Mastering Row Number Handling in SQL Queries


Categories:
 Written by:
Written by:Nathan Rosidi
ROW_NUMBER() is one of the essential ranking window functions in SQL. Learn where you can use it and how it works with ORDER BY and PARTITION BY window clauses.
Anyone who works with data knows that the common task is to rank the said data. ROW_NUMBER() is a function that can do that very easily. With some additional window function clauses, ROW_NUMBER() gets even more powerful in numerous scenarios.
What is ROW_NUMBER() in SQL Queries
The SQL ROW_NUMBER() function is a window function, one of several SQL rank functions.
It assigns row numbers sequentially – no rank skipping! – so even rows with the same values (ties) will get different ranks. (Ties are ranked according to their physical order in the table.)
Syntax
Here’s the ROW_NUMBER() syntax.
ROW_NUMBER() OVER([PARTITION BY column_name] ORDER BY column_name [ASC|DESC])
The explanation is as follows:
- ROW_NUMBER(): The function name, and it doesn’t take any arguments in the parentheses.
- OVER(): Specifies the window over which ROW_NUMBER() operates; mandatory to create a window function.
- PARTITION BY: An optional clause that splits the dataset into partitions and ROW_NUMBER() restarts row counting with each partition. If omitted, there’s only one partition containing all the query rows.
- ORDER BY: A clause that defines the column(s) on which the row numbering will be based and the order in which the rows will be numbered in each partition. Generally considered a mandatory clause, however, ROW_NUMBER() can work without it in some database engines, such as PostgreSQL or MySQL. When omitted, the order of row numbers is unpredictable, i.e., it can be different whenever you run the query.
Step-by-Step Guide to Using ROW_NUMBER() in SQL Queries
I’ll start easy. Since I’ll be using PostgreSQL, I can show you an example of using ROW_NUMBER() without ORDER BY. After that, we can add it to another example and then add SQL PARTITION BY.
SQL Query ROW_NUMBER() Without ORDER BY and PARTITION BY
Let’s solve the interview question by Amazon and Bosch.
Link to the question: https://platform.stratascratch.com/coding/9859-find-the-first-50-records-of-the-dataset
We will query the table worker.
The task is to find the first 50% of the dataset's records. This is ideal for using ROW_NUMBER() without ORDER BY (and PARTITION BY), as the rows in the table will be numbered according to their physical order in such cases.
First, write a SQL CTE that will number the table rows: select all the columns from the table, write ROW_NUMBER() and the mandatory clause OVER(), with the new column alias where the row numbers will be displayed.
WITH cte AS (
SELECT *,
ROW_NUMBER() OVER() AS row_num
FROM worker
)
The CTE returns this output.
Next, write SELECT, which takes all the columns – except row_num – from the CTE. To get the first half of the dataset, filter data in WHERE: in a subquery, count the number of rows in the table worker, divide it by two, and return only data where row_num is less than or equal to the value you get from the subquery.
This is the complete solution.
WITH cte AS (
SELECT *,
ROW_NUMBER() OVER() AS row_num
FROM worker
)
SELECT worker_id,
first_name,
last_name,
salary,
joining_date,
department
FROM cte
WHERE row_num <=
(SELECT COUNT(*) / 2
FROM worker);
The output shows the first six rows of the table, which is 50% of the total records, as the worker table has 12 rows.
How SQL Query ROW_NUMBER() Interacts with ORDER BY
The ORDER BY clause sorts the data within the entire set of rows or a partition if PARTITION BY is used.
Used with ROW_NUMBER(), ORDER BY determines by which column the rows will be numbered and whether they will be numbered in ascending or descending order.
Here’s a visualization that will help you understand. The example table is named movies.

