Mastering Loop Iterations: Python For Loop Index Explained

Categories:
 Written by:
Written by:Nathan Rosidi
Use Python's for loop index to manage data efficiently, improve performance, and ensure smoother processing, especially with large datasets or complex tasks.
Did you know that there is an effective method to control how your Python loops work?
By mastering the for loop index, you can achieve more precise, efficient, and flexible loop management.
In this article, we'll explore what it is, how to use it, and various techniques for improving your code.
What is a Python For Loop?
You might use Python For Loop to iterate over lists, tuples, strings, or any iterable object. For each element in the sequence, the loop runs the code block, offering a simple way to handle repetitive tasks.
When I first tried the for loop, I remember it made coding much smoother!
In these two sections, we’ll use datasets as a take-home assignment in the recruitment process for the data science positions at Freedom Debt Relief. Here is the link to this data project. Here are the dataset’s explanations.

Let’s say we want to print out each client’s geographical region to analyze the spread of clients across different regions. Python’s for loop makes this process straightforward. But don’t forget to limit for limited rows, or you’ll wait too long! Here is the code.
for index, row in client_data.iterrows():
print(row['client_geographical_region'])
if index == 4: # Limit to 5 rows
break
Here is the output.

This loop prints the client’s ID and age for the first five rows in the client_data.csv dataset. By using break, we control how much data is shown. But let’s see one more example.
How Does Python For Loops Work?
Have you ever noticed how Python's for loops make handling sequences a breeze? They automatically assign each element—such as a row in your dataset—to a loop variable.
You can then use this variable inside your loop for various operations on each element. Maybe you want to see how clients' ages vary. Let’s Loop through client data and print their ages. Here is the code.
for index, row in client_data.iterrows():
print(f"Client ID: {row['client_id']}, Age: {row['client_age']}")
if index == 4: # Limit to 5 rows
break
Here is the output.

This loop prints the client’s ID and age for the first five rows in the client_data.csv dataset. By using break, we control how much data is shown.
What is the Python For Loop Index?
The for loop index refers to the position of the current element in the sequence during each iteration of a for loop. Sometimes, you may want to access the index along with the value of each component while iterating. This can be useful when you need the data and its corresponding position.
Let’s look at how to use the for-loop index with the client data dataset.
Accessing the Index with range() and len()
You can easily access indices in your loops by using range() and len(). The range() function generates a sequence of numbers; len() gives you the length of your dataset.
for i in range(min(len(client_data), 5)): # Limit to 5 rows
print(f"Index: {i}, Client ID: {client_data.iloc[i]['client_id']}")
Here is the output.

In this example, range(min(len(client_data), 5)) limits the iteration to five rows. The variable i acts as the loop index. We use iloc[i] to access data at each index.
Accessing the Index with enumerate()
enumerate() is an efficient way to grab index and value during interaction. This function automatically keeps track of the index while iterating through the sequence.
# Accessing index using range() and len(), limited to 5 rows
for i in range(min(len(client_data), 5)): # Limit to 5 rows
print(f"Index: {i}, Client ID: {client_data.iloc[i]['client_id']}")
Here is the output.

Here, enumerate() gives both the index (i) and the data (row). This method is cleaner than using range() and len().
In both examples, you notice how the loop index allows access to both the index and value of each element. Give enumerate() a try; perhaps it will simplify your code as it did mine!
Accessing the Index in Python For Loops
Using range() and len()
The range() and len() combination allows us to iterate through data by index, especially when you need to perform operations based on the index itself. Let’s use the client_data to iterate over the first few clients and print their client_id and client_geographical_region using range() and len().
Here is the code.
# Accessing index using range() and len(), limited to 5 rows
for i in range(min(len(client_data), 5)): # Limit to 5 rows
print(f"Index: {i}, Client ID: {client_data.iloc[i]['client_id']}")
Here is the output.

Using enumerate()
Another efficient way to get both the index and the value during iteration is by using enumerate(). This function automatically keeps track of the index while iterating through the sequence. Here is the code.
# Accessing index using enumerate(), limited to 5 rows
for i, row in enumerate(client_data.iterrows()):
print(f"Index: {i}, Client Age: {row[1]['client_age']}")
if i == 4: # Limit to 5 rows
break
Here is the output.

Here, enumerate() gives both the index (i) and the data (row). This method is often more Pythonic and cleaner than using range() and len().
Using zip() with a Range
Another way to loop through data while accessing the index is by using zip() along with range(). This method pairs a range of indices with the rows in the dataset. Here is the code.
# Using zip() with range(), limited to 5 rows
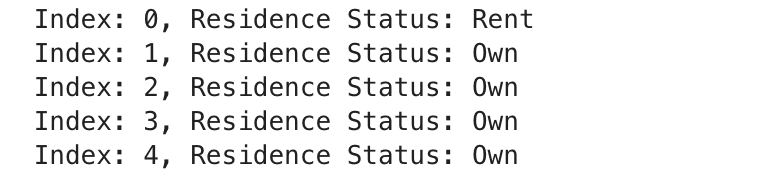
for i, row in zip(range(min(len(client_data), 5)), client_data.iterrows()):
print(f"Index: {i}, Residence Status: {row[1]['client_residence_status']}")
Here is the output.
Using List Comprehension with Index
List comprehensions are a concise way to generate lists, and they can also include the index. Let’s create a list of tuples containing the index and the client's geographical region. Here is the code.
# Using zip() with range(), limited to 5 rows
for i, row in zip(range(min(len(client_data), 5)), client_data.iterrows()):
print(f"Index: {i}, Residence Status: {row[1]['client_residence_status']}")
Here is the output.

