Illustrated Guide About Self Join in SQL

Categories:
 Written by:
Written by:Nathan Rosidi
This illustrated guide will explain how self join in SQL works. We’ll do that on seven typical self join uses, complemented by real-world examples.
As an SQL user, you must be familiar with JOINs. They allow you to access data from two or more tables at the same time. How often would you need to do something like that? Sometimes? Often? Try “almost all the time”!
The databases rarely consist of only one table. So if you decide not to use JOINs, well, good luck with querying one table at a time.
But did you know there’s such a thing as a self-join? Now you know.
We won’t leave you only with that. This whole article is dedicated to self joins in SQL. Our approach will be to illustrate (literally!) how self-joining works. That way, it’ll be easier for you to get it. And we’ll also illustrate (metaphorically!) each distinct use of self join by practicing on real examples.
What Is a Self Join in SQL?
We started off by saying that JOINs’ purpose is to access data from several different tables.
What about the self join in SQL? The clue is in the name – self join means that you join the table with itself.
Its purpose is to use data from the same table twice, so it’s one table being self-referenced.
It is not a separate type of join – it’s just any JOIN used for joining the table with itself.
Which Data Is Queried by a Self Join in SQL?
SQL self join is most typically used to query hierarchical data structures. However, remember that any table can be self-joined, not necessarily the one representing hierarchical data.
The hierarchical data consists of items with a hierarchical relationship between them, resulting in a tree structure. Think of a company organizational structure where you want to find the direct superior of each employee. Or a family tree, which can be used to find the ancestors or descendants.
The hierarchical data consists of:
- Root node – the first node in the hierarchy
- Parent node – node with one or more subordinated nodes
- Child node – a node that has a superior node
It could be represented this way.

Remember that, depending on the hierarchical levels, child nodes can also be parent nodes at the same time.
The hierarchical data is not only queried by self joins. This can also be done using the SQL CTEs and recursive CTEs.
For self join, there’s no need to go deeper into hierarchical data structures. Mainly because, even though it’s typical, it’s not necessary for the self joined table to be a hierarchical data structure. If you’re interested in discovering more about them, we direct you to Microsoft’s article about hierarchical data in SQL.
How Does a Self Join Work in SQL?
As mentioned, self join occurs when one table is joined with itself. In the standard depiction of joins, it could be represented this way.

Let’s see what that means in practice. Here we have an organizational structure of the famous e-learning company AcrobataScratch.

This is a hierarchical data structure, as we learned. How can this structure be translated into a table? With the help of a primary (PK) and a foreign key (PK).
Remember, PK and FK are usually used for joining one table with another. Well, this time, we’re joining the table with itself, so both keys are in one table.
One hierarchical data characteristic is that a primary key (PK) and a foreign key (FK) are referencing the same table.
Again, it’s not necessary to compare two columns of one table for it to be a self join in SQL. As you will see in the examples from our platform, SQL self join can equally successfully be used on non-hierarchical data for comparing the same column of the same table.
Now, let’s get back to our AcrobataScratch example. The above organizational structure translates into this table.
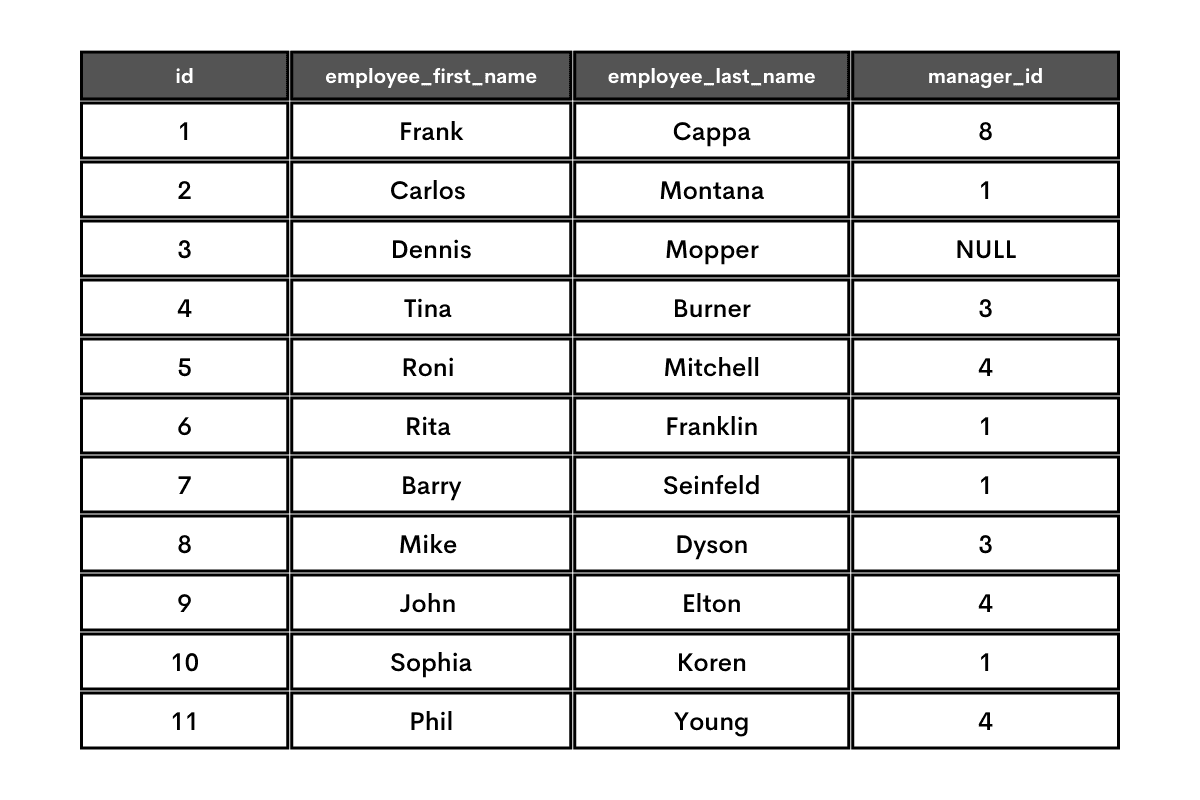
This table is typical for wanting to find the direct boss of each employee. The manager_id shows the ID of the employee that is a boss to a current row’s employee. If there are NULL values, it means this employee has no boss, i.e., he’s the boss of the bosses, the ultimate boss, the Shao Kahn of the company.
To find each employee’s boss's name, you have to self join the table on the condition that PK = FK.
This is illustrated below.

This shows that, for example, Frank Cappa is the boss to four employees, marked in blue. His boss is an employee with the ID = 8, i.e., Mike Dyson.
Dennis Mopper is a boss to two employees marked in yellow. He doesn’t have a boss, as there is a NULL in the manager_id column.
You can interpret the rest of the table following the same logic.
When such a table is self-joined where PK = FK, it results in this.
