Mastering SQL DENSE_RANK(): A Comprehensive Guide


Categories:
 Written by:
Written by:Nathan Rosidi
How do you use SQL DENSE_RANK() to rank data in SQL? This guide will help you become a master in SQL ranking window functions.
Ranking data is one of the everyday tasks in data analysis. You don’t need workarounds to rank data in SQL, as it’s made easy using several window functions.
One of them is DENSE_RANK(). To understand how it works, you first need to be familiar with the concept of SQL window functions.
Once you are, it’ll be easy to understand SQL DENSE_RANK(), how to use it, and what makes it different from other ranking window functions in SQL.
What Are SQL Window Functions?
SQL window functions allow you to perform calculations across a set of table rows that are related to the current row. This set of rows associated with the current row is called a window, hence the name.
Here’s what we mean by a window.

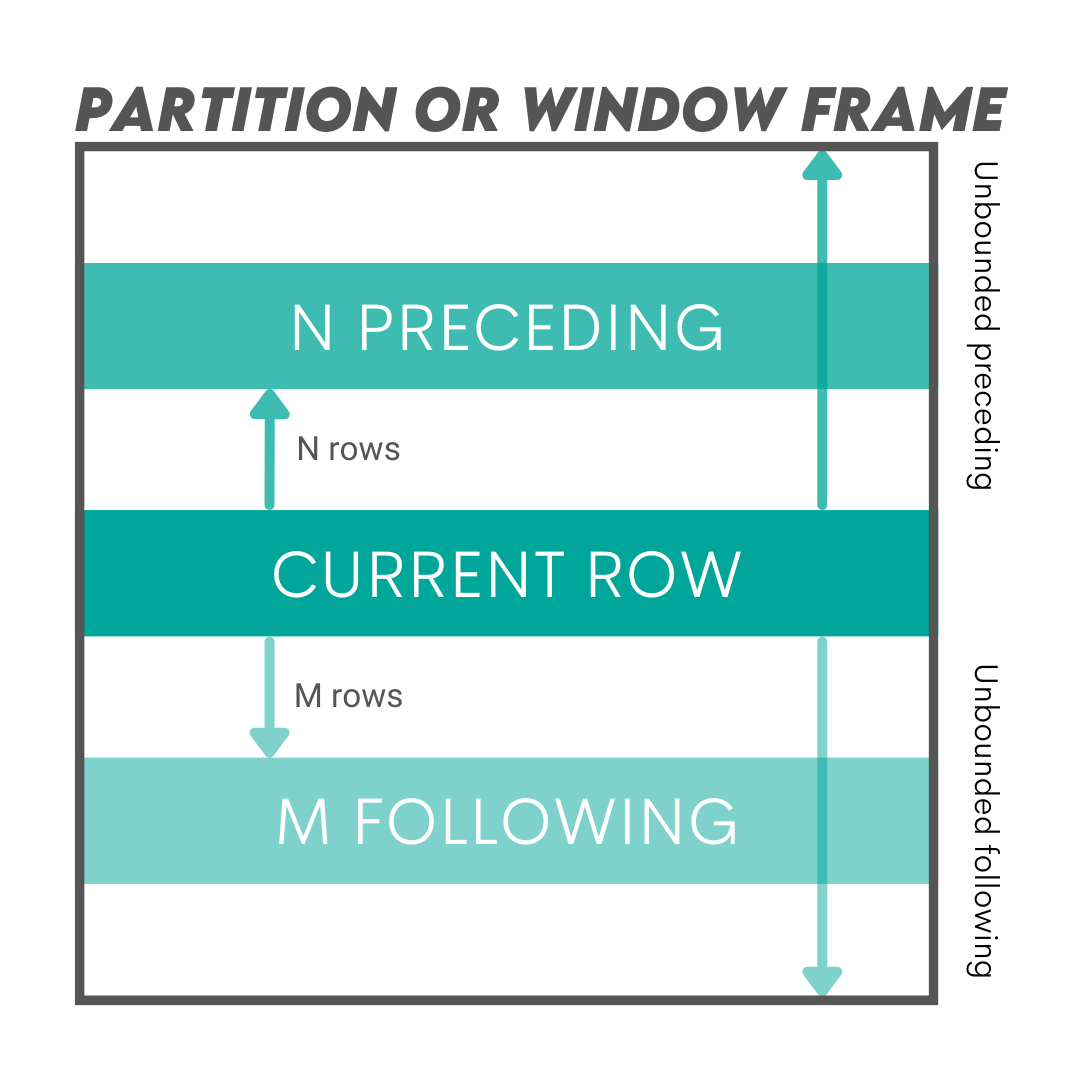
There are excellent explanations of the window functions syntax and how to define the window frame in our SQL Cheat Sheet.