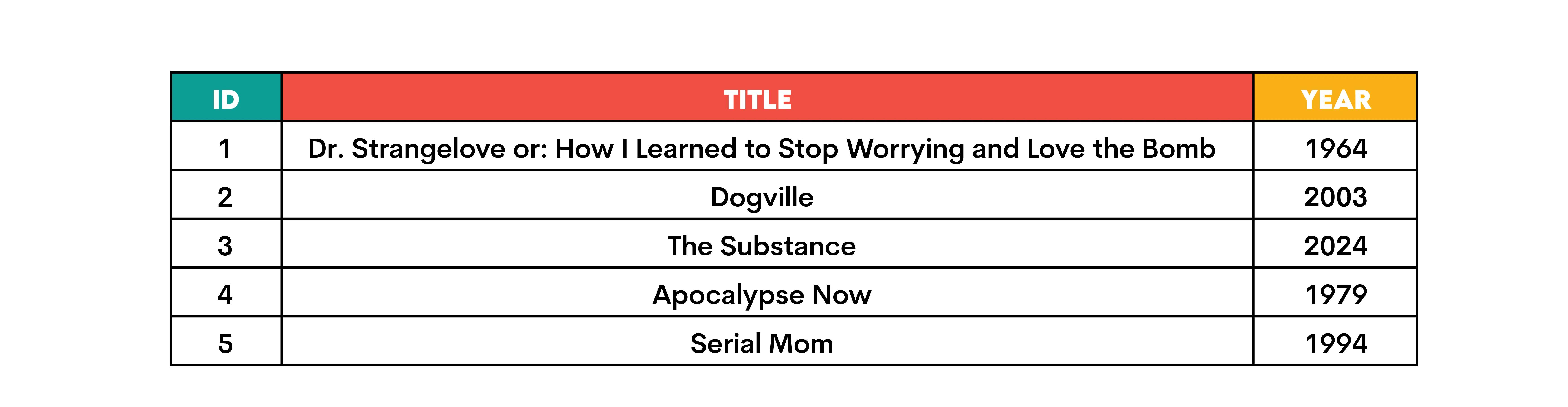
If you wanted to number the rows from the oldest to the newest movie, you would write this query.
SELECT id,
title,
year,
ROW_NUMBER() OVER(ORDER BY year ASC) AS numbering_asc
FROM movies;
This is the result you would get.

To get the row numbers the other way round (from the newest to the oldest movie), write this query.
SELECT id,
title,
year,
ROW_NUMBER() OVER(ORDER BY year DESC) AS numbering_asc
FROM movies;
Here’s the output.
Example
Let’s now take a look at the real example. Here’s an interesting task given by Meta.
Last Updated: March 2020
Meta/Facebook is quite keen on pushing their new programming language Hack to all their offices. They ran a survey to quantify the popularity of the language and send it to their employees. To promote Hack they have decided to pair developers which love Hack with the ones who hate it so the fans can convert the opposition. Their pair criteria is to match the biggest fan with biggest opposition, second biggest fan with second biggest opposition, and so on. Write a query which returns this pairing. Output employee ids of paired employees. Sort users with the same popularity value by id in ascending order.
Duplicates in pairings can be left in the solution. For example, (2, 3) and (3, 2) should both be in the solution.
Link to the question: https://platform.stratascratch.com/coding/10062-fans-vs-opposition
We need to pair the biggest fan of Meta’s new programming language with the biggest opposer, then the second biggest fan with the second biggest opposer, and so on.
The output should contain paired employees’ IDs. Also, duplicate pairings are accepted.
We’re given the facebook_hack_survey table.
The solution consists of two joined subqueries and the main query selects two columns from them.
The first subquery ranks employees from the biggest fan to the biggest hater. This is done by descendingly numbering rows by the popularity column, which is specified in ORDER BY. In addition, if the popularity score is the same, the rows will be numbered by the employee ID in ascending order.
Also, the employee_id column becomes employee_fan_id in this case.
SELECT employee_id AS employee_fan_id,
ROW_NUMBER() OVER (ORDER BY popularity DESC, employee_id ASC) AS position
FROM facebook_hack_survey;
These are the first five rows of the output.
The second subquery is very similar. It sorts employees from the biggest haters of the programming language to the biggest fans, i.e., completely the opposite of the previous subquery. So, the only difference is that the dataset is sorted by the column popularity in ascending order, i.e., from the lowest to the highest score.
We also select employee_id, only this time we name it employee_opposition_id.
SELECT employee_id AS employee_opposition_id,
ROW_NUMBER() OVER (ORDER BY popularity ASC, employee_id ASC) AS position
FROM facebook_hack_survey;
Here are the first five rows of the output.
Now, the only thing left to do is to join these two subqueries on the position column and select the columns employee_fan_id and employee_opposition_id in the main SELECT.