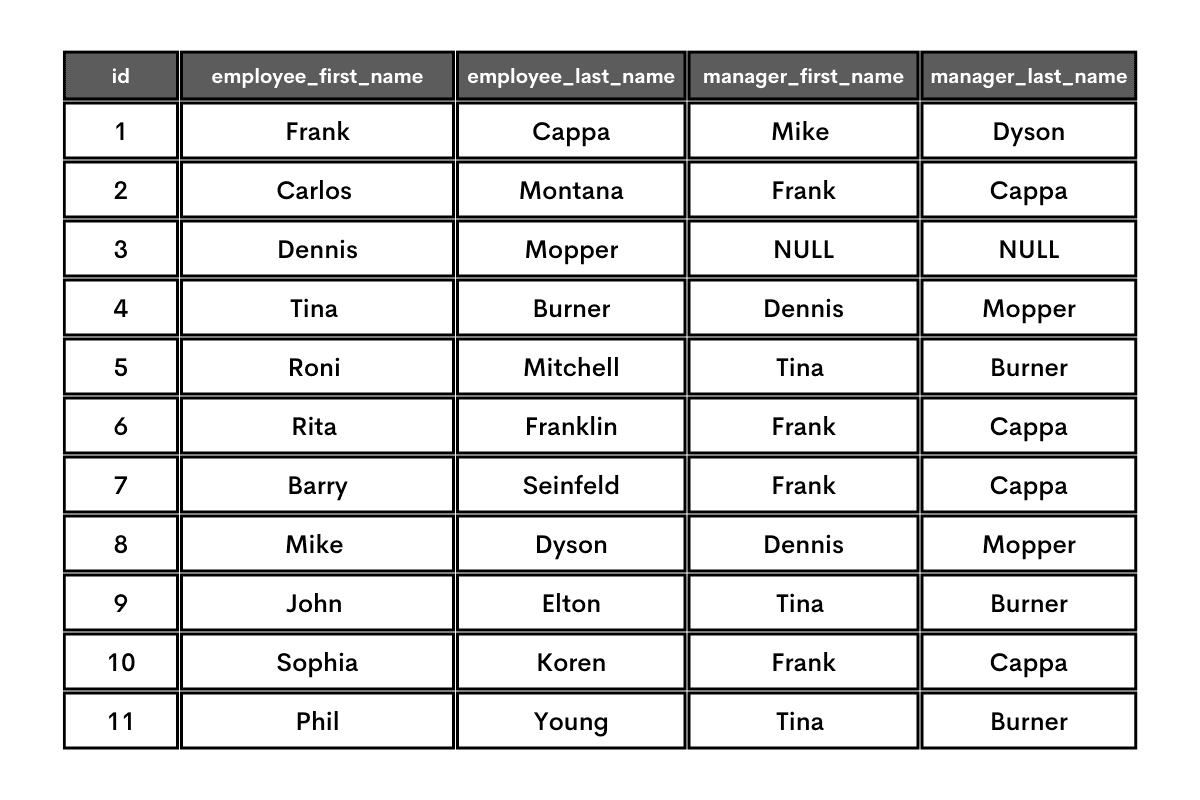
There you have it; the list of all employees and their bosses.
We want to achieve this in SQL, so we need to know the SQL syntax for self join.
SQL Self Join Syntax
We mentioned that self join is not a particular type of join in SQL. This means joining the table with itself works with any join you’re familiar with:
- (INNER) JOIN
- LEFT (OUTER) JOIN
- RIGHT (OUTER) JOIN
- FULL (OUTER) JOIN
- CROSS JOIN
It means you can use any JOIN and then reference the same table twice: in FROM and join type keyword of your choosing.
If you need to refresh your knowledge about JOINs, here’s the Types of SQL JOINs article.
The syntax on the example of JOIN is:
SELECT …
FROM table_1 AS t1
JOIN table_1 AS t2
ON …;
One important note is that giving table aliases is mandatory here. As we join a table with itself, we have to give different aliases so the query knows which table the columns in SELECT and ON are from. Basically, you’re doing the regular JOIN, but you’re treating one table like these are two distinct tables in JOIN.
The condition in ON reflects that, as the condition is comprised of the column(s) from the ‘first’ table and the column(s) from the ‘second’ table.
This is a general syntax used whenever you want to self join a table in SQL. Let’s now see the different applications of self join on the examples from our platform. We’ll have to write plenty of code, which is the best way to practice syntax.
Let’s Practice SQL Self Join With Real Examples
We’ll go through seven examples that show different sides of a self join. We start off with self join using INNER JOIN.
Using SQL Self Join With INNER JOIN
JOIN or INNER JOIN is an inner join type that returns only the matching rows from the tables you join.
Using the typical Venn diagram representation of joins, it looks like this.
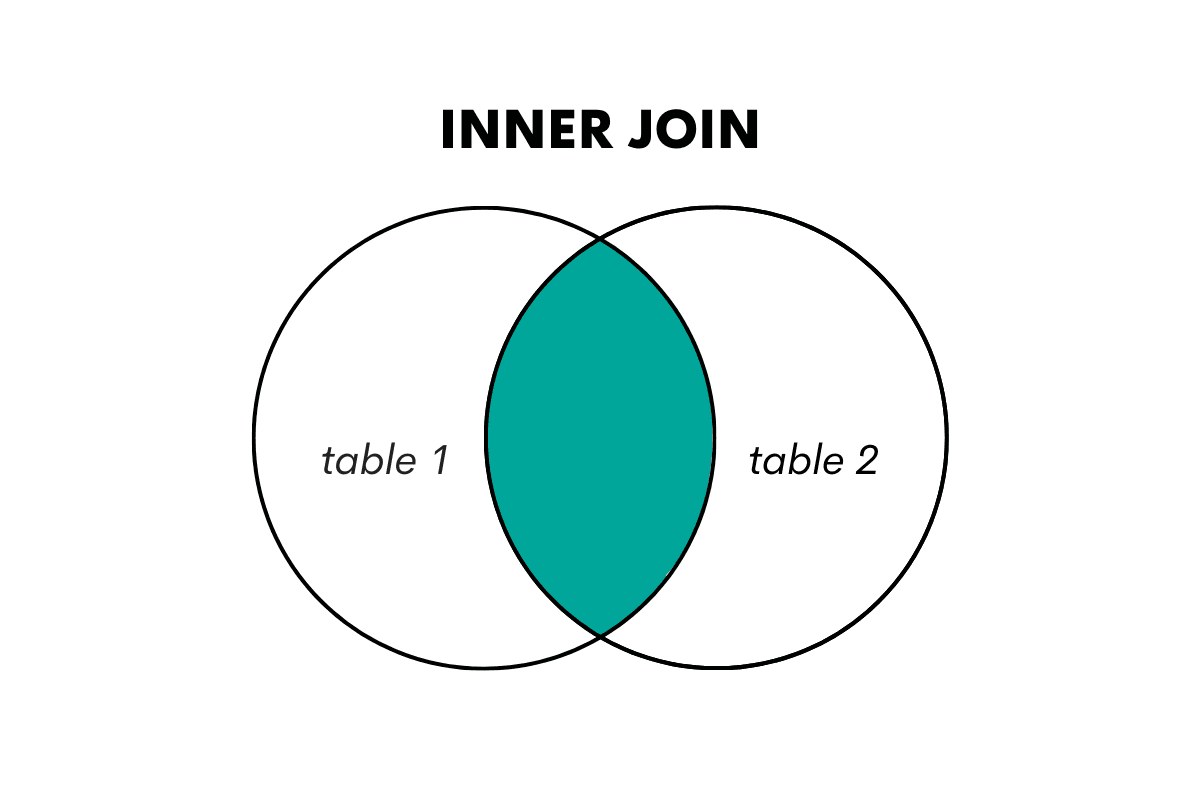
Illustration
Before jumping to writing a code, let’s remind ourselves how INNER JOIN works when joining two actual tables. Then we’ll use it to self join the table.
There is an example code and what it returns when the two example tables are joined.

The resulting table misses one row from the table customers, as Yolanda Magellan’s value in country_id is 6; there are no such values in the table countries.
Also, the USA is missing from the result table, as there are no customers where country_id is 5, so the row couldn’t be matched.
Practice Example: Finding User Purchases
Finding User Purchases
Last Updated: December 2020
Identify returning active users by finding users who made a second purchase within 1 to 7 days after their first purchase. Ignore same-day purchases. Output a list of these user_ids.
