ensures that every string remains consistent and reliable.
After learning these methods, you can better understand and work with your textual data and build on these basic principles to develop more advanced string manipulations.
String Method Mastery: Your Toolkit for Efficiency

Python string methods open a toolkit for the user to follow a hammer with functionality to quickly and effortlessly perform virtually any action with string data or inquiry.
The function is built into and already exists in any string object, and you just need to call it and use it to work with strings.
However, many methods can be used only by strings.
Nevertheless, this is not mockery but “glorification,” thanks to these methods, the user does not need to write much more code.
Exploring the Lengths with len()
The len() function is not a string method but can be used to determine the string’s length. Here is the code.
message = "Hello, World!"
print("Length of message:", len(message))
Here is the output.

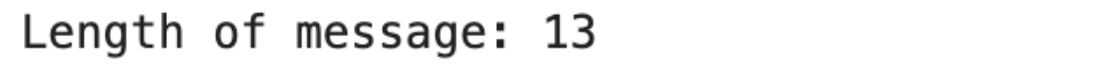
This simple invocation provides the number of characters, including spaces and punctuation, and the primary understanding of the string size.
Transforming Text with upper(), lower()
On the other hand, case transformations are done instantly with the help of several of them: upper() and lower(), and text normalization is allowed to be ready for comparison, searching, or presentation to the user.
Here is the code:
original = "Python is fun!"
print("Uppercase:", original.upper())
print("Lowercase:", original.lower())
Here is the output.


These methods make text data comparable in processing and solve all problems with case-based operations.
Cleaning Strings Perfectly with strip(), rstrip(), lstrip()
Another vital area where whitespace needs to be managed is cleaning input or preparing data for further processing. Here is the code.
noisy_data = " data with space around "
print("Stripped:", noisy_data.strip())
print("Right stripped:", noisy_data.rstrip())
print("Left stripped:", noisy_data.lstrip())
Here is the output.


Here, the strip() family of methods is unmatched in removing every piece of space not wanted. From eliminating the left and suitable spaces with strip() to simply stripping the leading or trailing spaces by using lstrip() or rstrip(), respectively, they are vital for clean string data.
Quick Wins: Brief Examples of Each Method
As you can see, python strings have numerous methods: find(), replace(), startswith(), endswith(), etc. Most of them are used for exceptional cases. Here is the code.
text = "The quick brown fox"
print("Found 'quick' at index:", text.find("quick"))
print("Replaced 'brown' with 'red':", text.replace("brown", "red"))
print("Starts with 'The':", text.startswith("The"))
print("Ends with 'fox':", text.endswith("fox"))
Here is the output.


This short review shows how expansive the string methods’ toolkit is for a user who wants to work with text data efficiently and expressively.
Now, you are armed and ready to perform numerous string-manipulating operations and begin exploring even more advanced ones.
The Search and Replace Commandos: Navigating Through Strings
Navigating and manipulating strings accurately is vital in Python, especially if your data is primarily text. Python’s string methods for searching and replacing are like a well-trained search-and-rescue squad, able to quickly locate and alter textual content with tremendous accuracy.
Mastering the Search with find(), rfind()
When it is necessary to determine the position of a substring in a string, the method find is useful. This method searches the substring from the start and returns the smallest index to this substring or -1 in case of search failure. If it is required to search from the end, you should use the method rfind():
quote = "stay hungry, stay foolish."
position = quote.find("stay")
print("First 'stay' found at position:", position)
position_r = quote.rfind("stay")
print("Last 'stay' found at position:", position_r)
Here is the output.


All these methods are essential for parsing and processing text, which enables you to navigate strings accurately.
The Art of Substitution with replace()
Besides, str.replace() is extremely valuable when changing parts of a string. This one finds a defined substring and puts a new one in place. Thus, it simply lets you renovate your text:
Here is the code.
original_message = "Hello, world!"
new_message = original_message.replace("world", "Python")
print("Updated message:", new_message)
Here is the output.


This example shows how replace() can transform content. It makes it a staple for text editing and data cleaning.
Deploying Practical Examples for Search and Replace
Now that we have learned these methods, I want to model a practice I will use to perform. For instance, we have a dataset that has not been cleaned or updated for a long time. There will be different capitalization variations and even deprecated terms.
A uniform model of these string data sources that can be analyzed will be feasible through the combination of find(), rfind(), and replace().
data_entries = ["python programming", "Python Programming", "PYTHON data analysis", "Data Science with python"]
# Standardizing capitalization and updating terminology
standardized_entries = [entry.lower().replace("python", "Python") for entry in data_entries]
print("Standardized Entries:", standardized_entries)
Here is the output.


