How to Replace a Character in a Python String


Categories:
 Written by:
Written by:Nathan Rosidi
There are several ways to replace a character in a Python string. In this article, you’ll learn three main techniques and how to use them in practice.
Strings are one of Python's most commonly used data types, but they come with a twist: they are immutable. While this immutability has its advantages (more on that later), it also complicates things when you need to replace a character in a Python string. Hence the need for this article and learning about Python string methods.
We’ll explain several techniques for replacing a character in a string and showcase how they work in practice using the question interviews from our platform.
Why Strings Are Immutable in Python
Strings in Python are immutable, meaning the string’s content can’t be changed once the string is created.
It’s a feature driven by four main reasons.


1. Memory Efficiency: Probably the main reason for string immutability in Python is memory management optimization. If a string is immutable, multiple variables or references can point to the same string object, and there’s no risk of it being altered. This allows reusing memory locations for identical strings (rather than creating new ones), which reduces overhead and improves performance, especially when processing large amounts of text data.
2. Thread Safety: In multi-threaded programs, multiple threads can use the same string object without the risk of one thread altering it and creating side effects in other threads. It also improves efficiency in multi-threaded applications since there’s no need for complex locking mechanisms that prevent concurrent modifications.
3. Hashability: String immutability allows them to be hashable, and their hash value remains consistent. Because of that, they can be used as keys in dictionaries or as elements in sets, which require immutable and hashable objects to function.
4. Security: Since strings are used for storing passwords, their immutability also improves password security, as they can’t be tampered with later. This minimizes the possibility of unintended changes by adding a layer of security.
How This Immutability Affects Character Replacement
Hold on a sec! Immutable!? Don’t we concatenate strings or replace one substring with another one? Doesn’t that change a string? Actually, no! It seems it does, but these string operations create a new string rather than changing the existing one.
This immutability means each character replacement technique we’ll discuss creates a new string, leaving the original string unchanged.
Techniques to Replace a Character in a Python String
There are several ways to replace string characters in Python:
- Using the str.replace() method
- Using list comprehensions
- Using regular expressions, i.e., re.sub()
Basic String Replacement Techniques
The basic method for replacing a string in Python is intuitively named str.replace(). It allows you to specify one character or a whole substring you want to replace and a character (or a substring) you want to replace it with.
The method’s syntax is:
str.replace(old, new, [count]
Here’s the explanation of the function’s arguments:
- old: The character or a substring you want to replace.
- new: The character or a substring to replace it with.
- count: This is an optional argument that specifies the maximum number of occurrences to replace. If not provided, all occurrences will be replaced.
For example, you want to replace ‘blue’ with ‘red’ in the string ‘The sky is blue’.
text = 'The sky is blue.'
new_text = text.replace('blue', 'red')
print(new_text)
Here’s the output.


Say, you want to replace only the first occurrence of ‘blue’ with ‘red’ in the string ‘The sky is blue and the ocean is also blue’.
Here, you’ll need the optional argument count to specify that only the first occurrence will be replaced.
text = 'The sky is blue and the ocean is blue.'
new_text = text.replace('blue', 'red', 1)
print(new_text)
Here’s the output.


Note: str.replace() is case-sensitive, so ‘Blue’ and ‘blue’ are not the same substrings.
In addition, there’s almost the same function in pandas called Series.str.replace(), which is used to replace occurrences of a pattern in pandas Series and DataFrames.
This is pandas equivalent to Python’s built-in function str.replace(), with some additional features:
Series.str.replace(pat, repl, n=-1, case=None, regex=True)
- pat: The pattern you want to search for, i.e., a string or a regular expression, depending on the regex parameter.
- repl: The string to replace the found pattern with.
- n=-1: The number of replacements to make specified as a positive integer. The default value is -1, meaning it will replace all occurrences.
- case: If True, the replacement is case-sensitive. If False, it will then be case-insensitive. If None, the case sensitivity is based on the regex parameter.
- regex=True: If True, the pat parameter is treated as a regular expression. If False, it’s a literal string.