Link to the question: https://platform.stratascratch.com/coding/10322-finding-user-purchases
Dataset
The question provides the table amazon_transactions.
The dataset lists the Amazon transactions. Considering that, the column id is unique. Another important thing to notice is that the column user_id is not unique, as one user can have multiple transactions. At least, Amazon is hoping for that.
Code
Let’s start explaining the solution by examining how the table is self-joined.
SELECT *
FROM amazon_transactions a1
JOIN amazon_transactions a2;
We reference the table in the FROM clause, giving it the alias a1. After that, we JOIN it with itself and give the ‘second’ table alias a2. It’s like we already mentioned – treat one table like two tables, as you would always when using JOIN.
The tables are joined on several conditions. The first condition is where the user IDs are equal.
…
ON a1.user_id=a2.user_id
…;
Since we’re joining on the user ID, there will be a lot of rows with the same transaction ID.
| id | user_id | item | created_at | revenue | id | user_id | item | created_at | revenue |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 109 | milk | 2020-03-03 | 123 | 1 | 109 | milk | 2020-03-03 | 123 |
| 1 | 109 | milk | 2020-03-03 | 123 | 26 | 109 | bread | 2020-03-22 | 432 |
| 1 | 109 | milk | 2020-03-03 | 123 | 40 | 109 | bread | 2020-03-02 | 362 |
| 2 | 139 | biscuit | 2020-03-18 | 421 | 2 | 139 | biscuit | 2020-03-18 | 421 |
| 2 | 139 | biscuit | 2020-03-18 | 421 | 9 | 139 | bread | 2020-03-30 | 929 |
For example, the user ID 109 is here shown three times, as the transaction ID 1 is joined with itself, and also with the transactions ID 26 & 40. This will then be repeated with those two transactions. In other words, all the transactions of one user from one table will be joined with all the transactions of the same user from the second table.
We want to cut those duplications, so we add a second condition.
…
AND a1.id <> a2.id
…;
This condition will allow us to join one user’s transaction with other transactions, but not with the same transaction. The output now looks slightly different.
| id | user_id | item | created_at | revenue | id | user_id | item | created_at | revenue |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 109 | milk | 2020-03-03 | 123 | 26 | 109 | bread | 2020-03-22 | 432 |
| 1 | 109 | milk | 2020-03-03 | 123 | 40 | 109 | bread | 2020-03-02 | 362 |
| 2 | 139 | biscuit | 2020-03-18 | 421 | 9 | 139 | bread | 2020-03-30 | 929 |
| 3 | 120 | milk | 2020-03-18 | 176 | 25 | 120 | biscuit | 2020-03-21 | 858 |
| 3 | 120 | milk | 2020-03-18 | 176 | 39 | 120 | milk | 2020-03-27 | 793 |
Compared with the previous output, this partial output shows only two rows of the user 109, as its transaction ID 1 is only joined with the other two remaining transactions – ID 26 & 40.
The third condition applies a definition of a returning user, provided by the question: “A returning active user is a user that has made a second purchase within 7 days of any other of their purchases.”
This means if the purchase is made after 7 days, this user is not considered a returning user.
That’s why the third joining condition is written like this.
…
AND a2.created_at::DATE-a1.created_at::DATE BETWEEN 0 AND 7
…;
The transaction dates from ‘both’ tables are converted to date data type and then subtracted, with a condition to show only the difference equal or less than 7.
The output is even further trimmed down, with the example of the first five rows given below.
| id | user_id | item | created_at | revenue | id | user_id | item | created_at | revenue |
|---|---|---|---|---|---|---|---|---|---|
| 3 | 120 | milk | 2020-03-18 | 176 | 25 | 120 | biscuit | 2020-03-21 | 858 |
| 6 | 103 | bread | 2020-03-29 | 862 | 22 | 103 | milk | 2020-03-31 | 290 |
| 10 | 141 | banana | 2020-03-17 | 812 | 68 | 141 | bread | 2020-03-21 | 118 |
| 16 | 122 | bread | 2020-03-06 | 593 | 7 | 122 | banana | 2020-03-07 | 952 |
| 17 | 128 | biscuit | 2020-03-24 | 160 | 36 | 128 | milk | 2020-03-28 | 498 |
Now, we don’t need all these columns. The question wants us to output only the list of users. Because of that, we select the user ID from the first table. We also use the DISTINCT clause, as the output should have no duplicates.
Additionally, we order data by user ID.
The complete code now looks like this.
SELECT DISTINCT(a1.user_id)
FROM amazon_transactions a1
JOIN amazon_transactions a2
ON a1.user_id=a2.user_id
AND a1.id <> a2.id
AND a2.created_at::DATE-a1.created_at::DATE BETWEEN 0 AND 7
ORDER BY a1.user_id;
You have reached your daily limit for code executions on StrataScratch.
Please login/register for unlimited code executions.
Run the code to see if the below several output rows are the same.
| user_id |
|---|
| 100 |
| 103 |
| 105 |
| 109 |
| 110 |
| 111 |
| 112 |
| 114 |
| 117 |
| 120 |
| 122 |
| 128 |
| 129 |
| 130 |
| 131 |
| 133 |
| 141 |
| 143 |
| 150 |
Using SQL Self Join With LEFT JOIN
The LEFT JOIN or LEFT OUTER JOIN is an outer type of join that returns all the rows from the left table and only the matching rows from the right one.
‘Left’ here is the table in FROM, ‘right’ is the written after LEFT JOIN.
When there are no matching rows in the right table, the values will be shown as NULL.
You can visualize LEFT JOIN like shown below. And if you’re interested in this topic, go to our LEFT JOIN vs LEFT OUTER JOIN article.

Illustration
Here’s how LEFT JOIN would work in our illustration example.

The above illustration shows that the result table contains all the rows from the table customers. There are NULL values in the fifth row. This means there’s no country with ID = 6, but the query still showed all the data from the table customers. Again, the USA is missing for the same reason as earlier.
Practice Example: Finding User Purchases
We will use the same interview question from Amazon as earlier to practice LEFT JOIN.
Code
Let’s use the previous solution with LEFT JOIN. The code stays exactly the same except for the type of join.
The left table here is a1, and the right table is a2.
SELECT DISTINCT(a1.user_id)
FROM amazon_transactions a1
LEFT JOIN amazon_transactions a2
ON a1.user_id=a2.user_id
AND a1.id <> a2.id
AND a2.created_at::DATE-a1.created_at::DATE BETWEEN 0 AND 7
ORDER BY a1.user_id;
You have reached your daily limit for code executions on StrataScratch.
Please login/register for unlimited code executions.
If you run the code, you’ll get the same output as below.
| user_id |
|---|
| 100 |
| 101 |
| 102 |
| 103 |
| 104 |
The code works, of course. However, if you hit the ‘Check Solution’ button, you’ll see that it doesn’t return the correct result.
LEFT JOIN is not the correct choice for solving this challenge, at least not without further changes. The reason is it returns all the rows from the table a1 and only the matching rows from the table a2. This doesn’t reflect the requirements of the question since, for sure, it’s not probable that all the users from the left table can be categorized as returning.
There’s a way to make LEFT JOIN work here. This, however, requires using WHERE, which we’ll explain soon. And we’ll do that exactly by making LEFT JOIN work as a self-join solution for this interview question.
Using SQL Self Join With RIGHT JOIN
RIGHT JOIN or RIGHT OUTER JOIN is an outer join type that is the mirror image of LEFT JOIN: it fetches all the data from the right table and only the matching rows from the left table.
The non-matching rows from the left table are shown as NULLs.