SELECT fans.employee_fan_id,
opposition.employee_opposition_id
FROM
(SELECT employee_id AS employee_fan_id,
ROW_NUMBER() OVER (ORDER BY popularity DESC, employee_id ASC) AS position
FROM facebook_hack_survey) AS fans
INNER JOIN
(SELECT employee_id AS employee_opposition_id,
ROW_NUMBER() OVER (ORDER BY popularity ASC, employee_id ASC) AS position
FROM facebook_hack_survey) AS opposition
ON fans.position = opposition.position;
Here’s the output.
How ROW_NUMBER() Interacts with PARTITION BY
As already mentioned, PARTITION BY splits the dataset into partitions based on the specified column(s).
If the data is partitioned, ROW_NUMBER() will number the rows in the first partition, then restart when it reaches the second partition (start again from 1), and so on.
Let’s change a bit the movies table we showed earlier.

By using PARTITION BY and ORDER BY with ROW_NUMBER(), you could rank the movies by year for each director separately.
To do that, partition data by the director and order by year.
SELECT id,
title,
director,
year,
ROW_NUMBER() OVER (PARTITION BY director ORDER BY year ASC)
FROM movies;
The query above will number the rows from the oldest to the newest movie for each director, as shown below.
To do the opposite – number the rows from the newest to the oldest movie for each director – write the following query.
SELECT id,
title,
director,
year,
ROW_NUMBER() OVER (PARTITION BY director ORDER BY year DESC)
FROM movies;
Here’s the output.
Let’s now show this in a real-case scenario.
Example
Here’s a question from the City of San Francisco interview. The task is to find the worst businesses in each year, i.e., those that have the most violations during that year. The output should contain the year, business name, and the number of violations.
Last Updated: May 2018
Identify the business with the most violations each year, based on records that include a violation ID. For each year, output the year, the name of the business with the most violations, and the corresponding number of violations.
Link to the question: https://platform.stratascratch.com/coding/9739-worst-businesses
The dataset is sf_restaurant_health_violations.
The solution is based on a subquery and a subquery of a subquery. Let’s start building the code from the bottom.
Here’s one subquery. It extracts the year of the inspection and counts the number of violations. Of course, all the rows that don’t represent violations should be excluded from the violations number count, so we exclude the NULLs.
SELECT business_name,
EXTRACT(year FROM inspection_date :: DATE) AS year,
COUNT(*) AS n_violations
FROM sf_restaurant_health_violations
WHERE violation_id IS NOT NULL
GROUP BY business_name, year;
Here are the first five rows of the output.
Next, we will write SELECT that references the subquery above. In that SELECT, we use ROW_NUMBER() to rank the businesses by the number of violations in each year. The ranking is from the highest to the lowest number of violations.
SELECT business_name,
year,
number_of_violations,
ROW_NUMBER() OVER (PARTITION BY year ORDER BY number_of_violations DESC) AS yearly_position
FROM
(SELECT business_name,
EXTRACT(year FROM inspection_date :: DATE) AS year,
COUNT(*) AS number_of_violations
FROM sf_restaurant_health_violations
WHERE violation_id IS NOT NULL
GROUP BY business_name, year) AS sq;
Here’s the partial output. As you can see, the row numbering resets when it reaches a new partition, i.e., year.
We now need to turn the above SELECT into a subquery, too, and write a SELECT that references it. That main SELECT statement selects the inspection year, business name, and number of violations.
So, the final solution is this.
SELECT year,
business_name,
number_of_violations
FROM
(SELECT business_name,
year,
number_of_violations,
ROW_NUMBER() OVER (PARTITION BY year ORDER BY number_of_violations DESC) AS yearly_position
FROM
(SELECT business_name,
EXTRACT(year FROM inspection_date :: DATE) AS year,
COUNT(*) AS number_of_violations
FROM sf_restaurant_health_violations
WHERE violation_id IS NOT NULL
GROUP BY business_name, year) AS sq
) AS sq2
ORDER BY year;
This is the query’s output. Just glancing at it is enough to realize this can’t be the solution. We wanted to output the business with the most violations during the year, but we see that, for 2015, Roxanne Cafe had five violations, but some other businesses had one.
This is obviously not right. What we need to do is filter data in WHERE, so the output shows only the rows ranked as first, i.e., having the most violations in the year.
Now, this is the final solution.