I’m mentioning this pandas function because it works similar to Python’s built-in function str.replace(). Also, we will use pandas’ function throughout practical examples; no need to ignore pandas’ data manipulation abilities and make our lives difficult when replacing characters in a Python string. After all, pandas is now almost a default Python library, with the line between pandas��’ and Python’s functionalities often blurred.
Interview Example: Replacing Character With str.replace()
This interview question by Microsoft demonstrates the use of str.replace().
Last Updated: November 2020
Find the total number of downloads for paying and non-paying users by date. Include only records where non-paying customers have more downloads than paying customers. The output should be sorted by earliest date first and contain 3 columns date, non-paying downloads, paying downloads. Hint: In Oracle you should use "date" when referring to date column (reserved keyword).
Link to the question: https://platform.stratascratch.com/coding/10300-premium-vs-freemium
The question asks you to find the total number of downloads for paying and non-paying users by date. Only records where non-paying customers have more downloads than paying customers should be included, and the output has to be sorted by the earliest date.
There are three DataFrames at the disposal; the first one is ms_user_dimension.
The second DataFrame is ms_acc_dimension.
The third DataFrame is named ms_download_facts.
First, I’ll inner join the ms_user_dimension and ms_acc_dimension DataFrames on the column acc_id using the merge() method. This creates a new DataFrame.
Next, I’ll join this created DataFrame with ms_download_facts, the third DataFrame from the question’s dataset.
The code then creates a pivot table that is indexed by date, i.e., the rows will be organized and labeled by the date values. The values in the column paying_customer will be used to create columns for each unique value in the column, i.e., the unique values are ‘yes’ and ‘no’, meaning paying and non-paying customers. The data will be aggregated by the downloads column using the sum aggregate function.
The pivot table is then converted to a DataFrame df2 using to_records().
We have this code so far.
import pandas as pd
import numpy as np
df=pd.merge(ms_user_dimension, ms_acc_dimension, how = 'inner',left_on = ['acc_id'], right_on=['acc_id'])
df1= pd.merge(df, ms_download_facts, how = 'inner',left_on = ['user_id'], right_on=['user_id'])
x=df1.pivot_table(index=['date'],columns=['paying_customer'],values=['downloads'],aggfunc='sum')
df2=pd.DataFrame(x.to_records())
The partial output is shown below.
As you can see, the column names are a mess. We need to clean and modify them, and this is when str.replace() comes into play.
We use this method four times to do the following:
- Remove opening and closing round brackets (written in square brackets as a regular expression) by replacing them with an empty string.
- Remove single quotes, also as a regular expression, by replacing them with an empty string.
- Remove commas, also as a regular expression, by replacing them with an empty string.
- Remove the word ‘downloads’ by replacing it with an empty string.
We then fill all NaN values with 0 using fillna(), find the difference between the non-paying (‘no’) and paying (‘yes’) users, and display only the dates on which non-paying customers have more downloads than paying customers.
df2.columns = df2.columns.str.replace("[()]","").str.replace("[' ']","").str.replace("[,]","").str.replace("downloads","")
df3=df2.fillna(0)
df3['diff'] = df3['no']-df3['yes']
df4 = df3[df3["diff"] > 0]
result = df4[["date","no","yes"]].sort_values("date")
Merged with the previous part, this is what the whole code looks like.
import pandas as pd
import numpy as np
df=pd.merge(ms_user_dimension, ms_acc_dimension, how = 'inner',left_on = ['acc_id'], right_on=['acc_id'])
df1= pd.merge(df, ms_download_facts, how = 'inner',left_on = ['user_id'], right_on=['user_id'])
x=df1.pivot_table(index=['date'],columns=['paying_customer'],values=['downloads'],aggfunc='sum')
df2=pd.DataFrame(x.to_records())
df2.columns = df2.columns.str.replace("[()]","").str.replace("[' ']","").str.replace("[,]","").str.replace("downloads","")
df3=df2.fillna(0)
df3['diff'] = df3['no']-df3['yes']
df4 = df3[df3["diff"] > 0]
result = df4[["date","no","yes"]].sort_values("date")
The output gives four dates with the number of downloads for paying and non-paying users.