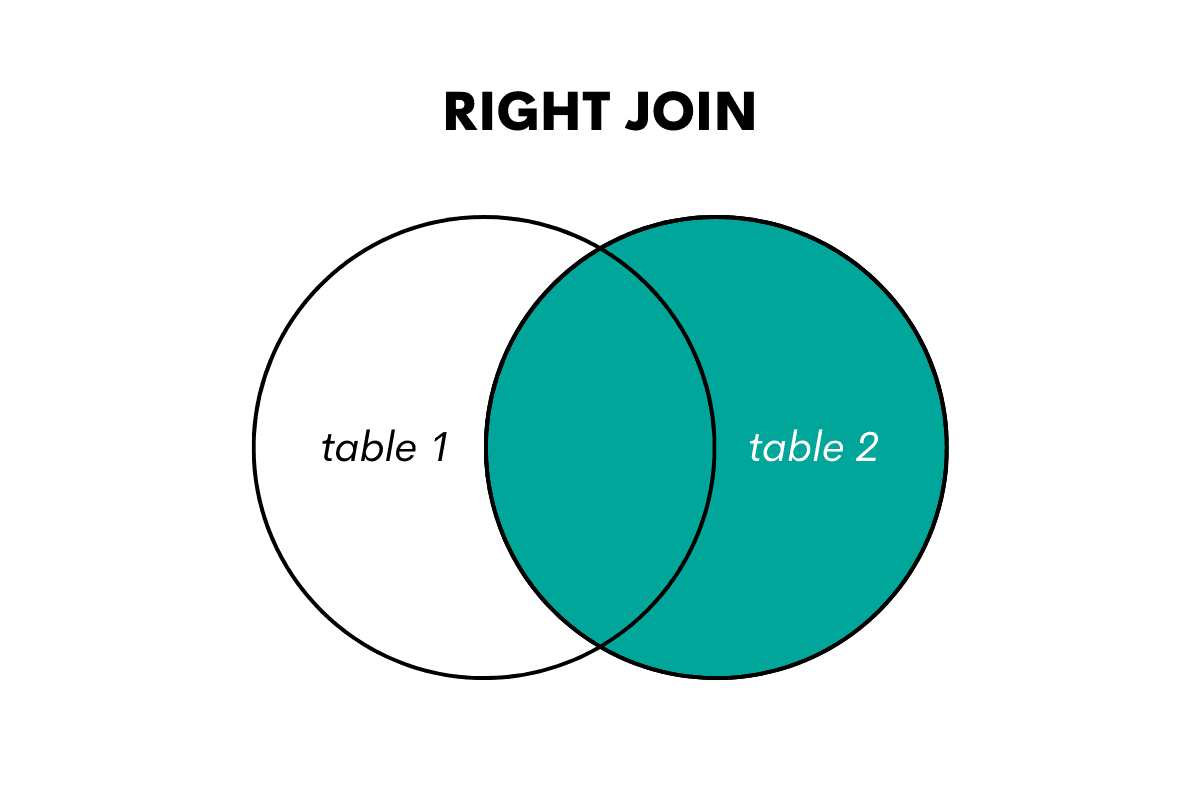
Illustration
The below illustration shows how this works with actual tables.

The result here is almost the same as with LEFT JOIN. The only difference is there is the USA from the table countries. But what is missing is Yolanda Magellan from the table customers. The reason? There’s no country in the table countries where ID is 6.
Practice Example: Finding User Purchases
We keep on practicing on the same example.
Code
We again take the previous code and simply change the join type to RIGHT JOIN.
SELECT DISTINCT(a1.user_id)
FROM amazon_transactions a1
RIGHT JOIN amazon_transactions a2 ON a1.user_id=a2.user_id
AND a1.id <> a2.id
AND a2.created_at::DATE-a1.created_at::DATE BETWEEN 0 AND 7
ORDER BY a1.user_id;
You have reached your daily limit for code executions on StrataScratch.
Please login/register for unlimited code executions.
The interesting thing will happen. Hit the ‘Check Solution’ button to see it. The query will return all the right users, completely the same as in the solution. However, the code still isn’t regarded as correct, unfortunately. Why? Because there’s one row at the bottom with all NULL values. Why does it appear? Because NULLs represent all the rows where the joining conditions are not satisfied. As NULL is also a value (it’s not the same as blank!), it will appear as a distinct value (remember, we used DISTINCT).
So, we got closer to the result, but we’re not quite there yet.
| user_id |
|---|
| 100 |
| 103 |
| 105 |
| 109 |
| 110 |
As our next topic is using WHERE when self-joining, we will use this opportunity to show how we can rework RIGHT JOIN and LEFT JOIN so they work as a solution.
Using SQL Self Join With WHERE Clause
The WHERE clause in SQL filters the output before aggregation. The SQL query takes the condition from WHERE, evaluates it against the data, and returns only the result that satisfies the stated condition.
When writing an SQL statement, you have to remember that WHERE comes before GROUP BY, HAVING, and ORDER BY.
Illustration
Let’s use the INNER JOIN illustration and amend the INNER JOIN with WHERE.

The result shows there’s one row missing from the result table. It’s John Page from the United Kingdom who was excluded from the result, as his country’s ID is 1.
Practice Example: Finding User Purchases
Now, let’s see how WHERE works when self joining in practice. We will use the same Amazon interview question as earlier as we attempt to make RIGHT JOIN and LEFT JOIN work as a solution.
Code
Let’s start off with RIGHT JOIN. We ended with this code that got us so close to the solution.
SELECT DISTINCT(a1.user_id)
FROM amazon_transactions a1
RIGHT JOIN amazon_transactions a2 ON a1.user_id=a2.user_id
AND a1.id <> a2.id
AND a2.created_at::DATE-a1.created_at::DATE BETWEEN 0 AND 7
ORDER BY a1.user_id;
Remember, this code also returns one row with NULL values. All the other rows are the same as in the accepted solution.
So you simply need to use WHERE and exclude the user ID with NULLs from the result.
SELECT DISTINCT(a1.user_id)
FROM amazon_transactions a1
RIGHT JOIN amazon_transactions a2 ON a1.user_id=a2.user_id
AND a1.id <> a2.id
AND a2.created_at::DATE-a1.created_at::DATE BETWEEN 0 AND 7
WHERE a1.user_id IS NOT NULL
ORDER BY a1.user_id;
You have reached your daily limit for code executions on StrataScratch.
Please login/register for unlimited code executions.
Hit the ‘Check Solution’ button to see for yourself.
| user_id |
|---|
| 100 |
| 103 |
| 105 |
| 109 |
| 110 |
| 111 |
| 112 |
| 114 |
| 117 |
| 120 |
| 122 |
| 128 |
| 129 |
| 130 |
| 131 |
| 133 |
| 141 |
| 143 |
| 150 |
Now, how do you do that for LEFT JOIN?
When we used RIGHT JOIN, we used the column a1.user_id (from the left table!) in SELECT DISTINCT, WHERE, and ORDER BY.
Remember, LEFT JOIN and RIGHT JOIN are mirror images. So, to make LEFT JOIN work, just take the above query and put the column a2.user_id (from the right table!) in SELECT DISTINCT, WHERE, and ORDER BY.
In simple words, just use the user ID from another table.
SELECT DISTINCT(a2.user_id)
FROM amazon_transactions a1
LEFT JOIN amazon_transactions a2 ON a1.user_id=a2.user_id
AND a1.id <> a2.id
AND a2.created_at::DATE-a1.created_at::DATE BETWEEN 0 AND 7
WHERE a2.user_id IS NOT NULL
ORDER BY a2.user_id;
You have reached your daily limit for code executions on StrataScratch.
Please login/register for unlimited code executions.
