How to Use SQL Wildcards for Flexible Data Queries

Categories:
 Written by:
Written by:Nathan Rosidi
This article is all about uncertainty and using it to add flexibility to SQL queries. How do you do that? Start using one of the five SQL wildcards regularly.
Querying databases sometimes feels like you have to know everything: where to look, how to look and what to look for. SQL queries seem to have the purpose of only confirming, what you already know by returning the data you were expecting. But if you’re not quite sure what you’re looking for?
Enter the SQL wildcards, little symbols that really are true to their name. They are wild and can turn your SQL queries into flexible beasts that make your life easier.
How do they do that? Keep on reading to find out.
What Are SQL Wildcards?
If you play cards, you’ll know that a wild card can replace any other card. Similarly, SQL wildcards substitute a character or a range of characters when querying string data.
They are commonly used when you don’t know the exact value of a string. For example, you’re querying a table and want to find an employee named Nathanael. But you’re not sure if the guy’s name was recorded in the database as Nathanael, Nathan, or Nate. Instead of trying to search all three names, you could just search for an employee whose name begins with 'Nat', and your search will work.
In other words, you don’t have to scroll through thousands of data rows just to find one person; SQL wildcards do that for you.
Syntax of SQL Wildcards
SQL wildcards are most commonly used in the WHERE clause with the LIKE (and ILIKE for case-insensitive search in PostgreSQL) operator.
The syntax looks like this.
SELECT column_1,
column_2
FROM table
WHERE column_1 LIKE 'string_with_wildcard';
The 'string_with_wildcard' is the character pattern you are looking for. What your query will look for depends on which wildcard you use.
Types of SQL Wildcards
There are five wildcards that you can use in SQL.

Let me briefly explain what each wildcard does, and then we’ll demonstrate this in simple examples.
1. Percent Sign (%) Wildcard
This wildcard stands for zero or more characters. In other words, it replaces any type and number of characters.
Here are the typical scenarios where this wildcard is helpful.

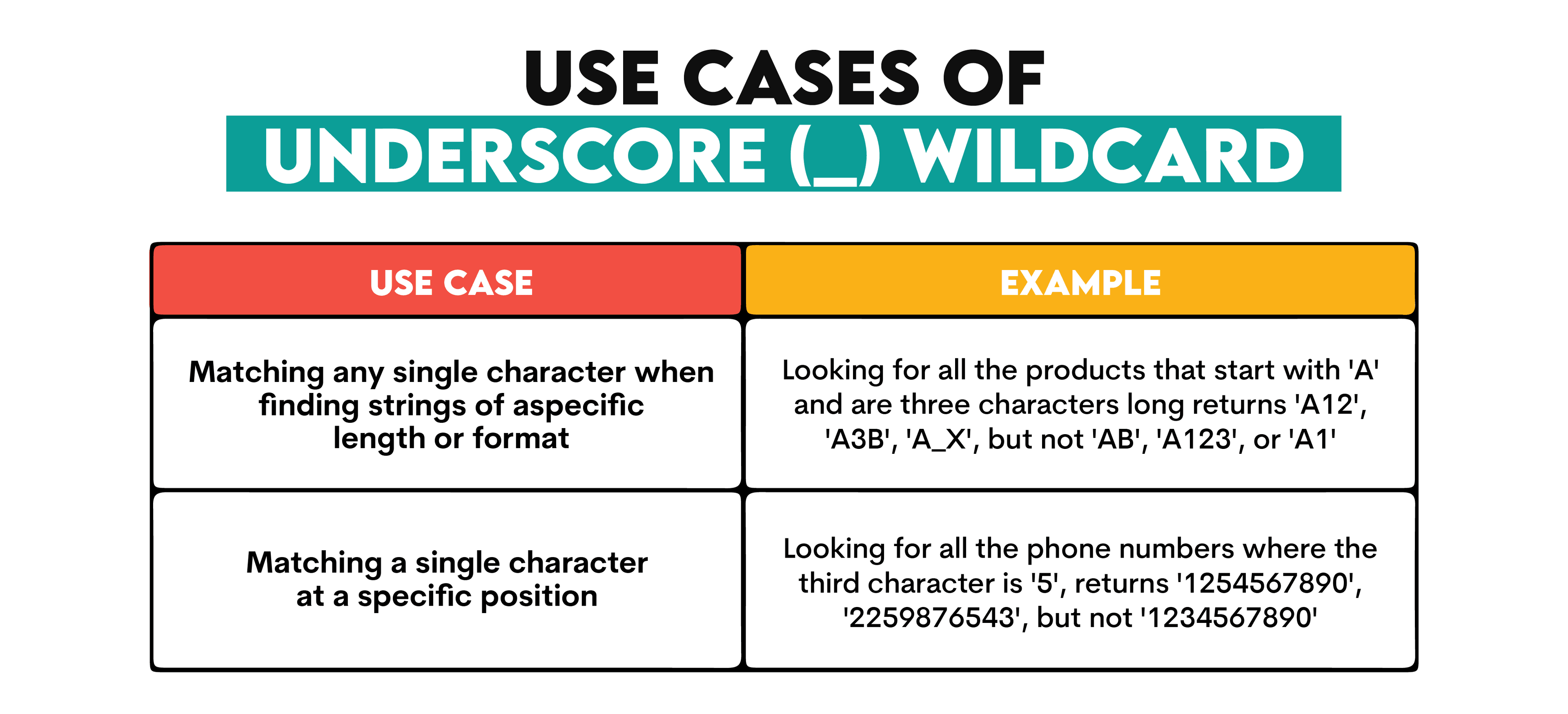
2. Underscore (_) Wildcard
The underscore wildcard is used for matching exactly one character.
You can use it in these two cases.
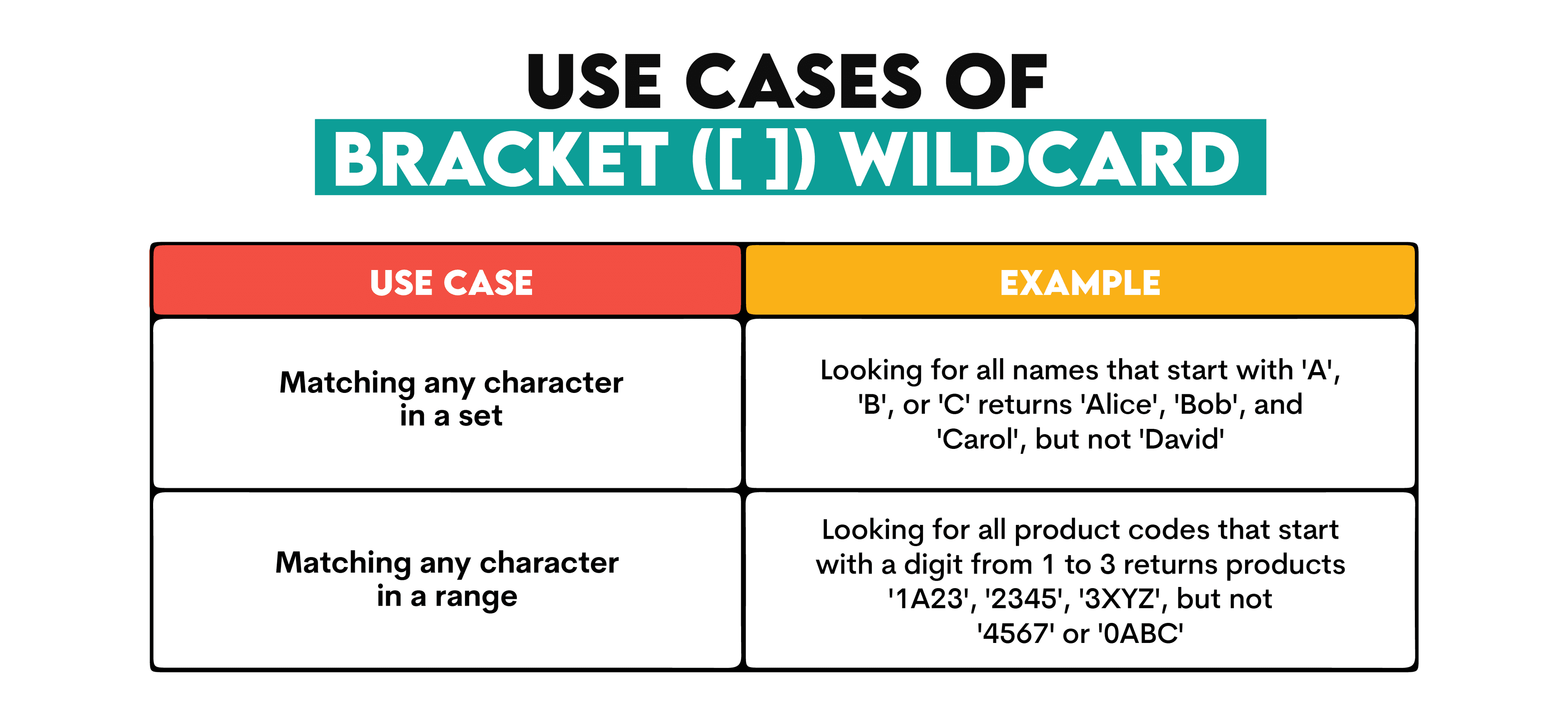
3. Bracket ([ ]) Wildcard
This wildcard matches any character within a specified character set or number range.