Using List Comprehensions for Character Replacement
Replacing characters in a string with a list comprehension? That sounds awkward!
Actually, it isn’t because it’s one of the three steps required in total:
- Convert a string to a list
- Use list comprehension for character replacement
- Join the list back into a string
1. Converting a String to a List
To convert a string to a list, use the split() method with this generic syntax.
string_variable = 'your string here'
list_of_words = string_variable.split()
2. Use List Comprehension to Replace a Character
Now, list comprehension. It’s a Python method of creating a new list by applying an expression to each item in a list. This sounds very suitable for character replacement and requires a concise code, replacing the traditional for loops.
Here’s a generic syntax.
[expression for item in iterable if condition]
- expression: Operation you want to perform.
- item: The variable that represents each element in the iterable.
- iterable: Any iterable object, which is a list in our case.
- condition: A condition is optional and determines whether an item should be included in the list.
3. Joining the List Back Into a String
Finally, the list is joined backed into a string using the join() method.
joined_string = ' '.join(list_of_words)
list_of_words: The list containing individual words.
- join(): Combines the words from the list into a string with a space (' ') between each word.
- joined_string: The resulting string which can be printed.
So, as an example, let’s again replace ‘blue’ with ‘red’ in ‘The sky is blue’
sentence = 'The sky is blue.'
words = sentence.split()
new_words = ['red' if word == 'blue' else word for word in words]
new_sentence = ' '.join(new_words)
print(new_sentence)
In this example, the string is converted to a list using split(). Then, the list comprehension part iterates over each word in the list. If it matches ‘blue’, it’s replaced with ‘red’. If not, it keeps the original word.
The new string is created using join() on the list elements and putting a white space between them.
Finally, the output is printed, and…wait, there’s something wrong. The sentence stayed the same!?


You must be careful because split() uses blank space as a default limiter to create list elements. So, the above splitting actually returns this list.

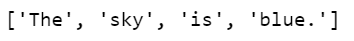
You see, the list element is ‘blue.’ (with a full stop!), not ‘blue’, as there’s no space between ‘blue’ and ‘.’ This has to be accounted for in the list comprehension part: ‘blue.’ will be replaced with ‘red.’
sentence = 'The sky is blue.'
words = sentence.split()
new_words = ['red.' if word == 'blue.' else word for word in words]
new_sentence = ' '.join(new_words)
print(new_sentence)
Now, the output is correct.


Interview Example: Replacing Character Using List Comprehension
Let’s solve this Google interview question and use list comprehension to replace characters.
Last Updated: February 2019
Find the top 3 most common letters across all the words from both the tables (ignore filename column). Output the letter along with the number of occurrences and order records in descending order based on the number of occurrences.
Link to the question: https://platform.stratascratch.com/coding/9823-common-letters
We need to find the three most common letters across all the words from both tables. The question also notes that we should ignore the filename column for the number of occurrences.
The first table is google_file_store, and we see that the data here is in the form of sentences.
The second table is google_word_lists. It’s a list of words separated by a comma.
We should output the top three letters and the number of their occurrences and sort the output in descending order.
In total, we will count the letter in three columns: contents from google_file_store and words1 and words2 from google_word_lists.
The first step is to split each of these columns into letters, convert the result to a list, and assign each list to three separate variables.
The first variable, df1, takes the column contents from google_file_store and converts it to lowercase. It then uses the split() method to split the string in the contents column by whitespace (the default behavior) and expand the result, i.e., each word will be shown in a separate column. We then use stack() to stack the columns on top of each other. Finally, the stacked result is converted to a list.
The second and third variables do a similar thing. The only difference is that there’s no converting to lowercase (the values already are in all-lowercase), and the strings are split by a comma.
All three variables are then combined into a list.
import pandas as pd
import numpy as np
df1 = google_file_store.contents.str.lower().str.split(expand=True).stack().tolist()
df2 = google_word_lists.words1.str.split(',', expand=True).stack().tolist()
df3 = google_word_lists.words2.str.split(',', expand=True).stack().tolist()
alist = df1 + df2 + df3
This is the partial output we get so far.