Hit the ‘Check Solution’ and see for yourself if this works.
| user_id |
|---|
| 100 |
| 103 |
| 105 |
| 109 |
| 110 |
| 111 |
| 112 |
| 114 |
| 117 |
| 120 |
| 122 |
| 128 |
| 129 |
| 130 |
| 131 |
| 133 |
| 141 |
| 143 |
| 150 |
Using SQL Self Join With ORDER BY Clause
You already used ORDER BY in the previous examples, and you probably didn’t even notice. That’s because ORDER BY has no influence on how you join the table with itself.
ORDER BY has, however, an impact on the output, so let’s recap it. The ORDER BY clause is used for sorting the result of the SQL query. There are two possibilities – sorting ascendingly and descendingly.
How do you do that? Just use the keywords ASC (or omit it, as this is a default setting) or DESC after specifying the column(s) in ORDER BY.
Remember that ORDER BY is often the last clause in the SQL query – it comes after WHERE, GROUP BY, and HAVING.
Illustration
Let’s again take the INNER JOIN illustration and add ORDER BY.

This illustration demonstrates how the join result is rearranged and sorted alphabetically by the customer’s last name.
Practice Example: Employees With the Same Salary
We will practice using ORDER BY with self join in a question that is, again, asked by Amazon. But it’s not the one we’ve been practicing on so far.
This one asks to find employees who earn the same salary.
Employees With the Same Salary
Find employees who earn the same salary.
Output the worker id along with the first name and the salary in descending order.
Dataset
The question gives us the table worker to work with.
This is a list of employees, with the employees being a unique record.
Code
We select the workers’ ID, their first name, and salary – this is what the question asks us to do.
Then we join the table with itself using INNER JOIN, giving it aliases w and w1. The table is self joined on salary, as we’re looking to show the employees with the same salary.
The second self join condition is that the worker ID is not the same in the ‘both’ joined tables. That way, we want to avoid listing the same employee twice.
Finally, the output is sorted by salary in descending order, which is also one of the question’s requests. We’re using the ORDER BY clause to do the sorting.
SELECT w.worker_id,
w.first_name,
w.salary
FROM worker w
INNER JOIN worker w1
ON w.salary = w1.salary
AND w.worker_id != w1.worker_id
ORDER BY 3 DESC;
You have reached your daily limit for code executions on StrataScratch.
Please login/register for unlimited code executions.
There you have it – self join with ORDER BY.
| worker_id | first_name | salary |
|---|---|---|
| 4 | Amitah | 500000 |
| 5 | Vivek | 500000 |
| 8 | Geetika | 90000 |
| 9 | Agepi | 90000 |
| 7 | Satish | 75000 |
| 11 | Nayah | 75000 |
Using SQL Self Join With FULL OUTER JOIN
FULL OUTER JOIN is an outer type of join in SQL. It joins all the rows from one table with all the rows from the second table. It basically merges the two tables horizontally. Where there are unmatched rows, the values will be NULL.
In that sense, it could be seen as a combination of LEFT JOIN and RIGHT JOIN.
Using the Venn diagrams, it can be represented as this.
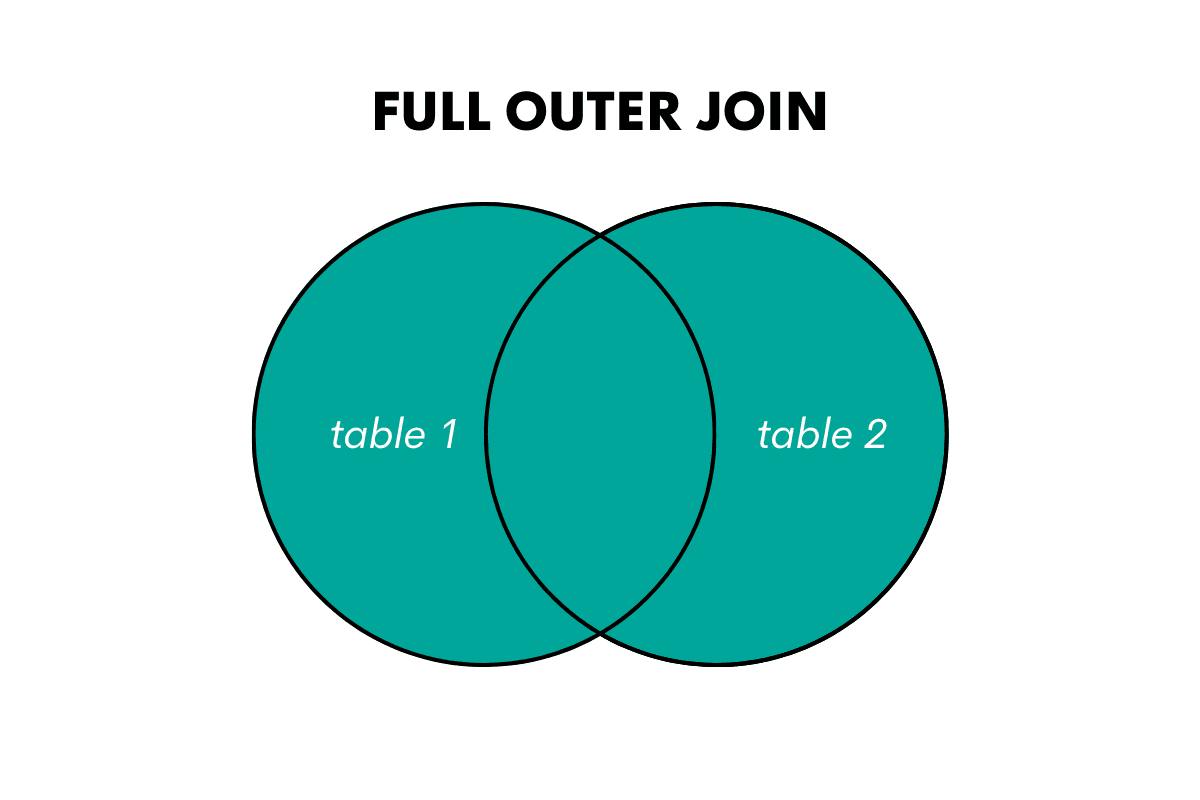
When you use it in a query, you can write it as FULL JOIN or FULL OUTER JOIN.
Illustration
Here’s FULL JOIN illustrated on an example with actual tables.

The above example shows that the result table contains all the rows from both tables. Where data is unmatched, there are NULL values. It’s as if you combined the LEFT JOIN and RIGHT JOIN results.
Let’s now use it as a SQL self join.
Practice Example: Trips in Consecutive Months
This question by Uber is quite straightforward. This doesn’t mean it’s easy, especially if you’re not familiar with the concept of self-joining the table.
Trips in Consecutive Months
Last Updated: November 2021
Find the IDs of the drivers who completed at least one trip a month for at least two months in a row.
Link to the question: https://platform.stratascratch.com/coding/2076-trips-in-consecutive-months
Dataset
We’ll work with the table uber_trips.
This is a list of trips with unique IDs, while all the other columns might have duplicates.
Code
The official solution uses INNER JOIN to solve this problem. We’ll use FULL JOIN just to see how it works and what will happen.
It’s the same as with all other joins we have covered so far: use the join type keywords and give aliases to the self joined table.
The joining condition is that the driver IDs are equal in both tables.
The second joining condition requires that the trip occurs no later than one month after the previous trip. We set this condition with the help of the TO_CHAR() function and by adding the interval of one month to the trip date in one table and then equalling it with the trip date from another table.
The result is filtered using WHERE to return the records with the completed trips.