Window functions are usually divided into three categories, shown below.
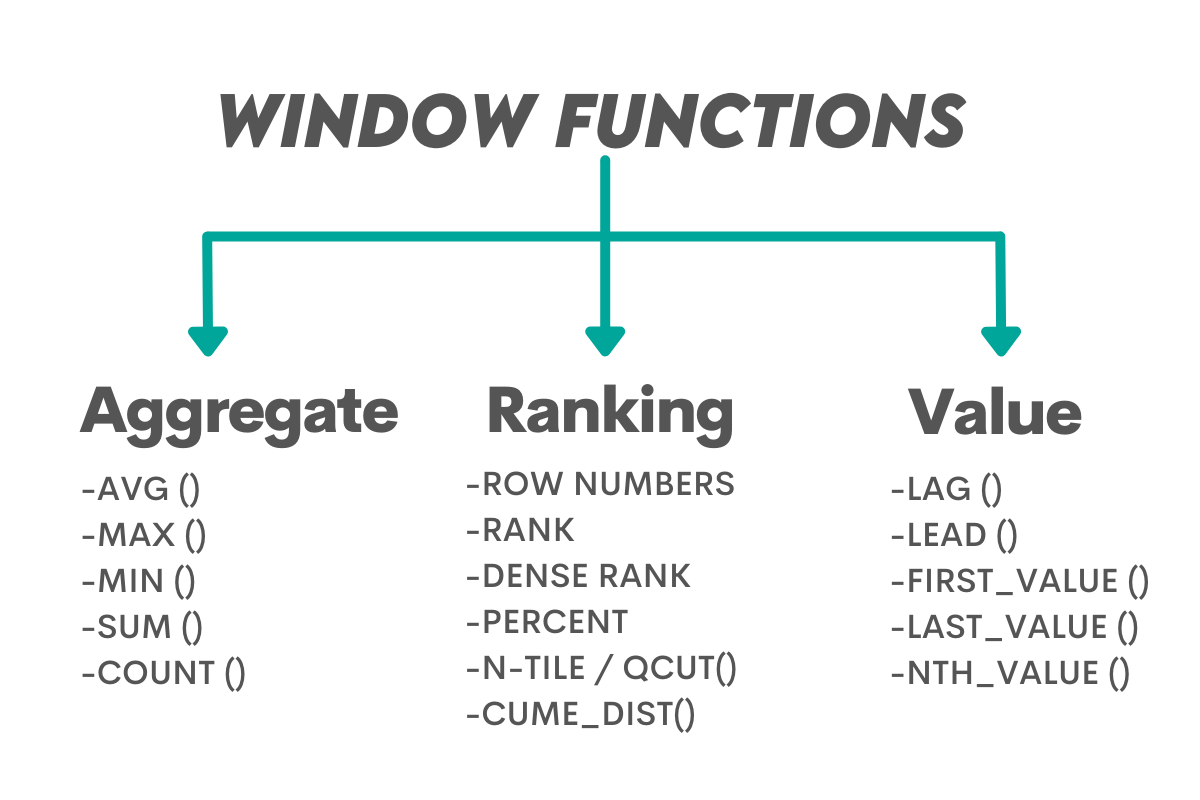
As SQL DENSE_RANK() is our main topic, it means we’ll be dealing with the ranking window functions here.
The Role of Ranking Functions in SQL
The SQL ranking functions play an essential role in analyzing and ordering datasets based on specific criteria. They help us understand data better by placing it in a particular sequence or hierarchy.
The ranking is very often used in data analysis, e.g., reports, analytics dashboards, and data visualizations. Some practical examples of ranking data are ranking employees by salary, department by the number of employees, products by sale, months/quarters/years by revenue, etc.
What is DENSE_RANK() in SQL?
DENSE_RANK() is one of the SQL rank functions that assigns a rank to each distinct row of a result set. If rows have the same value, they will be given the same rank. When the ranking gets to a new rank, there’s no gap between the rankings. In other words, it doesn’t skip rank, unlike some other ranking window functions.
Let’s see how this work in a simple table that ranks employees by their salaries.