Next, we convert this list to one single string using join() and white space as a separator between the words. Then, we immediately convert the string into a list where each character is a list element using list().
The output is then converted to DataFrame so we can leverage pandas’ data processing capabilities in the next step.
tr=' '.join(alist)
a = list(tr)
letters = pd.DataFrame(a,columns=['letter'])
The code so far outputs this. In the partial output below, you can also see blank rows. They represent white spaces between the words, which are also treated as characters when converting from a string to a list.
We’ll use the list comprehension to get rid of those blank rows because white space is not a letter.
In the code below, the list comprehension iterates over the column letter and replaces the blank spaces (' ') with NaN values. After that, we can simply remove those rows with dropna().
Next, we want to cover the edge case and ensure the output really shows letters and not other characters, such as commas, full stops, or other non-alphabetical characters. For all we know, they can be among the three most common characters. So, we include only letters using the isalpha() method.
In the last code line, the output is grouped by letter, and the number of occurrences of each letter is counted by size(). Next, the counting result is converted into a DataFrame using to_frame(), and the index is reset so the letters become a regular column. The values are sorted by the number of occurrences descendingly, and the first three rows of the output are shown; those are the question’s requirements.
letters['letter'] = [np.nan if char == ' ' else char for char in letters['letter']]
letters = letters.dropna()
letters = letters[letters['letter'].str.isalpha()]
result = letters.groupby('letter').size().to_frame('n_occurences').reset_index().sort_values('n_occurences', ascending=False).head(3)
Put together, the solution looks like this.
import pandas as pd
import numpy as np
df1 = google_file_store.contents.str.lower().str.split(expand=True).stack().tolist()
df2 = google_word_lists.words1.str.split(',', expand=True).stack().tolist()
df3 = google_word_lists.words2.str.split(',', expand=True).stack().tolist()
alist = df1 + df2 + df3
tr=' '.join(alist)
a = list(tr)
letters = pd.DataFrame(a,columns=['letter'])
letters['letter'] = [np.nan if char == ' ' else char for char in letters['letter']]
letters = letters.dropna()
letters = letters[letters['letter'].str.isalpha()]
result = letters.groupby('letter').size().to_frame('n_occurences').reset_index().sort_values('n_occurences', ascending=False).head(3)
The output shows the most common letters are ‘a’, ‘e’, and ‘t’.
Now, those of you who paid a bit more attention probably noticed that some of the data conversions in the code seem redundant: we convert the data to a list, then to a string, and then immediately back to a list.
We can avoid that and optimize the code using one more list comprehension.
So, instead of three steps here,
tr=' '.join(alist)
a = list(tr)
letters = pd.DataFrame(a,columns=['letter'])we can use a list comprehension to directly iterate over each word in the list alist and then, for each word, to iterate over each character, and put them in the column letter of a DataFrame.
letters = pd.DataFrame([char for word in alist for char in word], columns=['letter'])
Since there’s no conversion to a string with blank spaces between the words, there’s also no need to use list comprehension to remove blank rows, i.e., these two code lines are not necessary anymore.
letters['letter'] = [np.nan if char == ' ' else char for char in letters['letter']]
letters = letters.dropna()
So, yes, I showed you how to use list comprehension to replace a character in a string. But I also showed you how to use it to optimize the code even further, to the point where removing characters is not needed at all!
Here’s the shortened code that includes all the optimizations above.
import pandas as pd
import numpy as np
df1 = google_file_store.contents.str.lower().str.split(expand=True).stack().tolist()
df2 = google_word_lists.words1.str.split(',', expand=True).stack().tolist()
df3 = google_word_lists.words2.str.split(',', expand=True).stack().tolist()
alist = df1 + df2 + df3
letters = pd.DataFrame([char for word in alist for char in word], columns=['letter'])
letters = letters[letters['letter'].str.isalpha()]
result = letters.groupby('letter').size().to_frame('n_occurences').reset_index().sort_values('n_occurences', ascending=False).head(3)
Regular Expressions for Advanced Replacement
For more complex replacement scenarios, Python regular expressions can be useful. These are sequences of characters that form a search pattern for matching text. We already used them in str.replace(), but when talking about using regular expressions for character replacement, I mean using the re.sub() function.