SELECT DISTINCT a.driver_id
FROM uber_trips a
FULL JOIN uber_trips b
ON a.driver_id = b.driver_id
AND TO_CHAR(a.trip_date + interval '1 month', 'YYYY-MM') = TO_CHAR(b.trip_date, 'YYYY-MM')
WHERE a.is_completed = TRUE
AND b.is_completed = TRUE;
You have reached your daily limit for code executions on StrataScratch.
Please login/register for unlimited code executions.
Check the solution to see if FULL JOIN works here.
| driver_id |
|---|
| 1 |
| 4 |
Yes, it does. However, it’s more suitable to use INNER JOIN here. Simply because with FULL JOIN, you’re risking getting the NULL values in the output. Luckily, the condition in WHERE excluded such values from the output, so in this case, it’s the same output as with INNER JOIN.
Using SQL Self Join With CROSS JOIN
The CROSS JOIN is a type of join that returns all the combinations of all rows from both joined tables. This result is called a Cartesian product and can be represented as shown below.
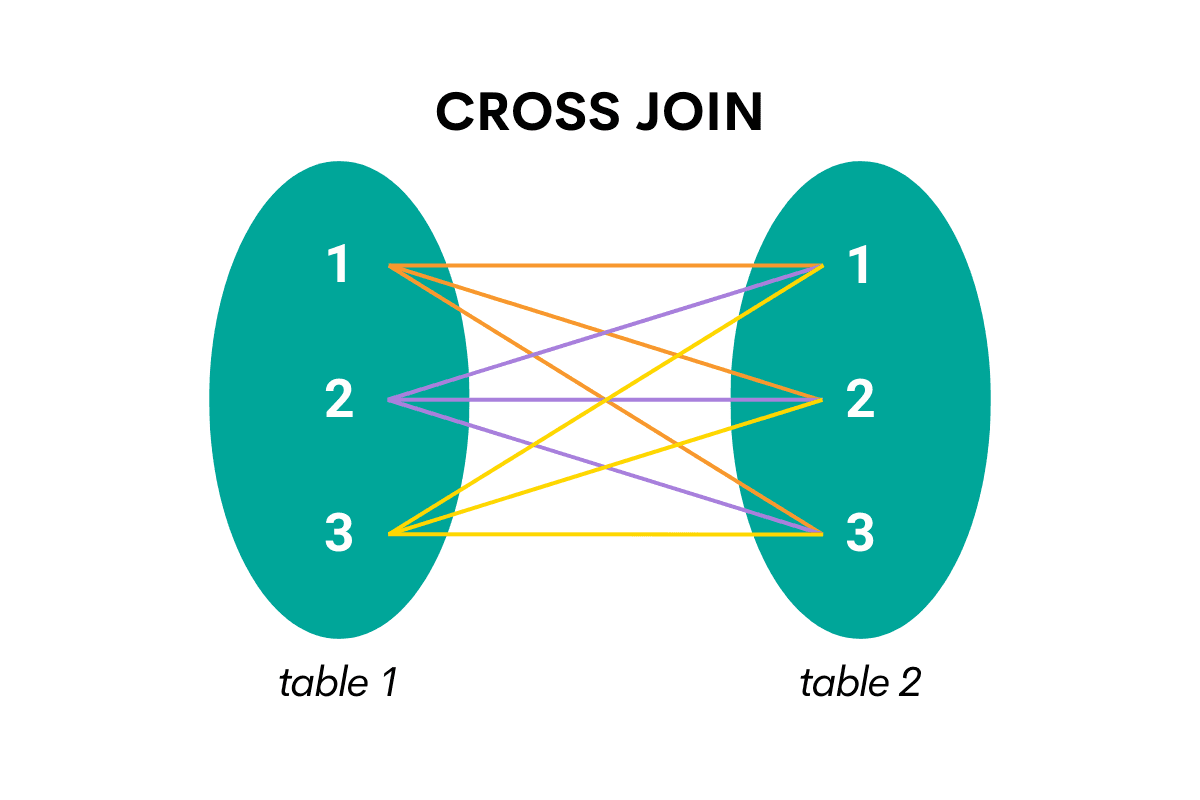
If you think you need to use CROSS JOIN, be absolutely sure about that. As it produces the combinations of all available rows, the query might take quite some time to complete, especially on bigger databases.
Illustration
Let’s use the same approach as so far to illustrate how CROSS JOIN works. We’ll show you only the first ten rows of the output. Showing the whole result would take up too much space.
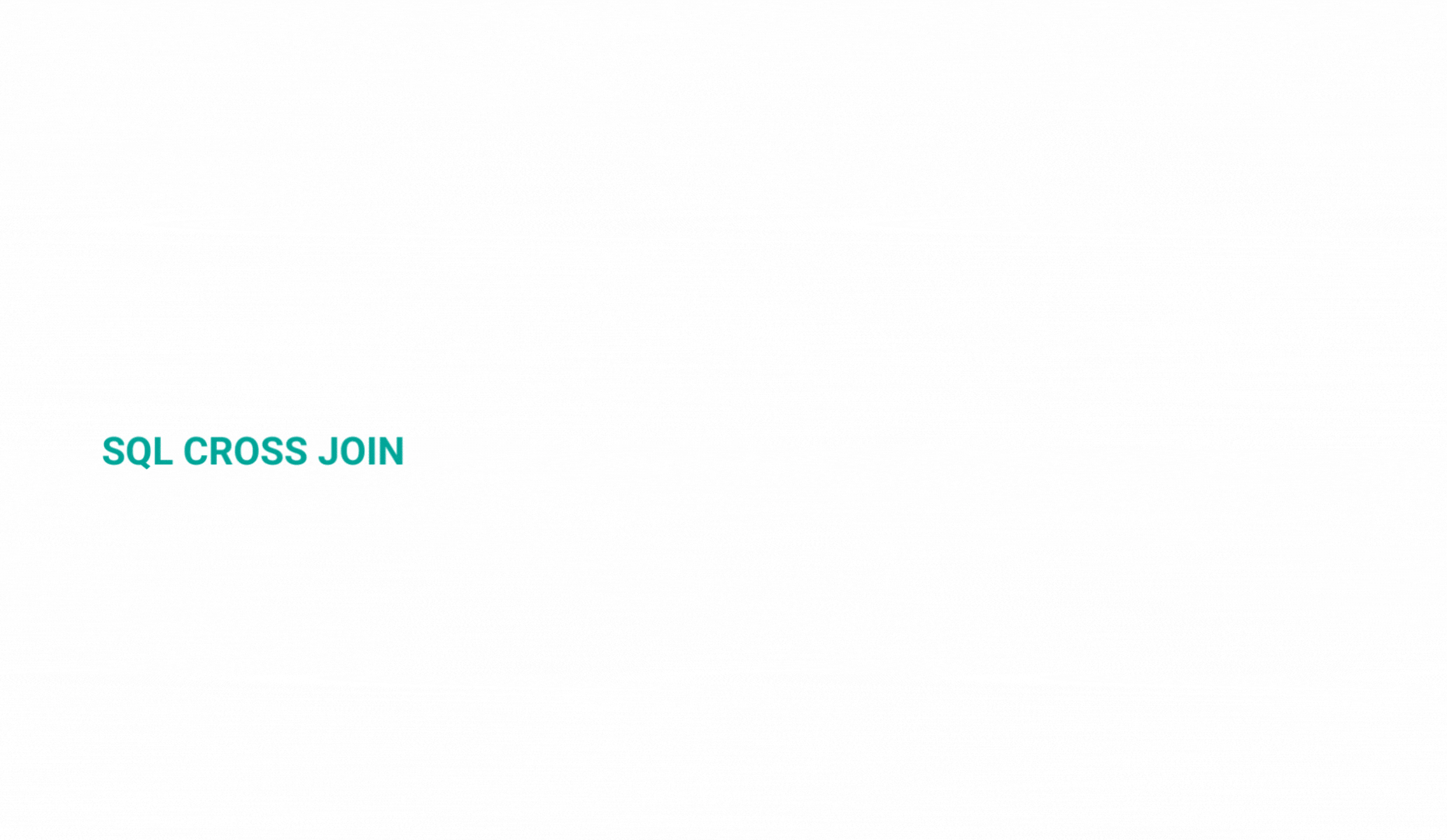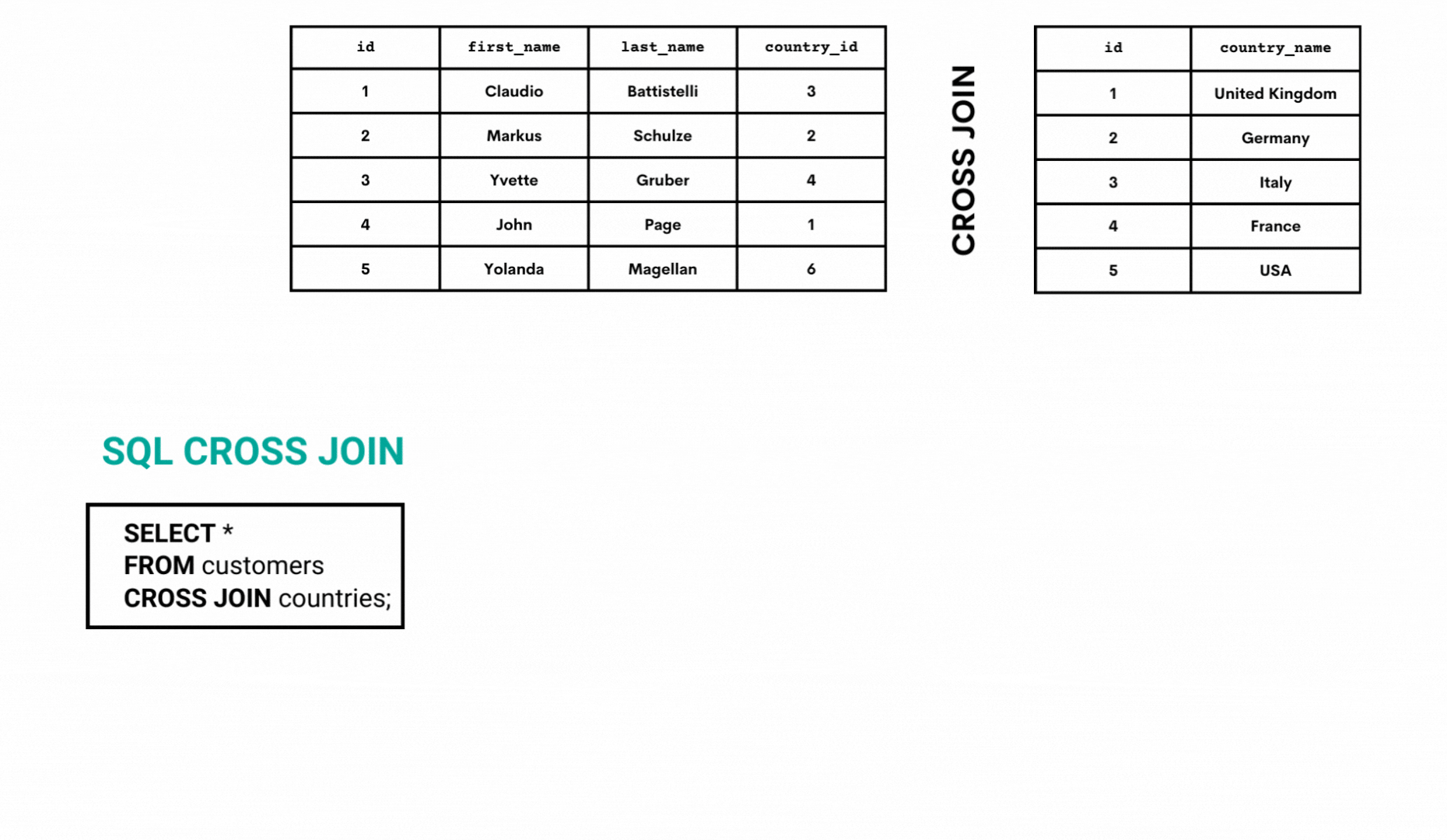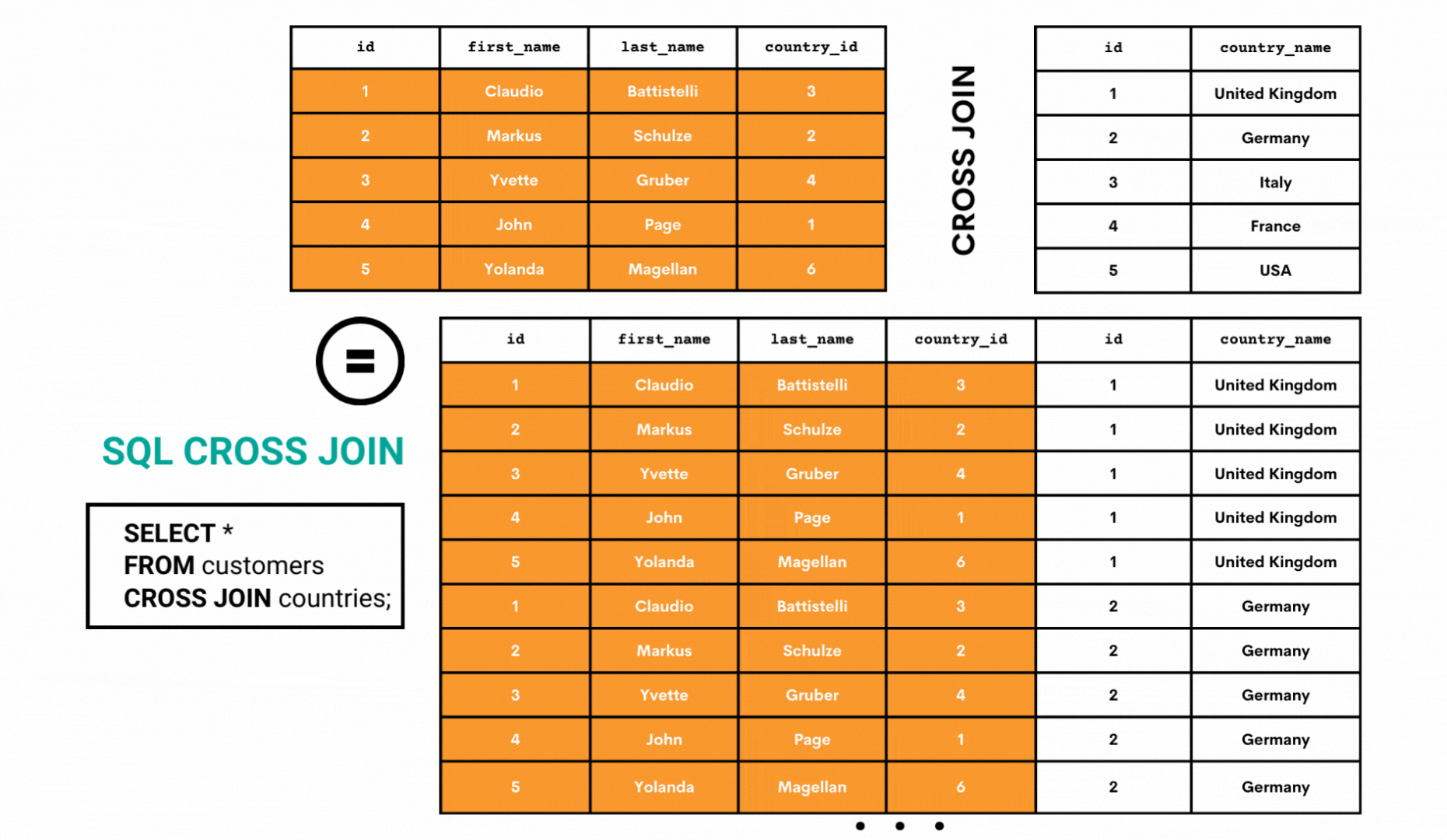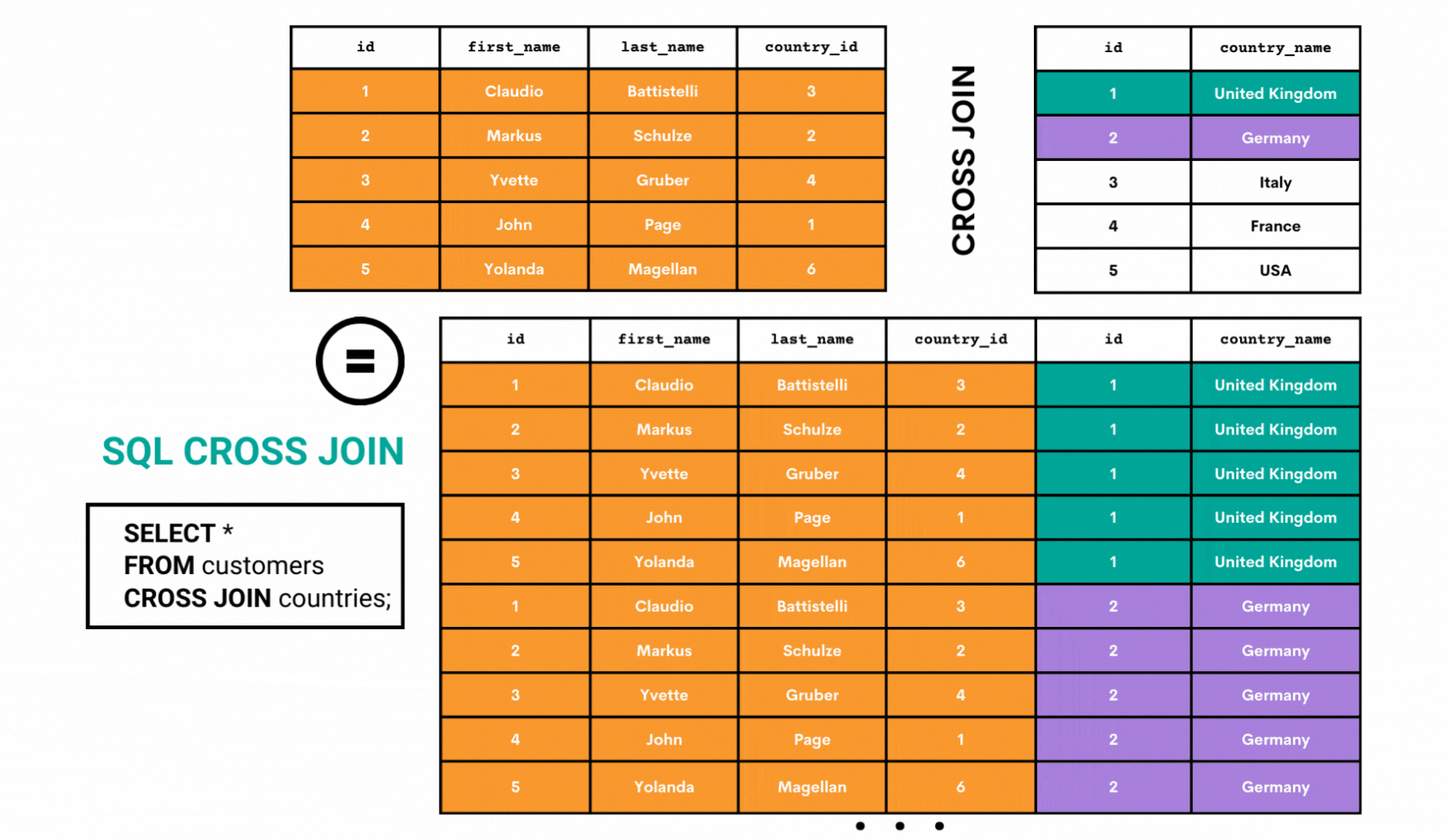
As you can see from the above GIF, the CROSS JOIN takes all the rows from the first table and joins them with the first row of the second table.