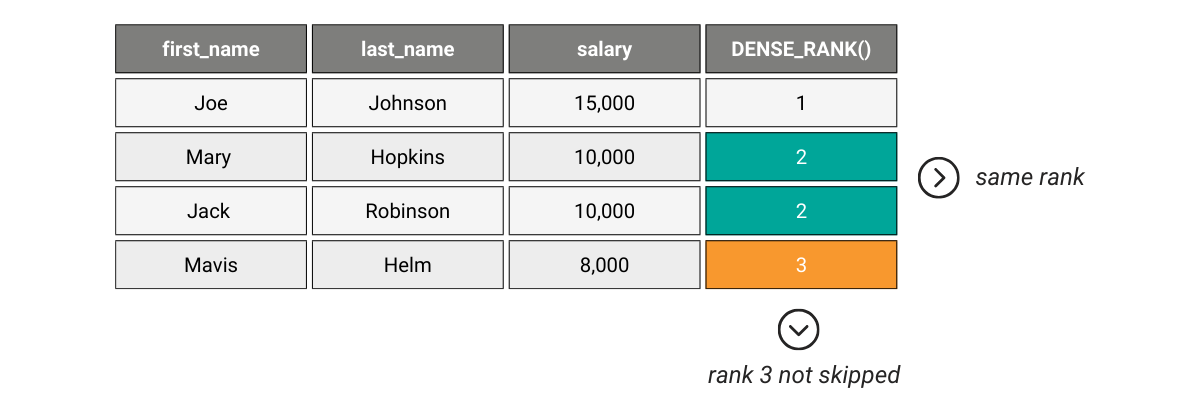
There are two employees with a salary of 10,000. DENSE_RANK() ranks them both as 2. Then the next employee is ranked as 3.
Comparing DENSE_RANK() With RANK() And ROW_NUMBER()
DENSE_RANK() is very similar to two other ranking window functions in SQL. It’s important to know each function’s features as they are not exactly the same. Here’s an overview.
- DENSE_RANK(): Assigns a unique rank to rows, duplicate values have the same rank, and there’s no rank gap after duplicates.
- RANK(): Assigns a unique rank, duplicate values have the same rank, and there is rank gap after duplicates.
- ROW_NUMBER(): Gives a unique number to each row, with even duplicate rows receiving different numbers. Duplicate values are ranked randomly, so ROW_NUMBER() may return different row numbers for the duplicates each time you run the query.
We already saw how DENSE_RANK() ranks data in a simple example. Let’s use the same example with RANK().

The employees with the same salary are ranked as 2, the same as with DENSE_RANK(). However, the next row is then ranked as 4. One rank is skipped as there’s one extra 2nd rank.
Here’s the same example with ROW_NUMBER().
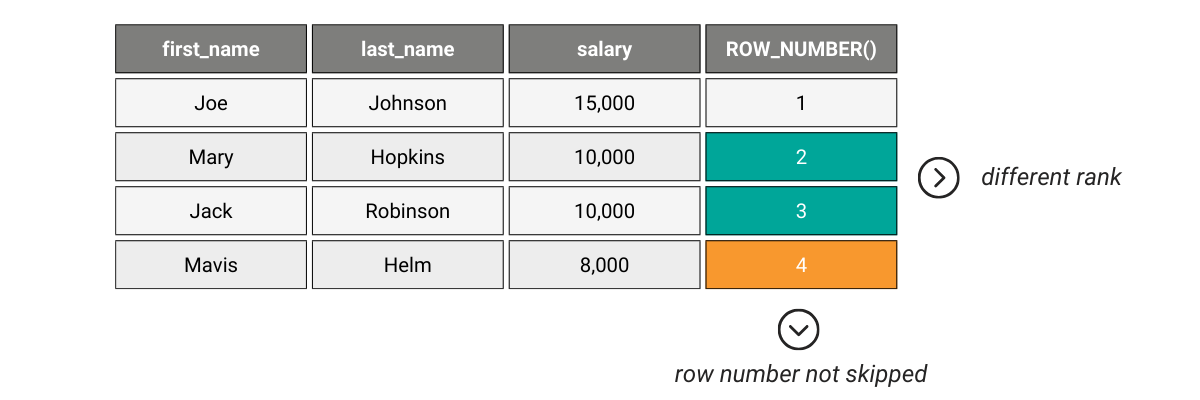
The employees with the same salary don’t have the same rank. And the next employee is ranked sequentially, i.e., the row number is not skipped.