Python has a re module, which is a module for regular expression (or regex) operations that contains the re.sub() function. You can use this function to search patterns and replace them with specified characters.
Its syntax is as follows.
re.sub(pattern, repl, string, count=0, flags=0)
- pattern: The regular expression pattern to search for.
- repl: The replacement string.
- string: The string where to look for regular expression matches.
- count: The maximum number of pattern occurrences to replace. The default value is 0, i.e., replaces all occurrences.
- flags: Special matching behavior. The default value is 0, i.e., no special behavior is applied.
As a quick example, have a look at this code.
import re
s = "python1234string"
new_s = re.sub(r'\d', 'X', s)
print(new_s)
After importing the re module, we create the ‘python1234string’ string. Then we use the re.sub() method to replace all digits with ‘X’. Here, \d is a shorthand for the class [0-9], and r denotes a raw string, which ensures special characters are treated literally. This means \n is not treated as an escape sequence representing a newline, but literally. The s argument in the function is the input string.
The code returns this output.

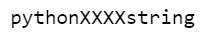
Interview Example: Replacing Character Using re.sub()
I’ll demonstrate how to use re.sub() in this City of San Francisco interview question.
Last Updated: June 2020
Find the number of words in each business name. Avoid counting special symbols as words (e.g. &). Output the business name and its count of words.
Link to the question: https://platform.stratascratch.com/coding/10131-business-name-lengths
The question tells us to find the number of words in each business name, but we shouldn’t count special symbols (e.g., &) as words. The output should show only the business name and the word count.
We have only one DataFrame to work with, namely sf_restaurant_health_violations.
As a first step in the code, we extract the column business_name from the sf_restaurant_health_violations DataFrame, remove duplicate values using drop_duplicates(), and convert the resulting Series into a DataFrame using to_frame().
Next, we use regular expressions to remove special characters from the business’ names. We do that by first applying a lambda function to each business name.
Then, we employ the re.sub() function. The r at the beginning denotes a raw string. The a-zA-Z0-9 specifies the characters to look for, which are only alphanumeric characters and space (note the space before the closing square bracket!). The ^ in front is a negation. This means alphanumeric characters and space will be excepted from the character replacement. All other characters (e.g., special characters) will be replaced with an empty string, specified as ''. The name variable represents the business names as they are iterated over within the lambda function.
Once we’ve cleaned business names, we can count the number of words. We use str.split() to split the name into a list of words by blank space and then len() to count the length of each list, i.e., we count the number of words.
Finally, we output the result with the business_name and name_word_count columns.
import pandas as pd
import numpy as np
import re
result = sf_restaurant_health_violations['business_name'].drop_duplicates().to_frame('business_name')
result['business_name_clean'] = result['business_name'].apply(lambda name: re.sub(r'[^a-zA-Z0-9 ]', '', name))
result['name_word_count'] = result['business_name_clean'].str.split().str.len()
result = result[['business_name', 'name_word_count']]
Here’s the output.