Here’s when you can use this wildcard.
4. Caret (^) Wildcard
The caret wildcard is used in conjunction with the bracket wildcard to exclude the specified character or character set. It’s the opposite of the bracket wildcard.

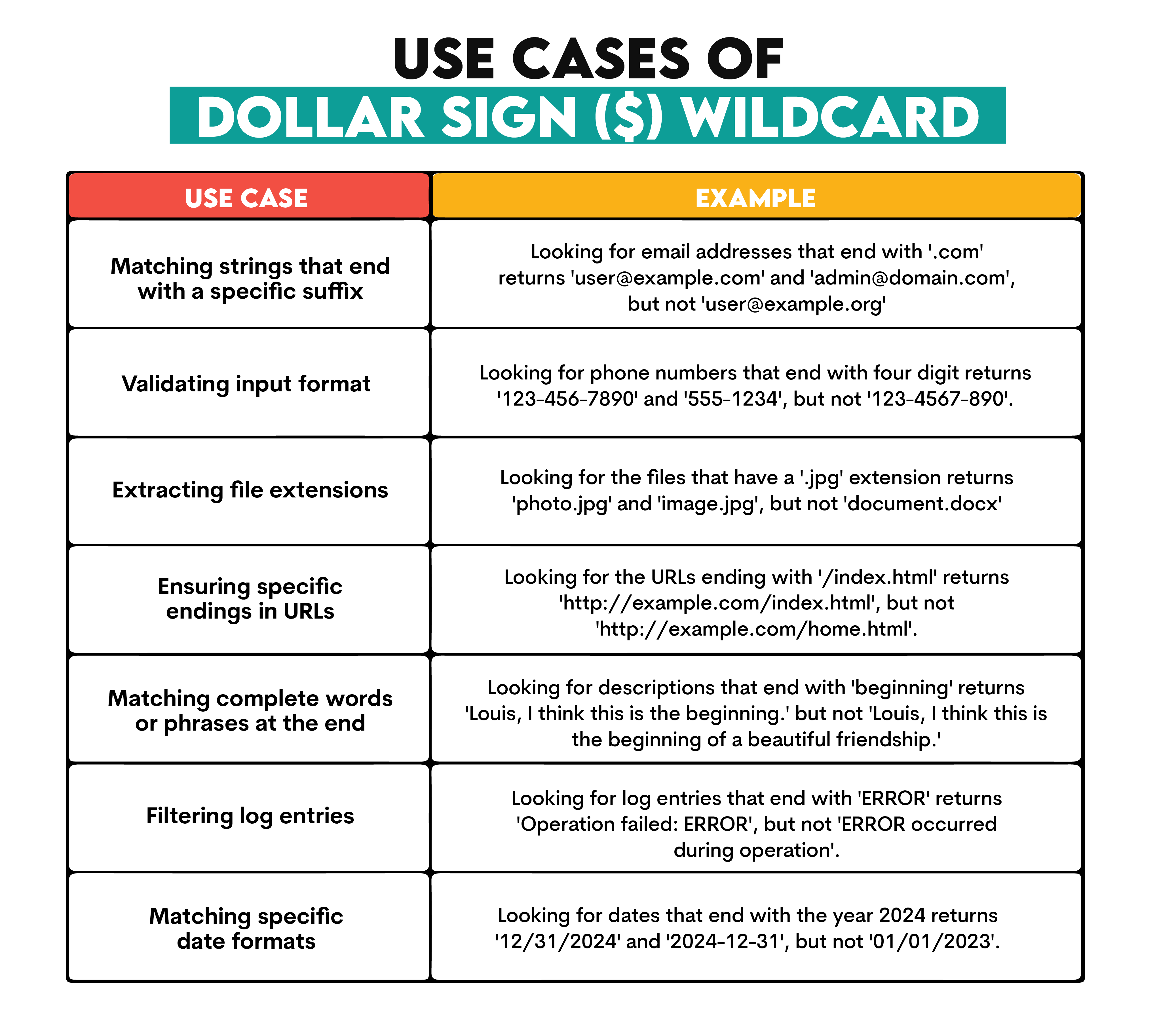
5. Dollar Sign ($) Wildcard
This wildcard matches the end of a string in regex functions. It’s not a standard SQL wildcard, but is used in the databases that support regex features:
- PostgreSQL: With '~' (case sensitive) or '~*' (case insensitive) for regex matching.