Using itertools.count()
itertools.count() is an infinite iterator that can generate an index while iterating through the dataset. You can stop the loop at any point using conditions like break. Here is the code.
from itertools import count
# Using itertools.count() to track index, limited to 5 rows
index_counter = count()
for row in client_data.iterrows():
i = next(index_counter)
print(f"Index: {i}, Age: {row[1]['client_age']}")
if i == 4: # Limit to 5 rows
break
Here is the output.
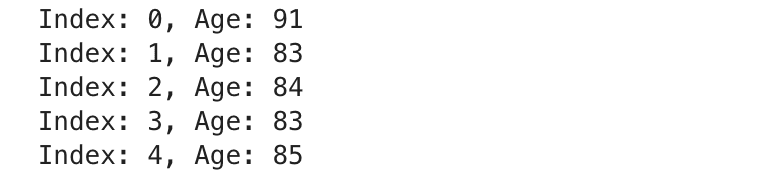
This method is proper when working with large datasets or when you want complete control over index generation.
Real-Life Problems
In many data science interviews, real-life challenges require manipulating datasets while keeping track of indices. Let’s look at how two well-known companies, Block and Meta, have used Python for loop concepts in their interviews, focusing on problems that use range() and len().
Employees With Same Birth Month- Using range() - Block
In this question, Block has asked to identify the number of employees within each department.
Employees With Same Birth Month
Last Updated: May 2023
Identify the number of employees within each department that share the same birth month. Return the result as a table with one row per department and one column per month (Month_1 to Month_12). If a month has no employees born in it within a specific department, report this month as having 0 employees. The profession column stores the department names of each employee.
Link to this question: https://platform.stratascratch.com/coding/10355-employees-with-same-birth-month
Here’s how you can solve this question using range() and Pandas in Python:
import pandas as pd
employee_list['birth_month'] = pd.to_datetime(employee_list['birthday']).dt.month
birth_month_counts_by_department = employee_list.groupby(['profession', 'birth_month']).size().reset_index(name='number_of_employees')
birth_month_counts_by_department = birth_month_counts_by_department.pivot_table(index='profession', columns='birth_month', values='number_of_employees', fill_value=0).reset_index()
birth_month_counts_by_department.columns = ['department'] + [f'Month_{month}' for month in range(1, 13)]
birth_month_counts_by_department
- The dataset has already been loaded as a pandas.DataFrame.
- print() functions and the last line of code will be displayed in the output.
- In order for your solution to be accepted, your solution should be located on the last line of the editor and match the expected output data type listed in the question.
Here is the output.
Popularity Percentage - Using len() — Meta
In this question, Meta has asked you to find the popularity percentage for each user on Meta/Facebook.
Popularity Percentage
Last Updated: November 2020
Find the popularity percentage for each user on Meta/Facebook. The dataset contains two columns, user1 and user2, which represent pairs of friends. Each row indicates a mutual friendship between user1 and user2, meaning both users are friends with each other. A user's popularity percentage is calculated as the total number of friends they have (counting connections from both user1 and user2 columns) divided by the total number of unique users on the platform. Multiply this value by 100 to express it as a percentage.
Output each user along with their calculated popularity percentage. The results should be ordered by user ID in ascending order.
Link to this question: https://platform.stratascratch.com/coding/10284-popularity-percentage
Here’s how you can solve this using len():
import pandas as pd
import numpy as np
concatvalues =len(np.unique(np.concatenate([facebook_friends.user1.values,facebook_friends.user2.values])))
revert = facebook_friends.rename(columns= {'user1':'user2','user2':'user1'})
final = pd.concat([facebook_friends, revert],sort = False).drop_duplicates()
result = final.groupby('user1').size().to_frame('count').reset_index()
result['popularity_percent'] = 100*(result['count'] /concatvalues)
result = result[['user1', 'popularity_percent']]
- The dataset has already been loaded as a pandas.DataFrame.
- print() functions and the last line of code will be displayed in the output.
- In order for your solution to be accepted, your solution should be located on the last line of the editor and match the expected output data type listed in the question.
Here is the output.
This shows how range() and len() can be used in real-world problems posed by companies like Block and Meta during data science interviews.
Each example shows how for loop indexing is a crucial tool for handling large datasets and performing calculations based on user-defined conditions.
Advanced Use Cases for Python For Loop Index
In this section, we’ll use a data project project based on a failed orders analysis for Gett, a ground transportation management platform.
The goal is to analyze failed ride orders on their platform, explicitly focusing on cancellations and rejected rides, and gain insights into what could be improved.
Here is the link to this data project.

