Most Common Data Science Interview Questions


The most common data science interview questions that cover several technical concepts that you'd use every day on the job.
There are usually several concepts interviewers are testing for on data science interviews but since they might only have time to ask 1-2 questions, they’ll try to pack the concepts into one question. It’s important to know what these concepts are so you can look out for them in a data science interview.
Let's cover these concepts by going through a real data science interview question.
What do recruiters test for? What are the most common data science interview questions you are expected to solve?
What an interviewer looks for is interviewee’s in-depth understanding of metric design and implementation of real-world scenarios that would be present in the data. The key phrase here is “real-world scenario”, which means that there are probably multiple edge cases and scenarios you’ll need to think through to solve the problem. There are 3 common concepts that they test to know your understanding of how to implement code that solves real-world scenarios.
Since they only have time to ask 1-2 questions in a data science interview before their time is up, you’ll often see all 3 concepts wrapped in one question. I see this question (or a version of this most common data science interview question), on almost every interview I’ve been on or given.
There are three technical concepts you need to know:
- CASE statements
- JOINs
- subqueries/CTEs
Let’s go through a real data science interview question that covers these 3 concepts and talk about them in-depth. Here is the link to a real data science interview question, follow along with me and see if you would be able to answer this question.
If you want more information on these three concepts, feel free to watch the video:
The most common data science interview question
Interview Question Date: November 2020
Find the total number of downloads for paying and non-paying users by date. Include only records where non-paying customers have more downloads than paying customers. The output should be sorted by earliest date first and contain 3 columns date, non-paying downloads, paying downloads. Hint: In Oracle you should use "date" when referring to date column (reserved keyword).
There are three concepts that will be tested in this most common data science interview question. The first concept that we'll cover is joining tables because we can see here are three tables:

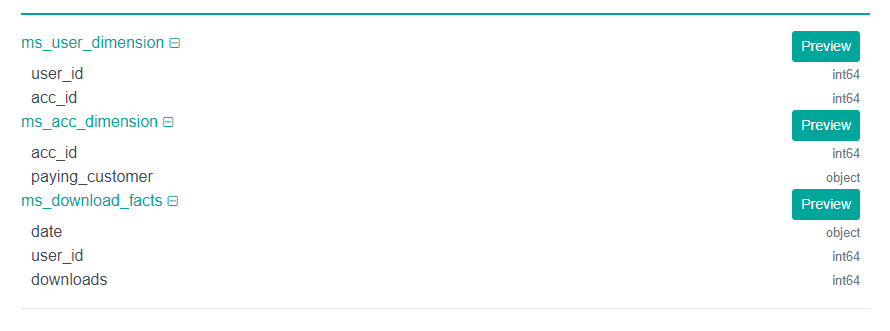
If we see multiple tables on an interview we most likely nine out of ten times have to join them some way. This is basically the lowest bar that you would need to jump over in order to be a data analyst or a data scientist.
Aggregates from CASE STATEMENTs
It is the most common that you’ll get some sort of categorization question where you need to categorize data based on values you see in the table. This is super common in practice and you’ll likely always be categorizing and cleaning up data on a data science job. A CASE statement is the simplest technique to test for. So, the CASE statement is certainly the part of most common data science interview questions.
Recruiters always test to see if you actually know what is being returned in a CASE WHEN, not just the implementation of it. Based on the CASE statements, you can always add an aggregate function like count() or sum().
Here is an example of a CASE statement with a simple aggregation in the SELECT clause for the question.
In the CASE statement below, we’re categorizing users based on if they are paying customers or not. We then apply a sum() as it’s a quick way to count the number of paying customers vs non-paying customers in one simple query. If we did not have the CASE statement, it would take us two queries to find both numbers.
SELECT
date,
sum(CASE WHEN paying_customer = 'yes' THEN downloads END)
AS paying,
sum(CASE WHEN paying_customer = 'no' THEN downloads END)
AS non_paying
FROM ms_user_dimension aJOINs
The second most common concept is JOINing the tables. Can you join tables? This is the lowest bar you need to jump over to be a data analyst, much less a data scientist. This bar is basically on the ground so you can really just step over it.
So on interviews -- do the recruiters usually do a LEFT JOIN, CROSS JOIN, or an INNER JOIN? The most common JOIN is a LEFT JOIN. Most of your work will be using a LEFT JOIN so they’re testing you based on practicality. You’ll almost never use a cross join. You’ll use an inner join quite a bit but left join is slightly more complicated so they’ll use that just like an additional filter.
Self JOINs are also common because it’s not always obvious you’d be using that. But they’re common in practice.
In the below example, we’re joining tables to the CASE statement. We’re joining two tables to our main table using a LEFT JOIN.
SELECT
date,
sum(CASE WHEN paying_customer = 'yes' THEN downloads END)
AS paying,
sum(CASE WHEN paying_customer = 'no' THEN downloads END)
AS non_paying
FROM ms_user_dimension a
LEFT JOIN ms_acc_dimension b ON a.acc_id = b.acc_id
LEFT JOIN ms_download_facts c ON a.user_id = c.user_id
GROUP BY date
ORDER BY dateSubquery/CTE
The last most common concept in data science interview questions is a subquery/CTE, basically, the concept where you do some work and then need to do more work on it. This test is to see if you can break up your problem into logical steps. Some solutions take more than one step to solve so your recruiter tests to see if you can write code that follows a logical flow. Not necessarily complicated or complex, but multi-step and pragmatic. This is the most common concept and especially useful in practice because you’ll 100% be writing code that’s over hundreds of lines long and you need to be able to create solutions that follow a good flow.
In the below example, we’re taking the query we wrote above and putting it in a subquery so that we can query its data. This way we can apply an additional filter in the HAVING clause and keep the entire solution to one query.
SELECT
date,
non_paying,
paying
FROM (
SELECT
date,
sum(CASE WHEN paying_customer = 'yes' THEN downloads END)
AS paying,
sum(CASE WHEN paying_customer = 'no' THEN downloads END)
AS non_paying
FROM ms_user_dimension a
LEFT JOIN ms_acc_dimension b ON a.acc_id = b.acc_id
LEFT JOIN ms_download_facts c ON a.user_id = c.user_id
GROUP BY date
ORDER BY date) t
GROUP BY t.date, t.paying, t.non_paying
HAVING (non_paying - paying) > 0
ORDER BY t.date ASCConclusion
These are the three most common concepts that are most likely tested during data science coding interviews. These concepts can be tested one by one or can be wrapped up into one problem or question that you would have to solve in a data science interview. They’re common concepts because they appear on the job almost every day, and to be a successful data scientist, you need to learn how to implement and code these solutions.
Latest Posts:



Share