- MySQL: With REGEXP.
- Oracle: With REGEXP_LIKE.
Here are the typical examples where you’d use a dollar sign wildcard.
Using SQL Wildcards With the LIKE Operator
As I already mentioned, the SQL wildcards are most often used with the LIKE operator. I’ll show you how in simple examples for each wildcard.
Percent Sign (%) Wildcard With LIKE
The following code finds all the employees whose name starts with 'J'.
SELECT *
FROM employees
WHERE name LIKE 'J%';
The principle of using the wildcards with LIKE consists of four steps:
- The WHERE clause.
- The name of the column that you want to filter.
- The LIKE (case sensitive) or ILIKE (case insensitive) operator.
- The string with a wildcard in single quotes.
Underscore (_) Wildcard With LIKE
This code looks for the employee names that start with 'J' and are three characters long.
SELECT *
FROM employees
WHERE name LIKE 'J__';
Bracket ([ ]) Wildcard With LIKE
The query below finds names that start with 'J', 'K', or 'L'.
SELECT *
FROM employees
WHERE name LIKE '[JKL]%';
This syntax is specific to SQL Server. Other SQL dialects don’t support such use. Here’s how you should rewrite the query if you’re using other databases.
In PostgreSQL, you should use regular expressions and caret (^) to signal the beginning of the string.
SELECT *
FROM employees
WHERE name ~ '^[JKL]';
Another option is to split the range into multiple conditions using the OR operator and the percent sign wildcard.
SELECT *
FROM employees
WHERE name LIKE 'J%' OR name LIKE 'K%' OR name LIKE 'L%';
This second option also works in MySQL and Oracle.
Caret (^) Wildcard With LIKE
The query here does the opposite of the one from the previous example; it finds names that don’t start with 'J', 'K', or 'L'.
SELECT *
FROM employees
WHERE name LIKE '[^JKL]%';
Dollar Sign ($) Wildcard With LIKE
The code you see below looks for email addresses that end with '.org'.
SELECT *
FROM Users
WHERE email ~ '\.org$';
Practical Applications of SQL Wildcards
Generally, SQL wildcards are most commonly used in the four scenarios.

Now, let’s examine some of those applications in real-life business problems. For that purpose, I’ll use several coding interview questions from our platform.
Percent Sign (%) Wildcard Example
Let’s solve this interview question by Amazon, Ebay, and Shopify.
Manager of the Largest Department
Last Updated: September 2021
Given a list of a company’s employees, find the first and last names of all employees whose position contains the word “manager” and who work in the largest department(s) — that is, departments with the highest number of employees. If multiple departments share the same largest size, return managers from all such departments.
Link to the question: https://platform.stratascratch.com/coding/2060-manager-of-the-largest-department
The question is about finding the manager from the largest department. You’re given the az_employees table.
The official solution utilizes two subqueries. The first subquery is the one that uses a window function to count the number of employees in each department.