Then it does the same thing for the second row of the second table. The process continues until all the combinations of all the rows are shown.
On a side note, the above code can also be written as:
SELECT *
FROM customers, countries;
The question is, when would you need such a join. Well, when the interview question asks you, such as the one we’ll now try to solve.
Practice Example: Maximum of Two Numbers
This question asks us to return all possible permutations of two numbers. This sounds like an ideal job for CROSS JOIN!
Maximum of Two Numbers
Last Updated: April 2022
Given a single column of numbers, consider all possible permutations of two numbers with replacement, assuming that pairs of numbers (x,y) and (y,x) are two different permutations. Then, for each permutation, find the maximum of the two numbers. Output three columns: the first number, the second number and the maximum of the two.
Link to the question: https://platform.stratascratch.com/coding/2101-maximum-of-two-numbers
Dataset
The dataset consists of only one table (deloitte_numbers) with only one column.
Code
We self join the table using CROSS JOIN and giving the table aliases dn1 and dn2.
Now this is done, we can select the number column from each joined table. That way, we will get all the combinations for each number.
Additionally, we use the SQL CASE WHEN statement to find the highest of the two numbers in the pair. If the number from the ‘first’ table is higher, then it will end up in the new column max_number. In the opposite case, it will be the number from the ‘second’ table.
SELECT dn1.number AS number1,