Syntax and Usage of SQL DENSE_RANK()
Here’s the SQL DENSE_RANK() syntax.
DENSE_RANK() OVER (
[PARTITION BY partition_expression, ... ]
ORDER BY sort_expression [ASC|DESC], ...
)The PARTITION BY clause divides the dataset into partitions (data subset) and ranks rows within each partition.
The OVER() clause is a mandatory window functions clause that holds other subclauses, i.e., the instructions for the function.
The ORDER BY clause determines the order in which the rows are ranked. ASC ranks the data from the lowest to the highest value (numbers), oldest to the newest date or time, and alphabetically. DESC does the opposite: it ranks from the highest to the lowest value, date/time, or letter.
This is the window functions general syntax applied to DENSE_RANK(). If you need to revisit the general SQL window functions syntax, some excellent explanations exist in our SQL Cheat Sheet – Technical Concepts for the Job Interview.
As DENSE_RANK() ranks values in a dataset without leaving gaps in the ranking sequence for duplicate values, this feature is useful in certain scenarios.
1. When you need continuous rankings without gaps: For some analytical purposes, it’s preferable to have a continuous ranking. DENSE_RANK() provides this by ensuring that even if two rows receive the same rank, the next distinct row doesn't skip a rank number.
This is useful, for instance, if a university wants to display the top 10 students based on their final scores and there's a three-way tie for the 4th position. Without DENSE_RANK(), three students would all get the rank of 4, but the student with the next highest score would be ranked 7th.
Another example is when you want to rank the movies based on user reviews, and several movies have the same rating. Without DENSE_RANK(), three movies with an average rating of 4.5 stars will be ranked 1st, and the next highest movie (with 4.4 stars) might be ranked 4th. With DENSE_RANK(), the 4.4 stars movie would be ranked 2nd.
2. Leaderboard scenarios: Let’s say you're ranking players based on their scores. If two players have the same score and are both ranked 2nd, you might not want the next player to be ranked 4th (which would happen with the RANK() function); instead, you'd want them to be ranked 3rd.
3. When the difference in rank values is meaningful: In some analytical scenarios, the difference between rank values can be important. For example, if you want to determine the rank difference between items, gaps in the ranking can skew your analysis.
4. Handling large datasets with many duplicates: In your dataset has many duplicate values, by using DENSE_RANK(), you can prevent your dataset from having misleadingly high-rank values for rows later in the dataset.
5. Comparative studies: If you’re comparing rankings between two time periods or groups, you’d want the ranking methodology to remain consistent, especially if you're interested in the changes in rankings.
6. Data visualization: For visual presentations like charts or graphs, a continuous ranking sequence without arbitrary gaps usually leads to a clearer and more intuitive visual representation.
Real-World Examples of SQL DENSE_RANK() Function
Ranking All Rows in a Result Set
Let’s solve this question by Airbnb to see how SQL DENSE_RANK() works.
Last Updated: July 2020
Rank each host based on the number of beds they have listed. The host with the most beds should be ranked 1 and the host with the least number of beds should be ranked last. Hosts that have the same number of beds should have the same rank but there should be no gaps between ranking values. A host can also own multiple properties. Output the host ID, number of beds, and rank from highest rank to lowest.
Link to the question: https://platform.stratascratch.com/coding/10161-ranking-hosts-by-beds
The question wants us to rank each host by the number of beds they have. It says that hosts with the same number of beds should have the same rank, but there should be no gaps between ranking values. This clearly calls for using SQL DENSE_RANK().
Dataset
We’re working with the table airbnb_apartments. You can preview it below.
Solution
Here’s how to rank hosts by the number of beds.
SELECT host_id,
SUM(n_beds) AS number_of_beds,
DENSE_RANK() OVER(ORDER BY SUM(n_beds) DESC) AS rank
FROM airbnb_apartments
GROUP BY host_id
ORDER BY number_of_beds DESC;
To solve this question, we first need to find the number of beds by the host. We do that by using the SUM() aggregate function.
Then we use DENSE_RANK(). In the OVER() clause, we specify by which column we want to rank data. To do that, we use the ORDER BY clause. We rank data by the sum of beds, the same aggregation as in the previous code line. The question asks us to give the hosts with the most beds the highest rank. We achieve that by writing the DESC keyword, which will rank hosts from the highest to the lowest number of beds.
Finally, we group the data by the host ID and order it by the number of beds descendingly. That way, the first rank will be on top, which is also required by the question.
Output
The hosts are ranked. We can see some hosts with the same number of beds. They are ranked equally, and the rank for the next host is not skipped.