SELECT *,
COUNT(*) OVER(PARTITION BY department_id) AS dpt_members
FROM az_employees;
This is the code’s sample output.
| id | first_name | last_name | department_id | department_name | position | dpt_members |
|---|---|---|---|---|---|---|
| 53 | Teresa | Cohen | 1001 | Marketing | Contractor | 13 |
| 63 | Richard | Sanford | 1001 | Marketing | Senior specialist | 13 |
| 85 | Meagan | Bullock | 1001 | Marketing | Senior specialist | 13 |
| 89 | Jason | Taylor | 1001 | Marketing | Junior specialist | 13 |
| 97 | Kelli | Moss | 1001 | Marketing | Contractor | 13 |
The second subquery references the first one to rank the departments by the number of employees.
SELECT *,
RANK() OVER(ORDER BY dpt_members DESC) AS rnk
FROM
(SELECT *,
COUNT(*) OVER(PARTITION BY department_id) AS dpt_members
FROM az_employees) a;
The output snapshot is below.
| id | first_name | last_name | department_id | department_name | position | dpt_members | rnk |
|---|---|---|---|---|---|---|---|
| 16 | Briana | Rivas | 1005 | Sales | Senior specialist | 22 | 1 |
| 8 | Mercedes | Rodriguez | 1005 | Sales | Junior specialist | 22 | 1 |
| 6 | Natasha | Swanson | 1005 | Sales | Junior specialist | 22 | 1 |
| 2 | Justin | Simon | 1005 | Sales | Senior specialist | 22 | 1 |
| 100 | Amber | Miles | 1002 | Human Resources | Senior specialist | 22 | 1 |
When we put all this together, the main query selects the employee’s first and last names from subqueries. Now comes filtering based on the position. I use ILIKE for case-insensitive matching. There’s the percent sign wildcard in front and after 'manager', which will look for that word anywhere in the string.
The additional filtering condition is that the rank must be 1, i.e., the manager is from the largest department.
SELECT first_name,
last_name
FROM
(SELECT *,
RANK() OVER(ORDER BY dpt_members DESC) AS rnk
FROM
(SELECT *,
COUNT(*) OVER(PARTITION BY department_id) AS dpt_members
FROM az_employees) a) b
WHERE position ILIKE '%manager%' AND rnk = 1;
The solution gives us two managers.
| first_name | last_name |
|---|---|
| Victoria | Wilson |
| Richard | Garcia |
Bonus Examples
To satisfy your curiosity, if you are looking for employees whose position starts with the word ‘manager’, this is how you should alter your query.
SELECT first_name,
last_name
FROM
(SELECT *,
RANK() OVER(ORDER BY dpt_members DESC) AS rnk
FROM
(SELECT *,
COUNT(*) OVER(PARTITION BY department_id) AS dpt_members
FROM az_employees) a) b
WHERE position ILIKE 'manager%';
| first_name | last_name |
|---|---|
| Nicole | Lewis |
| Victoria | Wilson |
| William | Flores |
| Robert | Lynch |
| Richard | Garcia |
| Jason | Olsen |
On the other hand, the query below looks for employees whose position ends with ‘manager’.
SELECT first_name,
last_name
FROM
(SELECT *,
RANK() OVER(ORDER BY dpt_members DESC) AS rnk
FROM
(SELECT *,
COUNT(*) OVER(PARTITION BY department_id) AS dpt_members
FROM az_employees) a) b
WHERE position ILIKE '%manager';
| first_name | last_name |
|---|---|
| Nicole | Lewis |
| Victoria | Wilson |
| William | Flores |
| Robert | Lynch |
| Richard | Garcia |
| Jason | Olsen |
Underscore (_) Wildcard Example
To showcase how this SQL wildcard works, let’s solve the Amazon question.
First Names With Six Letters Ending in 'h'
Find all workers whose first name contains 6 letters and also ends with the letter 'h'.
Display all information about the workers in output.
Link to the question: https://platform.stratascratch.com/coding/9842-find-all-workers-whose-first-name-contains-6-letters-and-also-ends-with-the-letter-h
To solve the problem, you need to find all workers whose first name contains six letters and ends with the letter ‘h’.
You have the table worker at your disposal.
In the query shown below, I use the underscore wildcard. Trust me; I pressed the underscore five times before the letter ‘h’. In total, there are six characters in the string ending with ‘h’. That’s precisely the question’s criteria.