dn2.number AS number2,
CASE
WHEN dn1.number > dn2.number THEN dn1.number
ELSE dn2.number
END AS max_number
FROM deloitte_numbers AS dn1
CROSS JOIN deloitte_numbers AS dn2;
You have reached your daily limit for code executions on StrataScratch.
Please login/register for unlimited code executions.
You’re free to hit the ‘Check Solution’ button to see the whole output and check if it works as a solution.
| number1 | number2 | max_number |
|---|---|---|
| -2 | -2 | -2 |
| -2 | -1 | -1 |
| -2 | 0 | 0 |
| -2 | 1 | 1 |
| -2 | 2 | 2 |
| -1 | -2 | -1 |
| -1 | -1 | -1 |
| -1 | 0 | 0 |
| -1 | 1 | 1 |
| -1 | 2 | 2 |
| 0 | -2 | 0 |
| 0 | -1 | 0 |
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 0 | 2 | 2 |
| 1 | -2 | 1 |
| 1 | -1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 1 |
| 1 | 2 | 2 |
| 2 | -2 | 2 |
| 2 | -1 | 2 |
| 2 | 0 | 2 |
| 2 | 1 | 2 |
| 2 | 2 | 2 |
Summary
In this illustrated guide, we tried to use as many visual representations as possible so you could grasp self join easily. We explained the SQL self join and how each typical use case works.
We backed each case with an example from our platform. This allowed you to practice the SQL self join syntax in different ways, as writing code is the best way to learn SQL.
There is, of course, a vast number of other coding interview questions you can practice SQL self joins on. Feel free to explore them, as well as our blog which brings many interesting SQL concepts.
This article also showed the importance of knowing SQL JOINs for learning self joins. If you need some more practice on that topic, go to our article discussing the SQL JOIN interview questions.
Share