SELECT year,
business_name,
number_of_violations
FROM
(SELECT business_name,
year,
number_of_violations,
ROW_NUMBER() OVER (PARTITION BY year ORDER BY number_of_violations DESC) AS yearly_position
FROM
(SELECT business_name,
EXTRACT(year FROM inspection_date :: DATE) AS year,
COUNT(*) AS number_of_violations
FROM sf_restaurant_health_violations
WHERE violation_id IS NOT NULL
GROUP BY business_name, year) AS sq
) AS sq2
WHERE yearly_position = 1
ORDER BY year;
The output shows the years from 2015 to 2018, the businesses with the most violations in each year, and the number of their violations.
Advanced Techniques and Tips
I’ll show you three advanced SQL query ROW_NUMBER() uses.


1. Data Deduplication
Deduplicating data basically boils down to writing a query with ROW_NUMBER() then filtering only the rows ranked first in WHERE.
Example
Here’s an example of a practical application.
The question by Amazon wants you to identify the product codes of items whose unit prices are greater than the average unit prices of the product codes sold. The calculation should be based on the product code’s initial price (the price when the product first arrives in the store), on the unique product code (as the product codes will be repeated), and the output should exclude products that have been returned, i.e., the quantity value is negative.
The output should contain the product codes and their unit prices.
Last Updated: May 2023
You are given a dataset of online transactions, and your task is to identify product codes whose unit prices are greater than the average unit price of sold products.
• The unit price should be the original price (i.e., the minimum unit price for each product code). • The average unit price should be computed based on the unique product codes and their original prices.
Your output should contain productcode and unitprice (the original price).
Link to the question: https://platform.stratascratch.com/coding/2164-stock-codes-with-prices-above-average
You’re given the table online_retails.
The problem solution is based on two CTEs.
The first CTE utilizes ROW_NUMBER() to number the rows. The idea is to number the rows for each product code separately. Then, in the following CTE, we will deduplicate data by selecting only the first rows for each product, as they represent the data when the product first arrived at the store, so it contains an initial price.
So, in ROW_NUMBER(), we partition data by productcode and number the rows from the oldest to the newest invoice date. In addition, we output only rows with a positive value in the quantity column; by doing so, we exclude returned products from the output.
SELECT productcode,
unitprice,
ROW_NUMBER() OVER(PARTITION BY productcode ORDER BY invoicedate ASC) AS row_numbering
FROM online_retails
WHERE quantity > 0;
This is this CTE’s partial output.
Now, the second CTE just takes data from the first CTE and outputs only the first row for each product, i.e., when the product came into the store.
SELECT productcode,
unitprice
FROM products
WHERE row_numbering = 1
Here’s its partial output.
The final SELECT takes the output of the second CTE and compares the unit price of each product with the total average unit price of all products.
The final solution is this.
WITH products AS
(SELECT productcode,
unitprice,
ROW_NUMBER() OVER(PARTITION BY productcode ORDER BY invoicedate ASC) AS row_numbering
FROM online_retails
WHERE quantity > 0),
initial_price AS
(SELECT productcode,
unitprice
FROM products
WHERE row_numbering = 1)
SELECT productcode,
unitprice
FROM initial_price
WHERE unitprice >
(SELECT AVG(unitprice)
FROM initial_price);
2. ROW_NUMBER() With Aggregate Functions
The ROW_NUMBER() window function can also be used with aggregate functions. I’ll show you how to do it in a practical example that uses an aggregate function in ORDER BY of ROW_NUMBER().
Example
This is a question from Google.
Last Updated: July 2021
Find the email activity rank for each user. Email activity rank is defined by the total number of emails sent. The user with the highest number of emails sent will have a rank of 1, and so on. Output the user, total emails, and their activity rank.
• Order records first by the total emails in descending order. • Then, sort users with the same number of emails in alphabetical order by their username. • In your rankings, return a unique value (i.e., a unique rank) even if multiple users have the same number of emails.
Link to the question: https://platform.stratascratch.com/coding/10351-activity-rank
We need to find the email rank for each user, where the user with the most emails sent will have a rank of one, and so on. We should output the user, total number of emails, and users’ activity rank. The users with the same number of emails should be sorted alphabetically.
We will work with the table google_gmail_emails.
In the query, we select the email sender and use COUNT(*) to calculate the number of emails by the user by counting the number of rows.
We then need to rank the users by the number of emails descendingly. Luckily, we can use an aggregate function with ROW_NUMBER(), so we write COUNT(*) in ORDER BY, too. That way, we perform data aggregation and rank the data according to the data aggregation result.