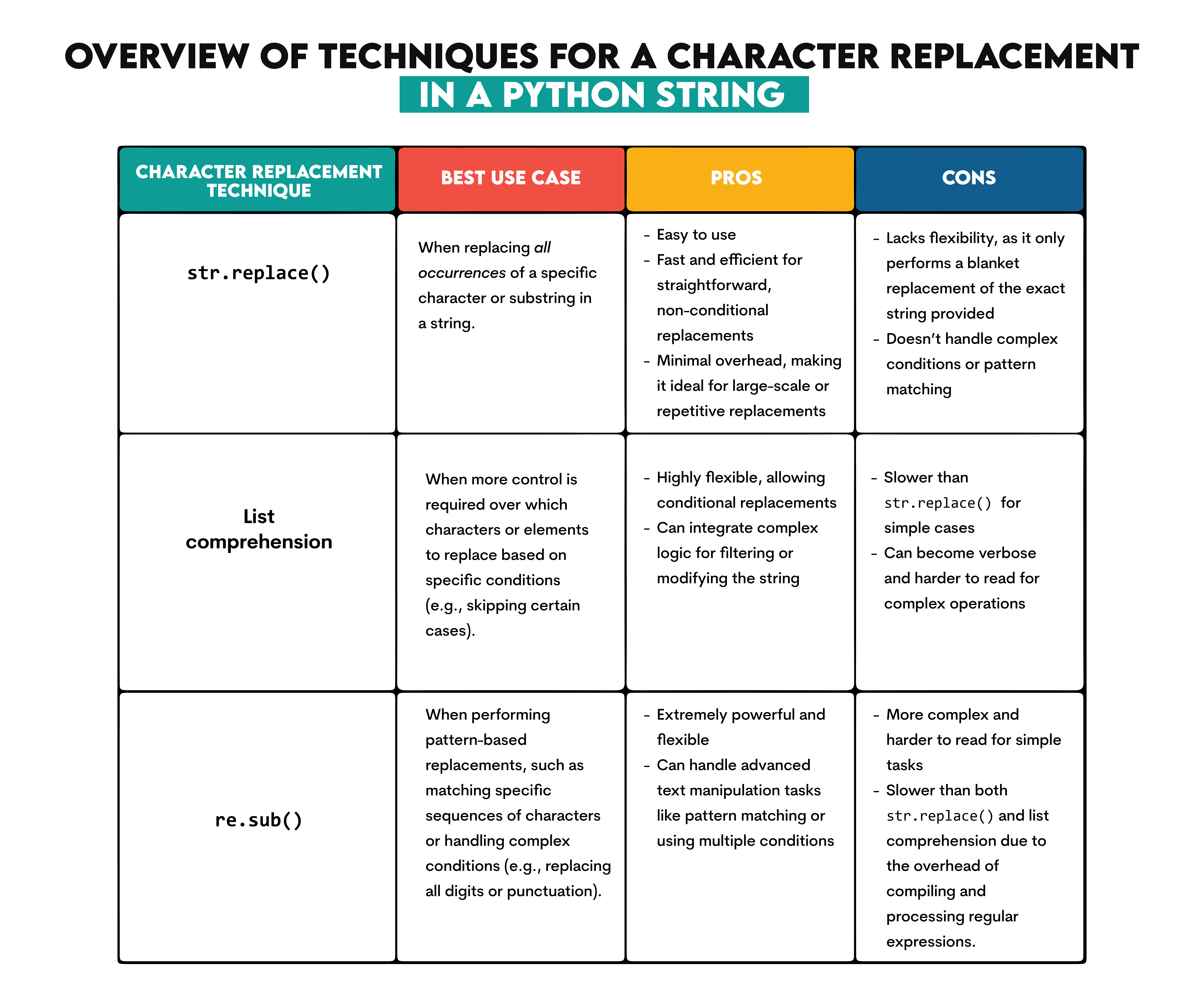
str.replace() vs. List Comprehension vs. Regular Expressions
All three methods have their place in replacing characters in a Python string, but they excel in different scenarios and have different trade-offs. Here’s an overview.