Ranking Rows Within a Partition
Let’s now move on to the more complex example where we need to use PARTITION BY with DENSE_RANK()
This is a question by the City of San Francisco. We need to output the top 5 least paid employees for each job title.
Find the top 5 least paid employees for each job title. Output the employee name, job title and total pay with benefits for the first 5 least paid employees. Avoid gaps in ranking.
Link to the question: https://platform.stratascratch.com/coding/9986-find-the-top-5-least-paid-employees-for-each-job-title
Dataset
We are given one table named sf_public_salaries.
Solution
The solution is a bit more complicated, so let’s break it down.
We will first list employees, their job titles, and total benefits.
In the same SELECT statement, we will use DENSE_RANK() to rank employees by benefits.
We use PARTITION BY in the OVER() clause. We partition the dataset by job title as we don’t want to rank the employees throughout the whole dataset –we want to rank employees for each job separately. We then use the ORDER BY clause to rank employees by the total benefits in ascending order because we need to find the least paid employees.
This SELECT is written as the CTE.
WITH cte AS
(SELECT employeename,
jobtitle,
totalpaybenefits,
DENSE_RANK() OVER (PARTITION BY jobtitle
ORDER BY totalpaybenefits ASC) AS pos
FROM sf_public_salaries);
Let’s see what it returns.
We get the employees ranked by total benefits for each job.
Now, we reference this CTE in the second SELECT to show only employees ranked 5 or lower. We select the required columns and filter rankings using the WHERE clause.
In the end, we just need to order by job title and benefits ascendingly.
WITH cte AS
(SELECT employeename,
jobtitle,
totalpaybenefits,
DENSE_RANK() OVER (PARTITION BY jobtitle
ORDER BY totalpaybenefits ASC) AS pos
FROM sf_public_salaries)
SELECT employeename,
jobtitle,
totalpaybenefits
FROM cte
WHERE pos <= 5
ORDER BY jobtitle,
totalpaybenefits;
Output
The result shows the required data about employees and returns only the five lowest paid at each job.
Combining Multiple Ranking Functions in a Single Query
SQL DENSE_RANK() function can also be used with other ranking function in the same query.
Let’s show how this works in the following example.
This is a question by Ring Central, but we’ll modify it a bit to demonstrate better how to use DENSE_RANK() with other ranking functions in SQL.
Last Updated: February 2021
Return the top 2 users in each company that called the most. Output the company_id, user_id, and the user's rank. If there are multiple users in the same rank, keep all of them.
Link to the question: https://platform.stratascratch.com/coding/2019-top-2-users-with-most-calls
Instead of finding the top 2 users with the most calls, we’ll just list all the users and rank them by the number of calls from each company. We’ll use DENSE_RANK(), RANK(), and ROW_NUMBER() to see how their results are different.
Dataset
We’ll work with two tables. The first one is rc_calls, and it’s a list of calls.
The second table is rc_users. It’s a list of Ring Central users.
Solution
Let’s first write a subquery.
It joins both tables we have. Then it selects the company and user ID.
After that, find the number of calls using the COUNT() function, as we want to rank by the number of calls.
First, we use DENSE_RANK(). We partition data by the company ID because we need to rank users in each company separately and rank by the number of calls descendingly.
Then we use RANK() to do the same. The syntax is completely the same; only the function's name is different.
We’ll also rank by using the ROW_NUMBER() function. Again, the same syntax; just change the name of the function.
The output of this query is grouped by the company and user ID.
SELECT company_id,
c.user_id,
COUNT(call_id) AS n_calls,
DENSE_RANK() OVER (PARTITION BY company_id
ORDER BY COUNT(call_id) DESC) AS dense_ranking,
RANK() OVER (PARTITION BY company_id
ORDER BY COUNT(call_id) DESC) AS ranking,
ROW_NUMBER() OVER (PARTITION BY company_id
ORDER BY COUNT(call_id) DESC) AS number_of_rows
FROM rc_calls c
JOIN rc_users u ON c.user_id = u.user_id
GROUP BY company_id,
c.user_id;
We are done with the most difficult part. Now, just turn this query into a subquery and list the company ID, user ID, and these three ranking columns in the main query.