An additional ranking criterion is the alphabetical order of usernames, which is the question requirement.
Finally, we group the output by the user and sort the output first from the highest to the lowest number of sent emails.
SELECT from_user,
COUNT(*) AS total_emails,
ROW_NUMBER() OVER (ORDER BY COUNT(*) DESC, from_user ASC)
FROM google_gmail_emails
GROUP BY from_user
ORDER BY total_emails DESC;
Here’s the output.
3. Result Pagination
SQL query ROW_NUMBER() is used to divide the result set for web, application, or actual book use. Again, the best way to demonstrate this is to show you a practical example.
Example
This is a hard question by Amazon and eBay, so we’ll take it slowly.
Last Updated: February 2022
You are given a table containing recipe titles and their corresponding page numbers from a cookbook. Your task is to format the data to represent how recipes are distributed across double-page spreads in the book.
Each spread consists of two pages:
⦁ The left page (even-numbered) and its corresponding recipe title (if any). ⦁ The right page (odd-numbered) and its corresponding recipe title (if any).
The output table should contain the following three columns:
⦁ left_page_number – The even-numbered page that starts each double-page spread.
⦁ left_title – The title of the recipe on the left page (if available).
⦁ right_title – The title of the recipe on the right page (if available).
For the k-th row (starting from 0):
⦁ The left_page_number should be $2 * k$.
⦁ The left_title should be the title from page $2 * k$, or NULL if there is no recipe on that page.
⦁ The right_title should be the title from page $2 * k + 1$, or NULL if there is no recipe on that page.
Each page contains at most one recipe and if a page does not contain a recipe, the corresponding title should be NULL. Page 0 (the inside cover) is always empty and included in the output. The table should ensure that all pages up to the maximum recorded page number are included, even if they contain
Link to the question: https://platform.stratascratch.com/coding/2089-cookbook-recipes
We need to show how the recipes will be distributed in the book. The output will contain these three columns: left_page_number, left_title and right_title.
The left_page_number column for the Kth row rank (counting from 0) in the output will be calculated like this.
The left_title column contains the recipe title found on the page shown in the left_page_number column. Here’s the formula.
The right_title column will show the recipe titles from the right side. Here’s the formula.
Generally, we can consider the left_page_number column as the ‘page group’ column. What I mean by that is that, even though it really is a left page number, each row will contain not only the left page data but also the right page data, i.e., recipe title. Because we are not showing the right page number, the values in the left_page_number will be every other page starting from zero, i.e., 0, 2, 4, and so on.
Additional info is that each page contains only one recipe; if the page doesn’t contain any recipe, the cell should be empty. The page 0, the internal side of the front cover, is guaranteed to be empty.
The question provides you with the table cookbook_titles.
One concept important to understand before going into code-writing is the integer division remainder.
The remainder in integer division is defined as the leftover part of the dividend after subtracting the largest possible multiple of the divisor.
Or:
For example, the remainder of the page 4 divided by 2 is this.
So, every even-numbered page (including 0) will have the remainder that is 0.
Every odd-numbered page divided by 2 gives the remainder of 1. For example:
The SQL operator for getting the division remainder is called modulo (%).
Now, we are ready to start writing the problem solution and construct it using CTEs.
The first CTE utilizes the generate_series function. This is the function that creates a virtual table containing a series of integers. The first argument in the function defines the start of the series, which is 0 in our case. The second argument specifies the end of the series. In our case, this is the highest page number, i.e., the last page from the table cookbook_titles.
We use this CTE to generate page numbers from 0 (internal side of the front cover) to the highest page number in the cookbook_titles table.
WITH series AS (
SELECT generate_series AS page_number
FROM generate_series(0,
(SELECT MAX(page_number)
FROM cookbook_titles))
),
Here’s a partial code output; the complete output goes to 15.
The second CTE LEFT JOINs the first CTE with the original dataset to get the list of all the values from the series and only the matching page numbers from cookbook_titles.
WITH series AS (
SELECT generate_series AS page_number
FROM generate_series(0,
(SELECT MAX(page_number)
FROM cookbook_titles))
),
cookbook_titles_v2 AS (
SELECT s.page_number,
c.title
FROM series s
LEFT JOIN cookbook_titles c
ON s.page_number = c.page_number
)
Here’s how the output looks so far. OK, we now have the pages and recipes one under another. This is all fine for the tabular representation. However, we need to simulate the book layout so the recipes from the same sheet (‘page group’) must be shown in the same row.