SELECT *
FROM worker
WHERE first_name LIKE '_____h';
The code returns two workers.
| worker_id | first_name | last_name | salary | joining_date | department |
|---|---|---|---|---|---|
| 4 | Amitah | Singh | 500000 | 2014-02-20 | Admin |
| 7 | Satish | Kumar | 75000 | 2014-01-20 | Account |
Bonus Examples
Imagine that the requirement was to find the names starting with ‘v’ and consisting of five letters. This is what your query should look like in that case.
Along with changing the way you use the wildcard, you should also use ILIKE for the case-insensitive search so the query will find names even if you don’t write them with the capital first letter.
SELECT *
FROM worker
WHERE first_name ILIKE 'v____';
| worker_id | first_name | last_name | salary | joining_date | department |
|---|---|---|---|---|---|
| 5 | Vivek | Bhati | 500000 | 2014-06-11 | Admin |
| 6 | Vipul | Diwan | 200000 | 2014-06-11 | Account |
Another case of a different use of the underscore wildcard could be when looking for workers with names that contain six letters, with the letter ‘i’ in the third place.
SELECT *
FROM worker
WHERE first_name ILIKE '__i___';
| worker_id | first_name | last_name | salary | joining_date | department |
|---|---|---|---|---|---|
| 4 | Amitah | Singh | 500000 | 2014-02-20 | Admin |
Bracket ([ ]) Wildcard Example
Let’s solve this interview question by ESPN to demonstrate how the bracket wildcard works.
Quarterback With The Longest Throw
Find the quarterback who threw the longest throw in 2016. Output the quarterback name along with their corresponding longest throw.
The lg column shows the quarterback’s longest completion. If the value has a trailing t, ignore the t and use the numeric part when determining the longest throw.
Link to the question: https://platform.stratascratch.com/coding/9966-quarterback-with-the-longest-throw
The requirement here is to find the quarterback with the longest throw in 2016.
We’ll work with the table qbstats_2015_2016.
Let’s go a little bit more into the dataset to see why the bracket wildcard is needed to solve the question.
The lg column in the table contains the quarterback's longest completion; this is what the question states.
Now, if you scroll a little bit through the table, you’ll see that this column mainly consists of only digits. However, there are quite a few rows that also have a letter ‘t’ following the numbers, whatever that symbolizes.
Here are several such rows.
SELECT *
FROM qbstats_2015_2016
WHERE lg LIKE '%t'
LIMIT 5;
| qb | att | cmp | yds | ypa | td | int | lg | sack | loss | rate | game_points | home_away | year |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Carson PalmerC. Palmer | 32 | 19 | 307 | 9.6 | 3 | 0 | 55t | 0 | 0 | 122.8 | 31 | home | 2015 |
| Cam NewtonC. Newton | 37 | 18 | 195 | 5.3 | 2 | 1 | 36t | 2 | 17 | 71.3 | 24 | home | 2015 |
| Carson PalmerC. Palmer | 24 | 17 | 185 | 7.7 | 4 | 1 | 28t | 0 | 0 | 115.5 | 48 | away | 2015 |
| Tyrod TaylorT. Taylor | 30 | 23 | 242 | 8.1 | 3 | 3 | 32t | 8 | 53 | 93.3 | 32 | home | 2015 |
| Philip RiversP. Rivers | 27 | 21 | 241 | 8.9 | 2 | 1 | 40t | 4 | 18 | 113.1 | 19 | away | 2015 |
In our output, we need clean data, which means showing only the throw distance and nothing in addition to it. To achieve this, we use the bracket wildcard extensively.
First, write a subquery that will extract the numeric part of the lg column using the SUBSTRING() function and the bracket wildcard. Then, apply the MAX() function to find the longest throw and convert the result to a numeric data type.
SELECT MAX(SUBSTRING(lg FROM '[0-9]+')::NUMERIC)
FROM qbstats_2015_2016
WHERE year = 2016;
| max |
|---|
| 98 |
This part of the code shows that the longest throw is 98 of…something. Yards, probably? (Is it very obvious that I’m not a football fan?)
Now, this subquery will be used as a filtering condition in the main query's WHERE. The main query itself also uses SUBSTRING() and the bracket wildcard to extract the numeric part of the throw distance.
Its WHERE clause then outputs only quarterbacks whose throws were made in 2016 and were the longest ones.
Here’s the complete solution.