Advanced Use Case 1: Nested Loops and Indexes
Let’s analyze how many orders were canceled by the client versus canceled by the system. We will use a for loop to iterate through the orders_data dataset and count the cancellations based on the order_status_key column.
This will involve using the index to modify elements and track the counts manually. Here is the code.
orders_data['client_cancelled'] = 0
for i, row in orders_data.iterrows():
if row['order_status_key'] == 4: # Status 4 means canceled by the client
orders_data.at[i, 'client_cancelled'] = 1
orders_data[['order_gk', 'order_status_key', 'client_cancelled']].head()
Here is the output.
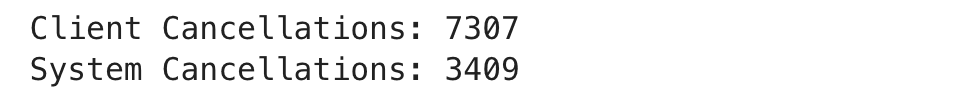
Explanation
- We use the enumerate() function to loop over the orders_data with both the index (i) and the data (row) being tracked.
- The loop increments counters based on whether the order was canceled by the client (order_status_key == 4) or by the system (order_status_key == 9).
- This method allows us to track cancellations while using the index to ensure we are correctly iterating through the data.
This approach helps us efficiently count and categorize cancellations using a for loop while manually handling the index.
Advanced Use Case 2: Modifying Elements Based on Index
Now, let’s look at how we can modify elements in the orders_data based on their status. For instance, we might want to flag orders canceled by the client (status key 4) and add a new column to mark these. Here is the code.
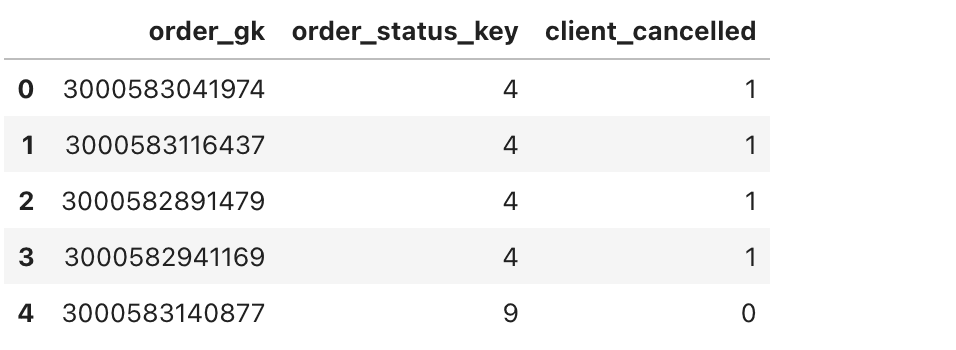
orders_data['client_cancelled'] = 0
for i, row in orders_data.iterrows():
if row['order_status_key'] == 4: # Status 4 means canceled by the client
orders_data.at[i, 'client_cancelled'] = 1
orders_data[['order_gk', 'order_status_key', 'client_cancelled']].head()
Here is the output.
Explanation
- We iterate through the orders_data and modify rows based on the index if the order was canceled by the client. A new column, client_cancelled, is added and set to 1 for these orders.
If you want to see more check these Python Interview Questions.
Performance Considerations With Loop Indexes
When dealing with massive datasets, performance becomes crucial. While for loops with indexes give you control, they're not always the most efficient with big data. Let's explore the trade-offs and when to sidestep explicit loops.
Avoiding Loops for Large Datasets
Python's for loops are user-friendly but can drag with large datasets. Alternatives like vectorized operations in pandas often run faster. Using iloc[] or at[] inside loops can be costly because pandas shine with vectorized tasks, not explicit looping.
Using enumerate() for Efficiency
If you must use it for loops, try enumerate(). It automatically tracks the index as you iterate, cutting out manual handling. This tweak can boost readability and speed.
Using apply() for Complex Operations
For more intricate operations, apply() can be a solid loop alternative. It might not always match the speed of full vectorization, but it generally outperforms explicit loops.
Key Takeaways
- Vectorized Operations: Always opt for vectorized operations when you can. They're significantly faster than for loops.
- Use enumerate(): If loops are necessary, consider using enumerate() for cleaner and more efficient index handling.
- Prefer itertuples(): For row-wise iteration, choose itertuples() over iterrows() to boost performance.
- Leverage apply(): When dealing with complex transformations, use apply() as an alternative to loops when vectorized solutions aren't feasible.
Conclusion
By efficiently using for loop indexes, you significantly enhance your ability to manipulate and analyze massive datasets. From accessing data with enumerate() to optimizing performance using vectorized operations, these techniques become essential tools in a data scientist's toolkit.
I encourage you to practice these concepts by applying them to real-world projects. Our platform offers opportunities to sharpen your Python skills further with real-world applications like interview questions and projects.
Share