The third SELECT statement ties all the CTEs together. It utilizes ROW_NUMBER() to calculate the values in the left_page_number column by referencing the previous CTE.
There are several additional calculations, so let’s explain them.
The row numbering is done by page_number/2. Why this, why not simply page_number? Dividing it by 2 allows us to create ‘page groups’.
First, we have this calculation.
ROW_NUMBER() OVER(ORDER BY page_number/2) AS left_page_number
Here’s an example table showing what this does. The page number is divided by two, which results in every two pages belonging to the same page group. This happens because it is an integer division in SQL, i.e., the division of integers results in an integer with any remainder discarded. For example: 1/2 = 0, not 0.5. The ROW_NUMBER() function then takes the result of those calculations (column page_number/2 below) and ranks the rows according to them.

We know that the left_page_number must start from zero (the internal side of the front cover) in the final output. How do we achieve this?
We simply subtract 1 from the current ROW_NUMBER() code part and get this:
ROW_NUMBER() OVER(ORDER BY page_number/2)-1 AS left_page_number
With that subtraction, the example output looks like this, as shown in the rightmost column.


OK, the left_page_number is now equal to the page_number column. However, it still shows every page number (both left and right page numbers), but we want it to show only left page numbers, i.e., every other page starting from 0.
We do that in the following calculation by multiplying the current left_page_number with 2.
(ROW_NUMBER() OVER(ORDER BY page_number/2)-1)*2 AS left_page_number
Now, the rightmost column finally shows only the left page numbers, i.e., the values shown in green.


So, the rightmost column in the above example output looks like what we want.
OK, we can now go back to writing our last SELECT. For now, we have this.
SELECT (ROW_NUMBER() OVER(ORDER BY page_number/2)-1)*2 AS left_page_number
Next, we use SQL CASE WHEN and the string_agg() function to show the left_title and right_title values in the final output.
CASE WHEN is where you need the knowledge of the modulo operator in SQL we discussed earlier.
In the first CASE WHEN, the left title is each title from the page that returns the remainder 0 when divided by 2, i.e., the page number is 0 or an even number.
The second CASE WHEN displays recipe titles from the odd-numbered pages, i.e., when divided by 2, the remainder is 1.
However, CASE WHEN is row-specific, so it can’t combine the values of multiple rows in a group. (Remember, we consider the left_page column a ‘page group’.) So, we need string_agg(). It will concatenate all the left-page recipes into one string (with values separated by a comma) and all the right-page recipes into a second string. For string_agg() to aggregate values across all rows in a ‘page group’, the output must be grouped by page_number/2.
The complete code is shown below.
WITH series AS (
SELECT generate_series AS page_number
FROM generate_series(0,
(SELECT MAX(page_number)
FROM cookbook_titles))
),
cookbook_titles_v2 AS (
SELECT s.page_number,
c.title
FROM series s
LEFT JOIN cookbook_titles c
ON s.page_number = c.page_number
)
SELECT (ROW_NUMBER() OVER(ORDER BY page_number/2)-1)*2 AS left_page_number,
string_agg(CASE
WHEN page_number % 2 = 0
THEN title
END, ',') AS left_title,
string_agg(CASE
WHEN page_number % 2 = 1
THEN title
END, ',') AS right_title
FROM cookbook_titles_v2
GROUP BY page_number / 2;
Here’s – finally! – the output.
Comparing ROW_NUMBER() With Other Ranking Functions in SQL Queries
There are also other ranking window functions alongside ROW_NUMBER(). You can find their definitions in the table below.


The best way to explain how these functions work is to show them in an example table.
The table is named students.