SELECT company_id,
user_id,
dense_ranking,
ranking,
number_of_rows
FROM
(SELECT company_id,
c.user_id,
COUNT(call_id) AS n_calls,
DENSE_RANK() OVER (PARTITION BY company_id
ORDER BY COUNT(call_id) DESC) AS dense_ranking,
RANK() OVER (PARTITION BY company_id
ORDER BY COUNT(call_id) DESC) AS ranking,
ROW_NUMBER() OVER (PARTITION BY company_id
ORDER BY COUNT(call_id) DESC) AS number_of_rows
FROM rc_calls c
JOIN rc_users u ON c.user_id = u.user_id
GROUP BY company_id,
c.user_id) sq;
As you can see, you can simultaneously rank with all three functions. But let’s look closer at the rankings. Yes, each function returned a different ranking.
DENSE_RANK(), as expected, shows duplicate ranks with tied values and doesn’t skip the next rank.
RANK() also shows duplicate ranks. But, after that, the ranking differs from DENSE_RANK() because RANK() skips rank after ties.
ROW_NUMBER() doesn’t even have duplicate ranks: it simply goes row by row and assigns the row number sequentially without exceptions. When there are tied values, it assigns the row number randomly.
Last Updated: February 2021
Return the top 2 users in each company that called the most. Output the company_id, user_id, and the user's rank. If there are multiple users in the same rank, keep all of them.
The question is the same as in the previous example. We will again rank the users the same way, but we’ll use only DENSE_RANK(). We will also divide the output into buckets by the company ID. For that, we need another window function – NTILE().
Dataset
The dataset is unchanged from the previous example.
Solution
We’ll show the whole code immediately, as it’s mostly the same as in the earlier example.
The first difference is that we use only DENSE_RANK() to rank data. You’re familiar with this.
The second difference is the use of the NTILE() function. It’s a function that splits the result into the defined number of buckets. Again, the syntax is very similar to other functions we have used. Call the NTILE() function and write the number of buckets you want in it. In this case, it’s two. The rest of the syntax is identical to DENSE_RANK().
SELECT company_id,
user_id,
dense_ranking,
bucket
FROM
(SELECT company_id,
c.user_id,
COUNT(call_id) AS n_calls,
DENSE_RANK() OVER (PARTITION BY company_id
ORDER BY COUNT(call_id) DESC) AS dense_ranking,
NTILE(2) OVER (PARTITION BY company_id
ORDER BY COUNT(call_id) DESC) AS bucket
FROM rc_calls c
JOIN rc_users u ON c.user_id = u.user_id
GROUP BY company_id,
c.user_id) sq;
Output
The bucket column shows which column belongs to each bucket. Data for each company is split into approximately the same buckets, i.e., they have the same number of rows or close to that when the total number of rows is not even.
Avoiding Pitfalls: Common Mistakes With SQL DENSE_RANK()
SQL DENSE_RANK() isn’t that difficult, is it? Of course, when you know the SQL window functions.
However, there are some mistakes people usually make when they’re trying to get the hang of DENSE_RANK().
1. Forgetting ORDER BY: While ORDER BY is an optional clause in OVER() for some window functions, that’s not the case here. If you want DENSE_RANK() to work, you must use ORDER BY in OVER().
2. Confusion with RANK() and ROW_NUMBER(): It's vital to understand how DENSE_RANK() works, but also how it’s different from RANK() or ROW_NUMBER(). Let’s say this once again: use DENSE_RANK() when you need the same rank for all the data of the same values and without gaps in ranking.
3. Ignoring PARTITION BY: It’s not mandatory to use PARTITION BY with DENSE_RANK(). However, if you do, your analysis can become more detailed and sophisticated. Why? Remember, PARTITION BY divides data into partitions, which allows you to rank data within each partition separately (e.g., rank the employee salaries by each department). It’s important to know when to use it but also when not to use it.
Conclusion: Mastering SQL DENSE_RANK() For Efficient Data Analysis
Knowing SQL DENSE_RANK() allows you to make efficient analyses whenever you need to have continuous ranking and all the same values ranked equally. Usually, the features of DENSE_RANK() are best highlighted when compared with the other two common ranking window functions: RANK() and ROW_NUMBER().
With a clear distinction between these three functions and knowledge of when to apply them already makes you a master of ranking in SQL. Now you can interchangeably use all three functions, making you quickly adapt to the needs of your analysis.
This also comes with practice, and you can do that by solving many ranking problems in our coding questions section. Help yourself with our blog, where you can find some good articles about ranking, window functions in general, or other advanced SQL concepts.
Are you preparing for an SQL job interview? Here are all the crucial SQL interview question examples you should start with.
Share