SELECT qb,
SUBSTRING(lg FROM '[0-9]+')::NUMERIC AS lg_num
FROM qbstats_2015_2016
WHERE year = 2016
AND SUBSTRING(lg FROM '[0-9]+')::NUMERIC =
(SELECT MAX(SUBSTRING(lg FROM '[0-9]+')::NUMERIC)
FROM qbstats_2015_2016
WHERE year = 2016);
The quarterback who threw the longest throw in 2016 is Drew Brees.
| qb | lg_num |
|---|---|
| Drew BreesD. Brees | 98 |
Caret (^) Wildcard Example
Here’s the question by Google.
Sorting Movies By Duration Time
Last Updated: May 2023
You have been asked to sort movies according to their duration in descending order.
Your output should contain all columns sorted by the movie duration in the given dataset.
Link to the question: https://platform.stratascratch.com/coding/2163-sorting-movies-by-duration-time
The task here is to sort movies according to their duration. We’ll be using the table movie_catalogue to do that.
The data in the duration column has to be cleaned so that only digits showing duration are left, without ‘min’.
In PostgreSQL, we use the REGEXP_REPLACE() function in combination with the caret and bracket wildcard. That way, we remove all the non-numeric characters from the duration column.
In addition, the data is converted to decimal format, and the output is sorted in descending order.
SELECT *
FROM movie_catalogue
ORDER BY CAST(REGEXP_REPLACE(duration, '[^0-9]+', '') AS DECIMAL) DESC;
Here’s the output snapshot.
| show_id | title | release_year | rating | duration |
|---|---|---|---|---|
| s8083 | Star Wars: Episode VIII: The Last Jedi | 2017 | PG-13 | 152 min |
| s6201 | Avengers: Infinity War | 2018 | PG-13 | 150 min |
| s8052 | Solo: A Star Wars Story | 2018 | PG-13 | 135 min |
| s6326 | Black Panther | 2018 | PG-13 | 135 min |
| s8053 | Solo: A Star Wars Story (Spanish Version) | 2018 | PG-13 | 135 min |
Dollar Sign (%) Wildcard Example
I’ll need to adapt this question by Google to show you how the dollar sign wildcard works.
User Email Labels
Last Updated: April 2020
Find the number of emails received by each user under each built-in email label. The email labels are: 'Promotion', 'Social', and 'Shopping'. Output the user along with the number of promotion, social, and shopping mails count,.
Link to the question: https://platform.stratascratch.com/coding/10068-user-email-labels
Instead of doing what the question says, let’s simplify it: query the table google_gmail_labels and return the data where the label name contains an underscore and ends with any given character.
The code below uses the tilde operator (~) to apply a regular expression. Then the pattern '_.' matches an underscore followed by any character, and the dollar sign wildcard marks the end of the string.
SELECT *
FROM google_gmail_labels
WHERE label ~ '_.$';
Here’s the snapshot of the output.
| email_id | label |
|---|---|
| 1 | Custom_3 |
| 7 | Custom_3 |
| 16 | Custom_2 |
| 17 | Custom_3 |
| 19 | Custom_2 |
Best Practices for Using Wildcards in SQL
SQL wildcards are like water: Don’t drink it, and you die; drink it too much, and you also die. OK, you won’t die if you overuse SQL wildcards or don’t use them at all. But you could ‘kill’ your database by not following some very simple best practices for using SQL wildcards.

1. Use specific patterns: When querying a database, try to be as specific as possible with the search patterns. The point is to reduce the amount of data to be scanned, so avoid using the broad patterns you look for.
2. Carefully plan indexing: Your wildcard searches, especially if starting with a wildcard, can neutralize the benefits of indexes in the database. You should consider this when planning your indexes.
3. Testing patterns: Check if the patterns you’re searching for actually return the output you need. See if there’s some excluded data or data that you don’t need.
4. Security concerns: When allowing user input into wildcard patterns, you become more susceptible to injection attacks. It’s recommended that you use parametrized queries.
Conclusion
The five SQL wildcards add flexibility to your database querying. They allow you to not know what exactly the data looks like and, at the same time, define very specific character patterns to look for.
Looking for those patterns without wildcards in the databases with millions of rows? You’d be doomed!
You’d be, but you’re not. Luckily, you’re at the right place to learn about wildcards and how to use them in practice. I used only several questions from our platform where SQL wildcards can be used. But there are many, many more SQL interview questions waiting for you to explore them.
Share