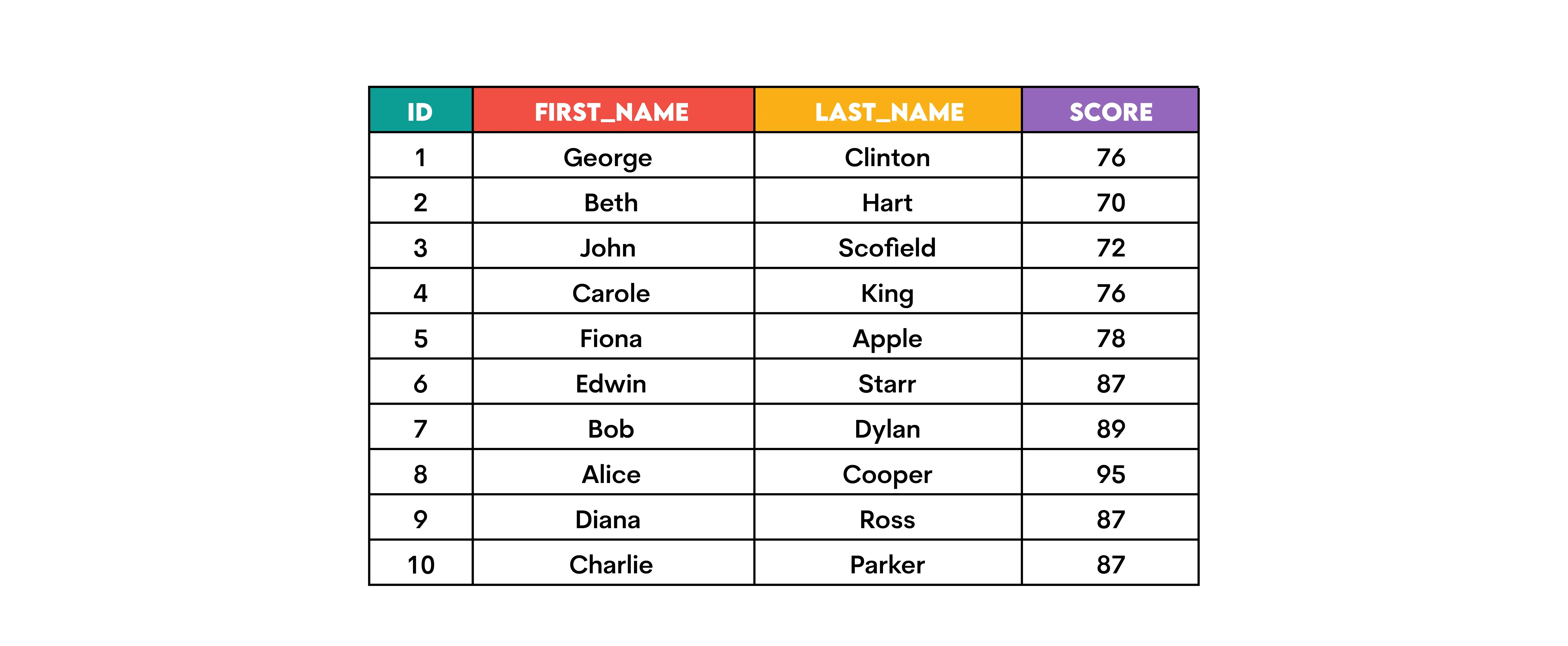
If we rank students from the highest to the lowest scores, this is how each function would do it.

I marked two sets of rows with the same scores in different colors.
As you have learned so far, ROW_NUMBER() allocates the sequential rank, irrespective of the tied values in some rows. You can see that in the example of the rows with scores of 87 and 76.
RANK(), on the other hand, assigns the same rank to the rows with the same values. However, it skips ranks when it reaches the next non-tie row. The rows where the score is 87 are all ranked 3. As there are 3 rows ranked 3, the next rank for the non-tie row is:
DENSE_RANK() works almost the same as RANK(), except it doesn’t skip ranks after tie ranks. The rows ranked as 3 by RANK() get the same rank with DENSE_RANK(). However, the next row is ranked as 4, not 6, so there’s no skipping, and the next rank is assigned.
Now, NTILE(n) works a little differently. It divides rows into the n buckets as evenly as possible and assigns a bucket number to each row. If the number of rows in the table is not even, then the rows with the lower bucket rows get extra row(s).
Our table has 10 rows. It’s divided into three buckets of three rows. However, one row is extra, so it’s added to the first bucket. In the end, the result shows that the first bucket has four rows, and the second and third buckets have three rows.
Conclusion
ROW_NUMBER() in SQL queries is a powerful tool for numbering rows with many practical applications. Mastering ROW_NUMBER() requires understanding what the ORDER BY and PARTITION BY clauses do.
The SQL query interview questions we solved are just a few of many where you can use SQL query ROW_NUMBER(). You should continue using our coding question section and experiment with other ROW_NUMBER() use scenarios. Only that way you can gain proficiency.
Share