The above approach smooths out the data, preparing it for general analysis and demonstrating how Python’s string search and replacement equipment can be used properly.
Elevating String Operations: Split, Join, and Format

Entering more profoundly into the dispersion category, Python suggests three powerful pieces of equipment: split, join, and format.
They are perfect for dispersing, joining, and designing strings, so use them to advance the appearance.
Splitting Strings Apart with split(), rsplit()
It’s always tough to split something; it is an unwritten rule. However, when it is necessary to start splitting from the end, you will become best friends with it.
For those who want to split from the end, rsplit() is your ally:
sentence = "Python is fun, versatile, and powerful."
words = sentence.split(", ")
print("Words:", words)
# When you need a limited number of splits
limited_split = sentence.split(", ", 1)
print("Limited split:", limited_split)
Here is the output.


The best use case is when you need to tokenize data, which implies splitting one large text into items containing one or several separate pieces of information.
The Unifying Force of join()
On the other hand, join() constructs an iterable of strings, such as a list, into one single string with a specified separator threaded through it. It is the adhesive holding disparate strings together. Here is the code.
words = ["Python", "is", "awesome"]
sentence = " ".join(words)
print("Sentence:", sentence)
Here is the output.


This method is especially beneficial when creating sentences, file paths, or any string that must be certain about how its components combine.
Beautifying Strings with format()
Another reasonable method is format() because it cautiously embeds variables into a string template. It is a much cleaner option while maintaining the string as a dynamic product of various merging factors. Here is the code.
user = "Jane"
tasks = 5
message = "Hello, {}. You have {} new tasks today."
print(message.format(user, tasks))
Here is the output.

format() allows madness in the form of strings and the sanity of “inserting things,” which makes it fundamental in Python string handling.
Harnessing Regular Expressions: The Ultimate String Manipulation

As string manipulation difficulties grow past basic operations, Python’s re-module becomes valuable. Python Regular expressions offer a compact and potent syntax to bridge the gap between what you can find, match, or substitute in a string, allowing you to conduct complicated text processing activities with minimal code.
Tapping into the re Module for Advanced Manipulations
The Python re-module provides tools to perform complex string manipulations using pattern matching. Below is how you may import and use the module for a basic search:
import re
text = "Find the hidden numbers: 123 and 456"
pattern = r"\d+"
# Finding all occurrences of the pattern
matches = re.findall(pattern, text)
print("Numbers found:", matches)
Here is the output.

It is such a short example; however, it illustrates findall and how you can realize the potential of regular expressions to detect patterns.
Unlocking Complex Patterns: Sample Use Cases
Regular expressions are used when you can describe the pattern you need in detail. They can validate emails, scroll logs for specific information, or clean up data. Here is the code.
# Email validation pattern
email_pattern = r"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}"
email = "example@test.com"
if re.match(email_pattern, email):
print("Valid email address")
else:
print("Invalid email address")
# Extracting dates from a log
log = "Error reported on 2023-03-15, followed by another error on 2023-03-16."
dates = re.findall(r"\d{4}-\d{2}-\d{2}", log)
print("Dates found:", dates)
Here is the output.

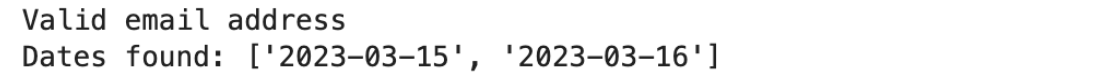
These example cases show how regular expressions are versatile to perform complex string processing tasks pertinent to our day-to-day work. For these reasons, the tool confirms that it is an essential feature for a Python programmer.
Bringing It All Together: Examples
Now let’s see one example, which includes Python string methods that we learned, from our platform.
Last Updated: June 2020
Find the number of words in each business name. Avoid counting special symbols as words (e.g. &). Output the business name and its count of words.
Here is the question: https://platform.stratascratch.com/coding/10131-business-name-lengths
In this question, the City of Francisco requires that we identify the number of words in each business’ name and exclude special symbols such as ‘&’ from what counts as a word at the end to display the business name and the number of words.
First, let’s see the dataset.
Now, let’s break down this question into multiple codable pieces;
- Remove Duplicates: Ensures each business name is unique, preventing repeated word count calculations for the same entity.
- Clean Business Names: Strips out special characters from business names, leaving only alphabets, numbers, and spaces for accurate word counting.
- Count Words: Splits the cleaned business names into words based on spaces and counts the total number of words in each name, providing the desired information about word frequency.
Now, let’s do this. Here is the code.
import pandas as pd
import numpy as np
result = sf_restaurant_health_violations['business_name'].drop_duplicates().to_frame('business_name')
result['business_name_clean'] = result['business_name'].replace('[^a-zA-Z0-9 ]','',regex=True)
result['name_word_count'] = result['business_name_clean'].str.split().str.len()
result = result[['business_name','name_word_count']]
Here are the first few rows of the output.
Conclusion
In this one, we went deep into Python's string methods, exploring the intricacies of concatenation, slicing, memory models, and more to master the art of string manipulation.
One thing that deepens your understanding is doing repetition, like we did in the previous section.
To do that, try the StrataScratch platform, and check out Python interview questions, that include string methods, and master these methods, by solving questions from interviews of big companies.
Share