Handling Edge Cases
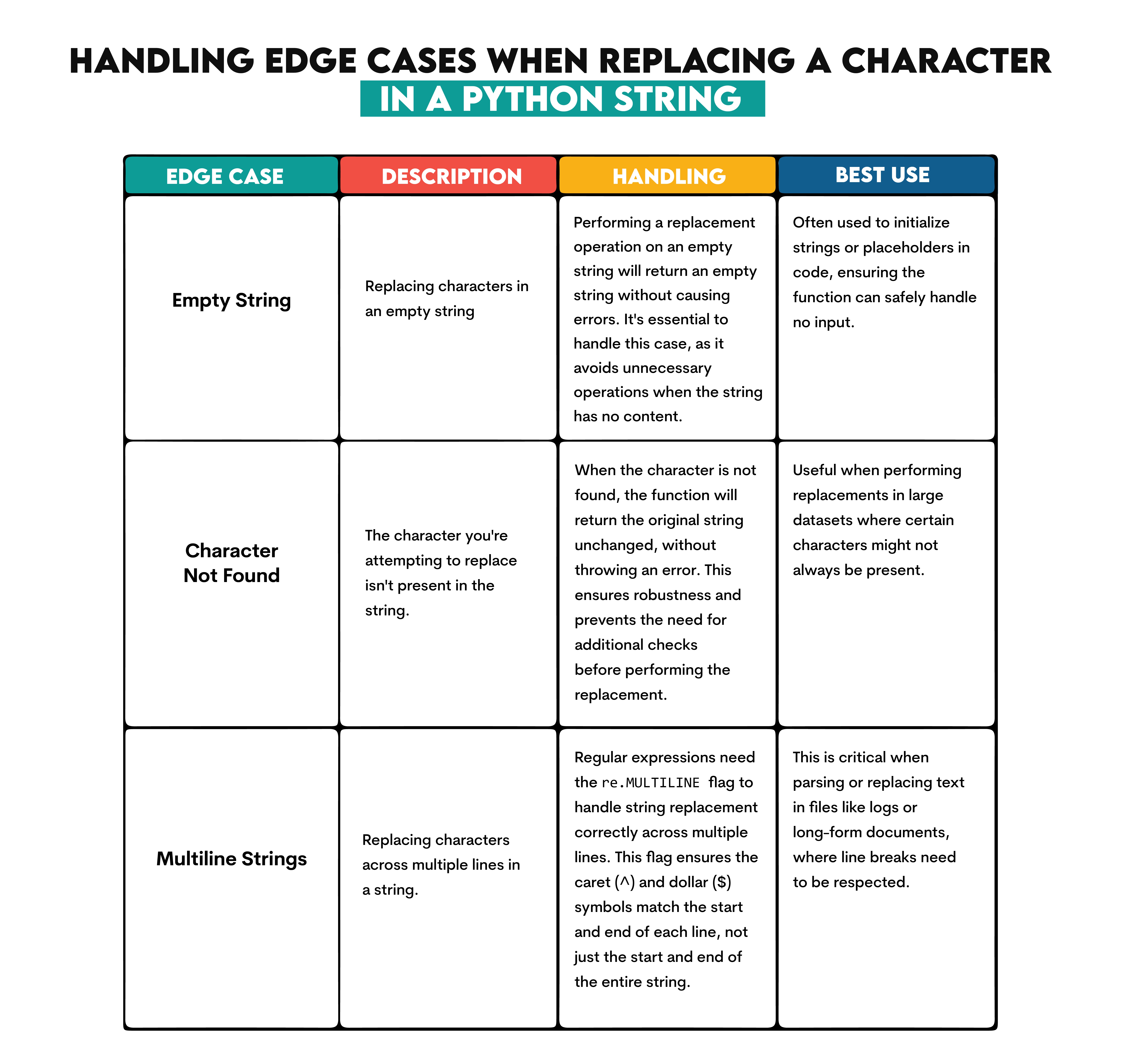
You should consider three main edge cases when writing code that replaces characters in a Python string.

When replacing characters in a Python string, you should build logic into the code to manage edge cases so the code doesn’t break or return an error.
Here is the overview of these scenarios.

Best Practices
There’s only one best practice I’d recommend: keep it simple! This means stick with str.replace() for basic replacements; it’s what it’s designed for, and it’s quick.
Use list comprehension when you really need more control over replacement, i.e., you can’t do it with str.replace(). The same goes for re.sub(): use it for what it’s designed for, which is pattern-based replacement.
Conclusion
This article taught you the three main techniques for replacing a character in a Python string:
- str.replace() – for straightforward replacements
- List comprehension – for flexible replacements and complex conditions
- re.sub() – for pattern-based replacement
It also demonstrated how to use these techniques in three practical examples from the StrataScratch choice of coding interviews.
Most important, however, is that you’ll become the life of every party with the information that strings in Python are immutable, and changing them doesn’t change them at all; it creates a new string! Enjoy your stardom.
But also, don’t forget to practice replacing a character in strings in the meantime. It is essential Python knowledge interviewers simply love to test.
Share


