How Do You Perform SQL LIKE Queries for Pattern Matching?

Categories:
 Written by:
Written by:Nathan Rosidi
The LIKE SQL query allows you to perform a pattern-matching search of your text data. Learn how to use it and add wildcards for increased flexibility.
In today's article, we will tackle the question of using the SQL operator LIKE to match patterns in text data.
We will talk about why pattern matching is important and how it’s done in SQL. You will learn the LIKE operator’s syntax and different variations in patterns. After that, we’ll show you how to perform simple pattern matching, but also some complex pattern matching examples.
Importance of Pattern Matching in SQL Queries
Being able to match patterns gives you flexibility when querying databases and makes it more customizable.

1. Increased Efficiency
Without pattern matching, you would have to know how exactly data in each column is stored to output precisely that data. Imagine being limited to retrieving only exact matches. If you want to output all the customers whose surname starts with the letter ‘B’, you would have to go through the whole database (thousands, tens of thousands, millions of rows?) and include each and every exact last name that starts with ‘B’. Talking about efficiency, ha? Pattern matching allows you to write only this one criterion – find the last names beginning with B – in your query, and it’ll output what you want.
2. Data Exploration
When you first explore data, you’ll be unfamiliar with it. Of course, that means you might not know search terms in advance. Pattern matching is one of the methods that allows you to get to know your data efficiently, as it allows ‘approximate’ querying. Once you know your data that way, you’ll be able to query it using exact matches.
3. Handling Incomplete Data
Even if you’re familiar with data, you might have to query data without the complete information. For instance, you’re looking for a customer, but you only have the last four digits of their phone number. If you look for a phone number that ends with, say, ‘8947’, you could find the customer or, at least, narrow down the search to several customers.
4. Data Cleaning
Data is often full of inconsistencies, especially when it comes from various data sources. Pattern matching is essential for data cleaning, as it allows you to search for data that doesn’t match a specific pattern, e.g., the initial of a middle name not followed by a dot, and correct these inconsistencies or plain mistakes.
5. Data Retrieval Customization
Customizing data searches has a wide application in extracting information from large text datasets, which are used in text mining, natural language processing, and log and transaction records analysis. Such customization requires the use of advanced pattern-matching techniques, which often involve the use of regular expressions (regex).
What is SQL LIKE Operator?
The LIKE operator is one of the numerous logical operators in SQL.
LIKE is commonly used in the WHERE clause to return data that matches a pattern specified in the LIKE operator. However, it can also be used in the HAVING clause or CASE WHEN statements.
It is commonly used with another logical operator, namely NOT. This does exactly the opposite of LIKE, as NOT LIKE returns all the data that doesn’t match a specified pattern.
Syntax of SQL LIKE Operator
As LIKE is most often used in the WHERE clause, it can be a part of SELECT, UPDATE, or DELETE statements.
The syntax of the LIKE operator itself is always the same. Here it is in the context of SELECT.
SELECT …
FROM table_name
WHERE column_name LIKE 'pattern';
The pattern in LIKE can include SQL wildcards, which is our next topic.
Differences Between %, _, and [ ] in Patterns
All three characters mentioned in the subheading above are SQL wildcards. They are special characters that substitute one or more characters in the pattern definition to be matched by a query.
The Percent Sign (%)
The percent sign (%) wildcard represents zero, one, or more characters, i.e., any character sequence. Where you put it in a pattern determines the positions of that character sequence.
For instance, the query below looks for the employees whose last name starts with ‘B’.
SELECT first_name,
last_name
FROM employees
WHERE last_name LIKE 'B%';
To look for the employees whose last name ends with ‘b’, you would write this.
SELECT first_name,
last_name
FROM employees
WHERE last_name LIKE '%B';
If you want to look for a pattern anywhere in a string, put a percent sign on either side of a pattern. The example below looks for employees whose last name contains ‘han’ anywhere in their last name. It would, for instance, return the Johanson last name.
SELECT first_name,
last_name
FROM employees
WHERE last_name LIKE '%han%';
The Underscore Sign (_)
This wildcard replaces only one sign at a specific position in a string.
For example, the code below will return all customers named Shawn or Shaun.
SELECT first_name,
last_name
FROM employees
WHERE first_name LIKE ‘Sha_n%’;
The Square Brackets ([ ])
This wildcard is used when looking for data that matches any single character from a data range or data set specified in the square brackets.
In this example, the query looks for values in the grade column, which contains single-character grades. It will output all the students with grades A, B, or C.
SELECT first_name,
last_name
FROM students
WHERE grade LIKE '[ABC]';
Case Sensitivity and Collation
Collation in the database refers to the rules for sorting and comparing data. This is important for pattern matching, as collation can be case-insensitive or case-sensitive, depending on the database you use.
If your database performs a case-sensitive data search, then the pattern looking for Shaun or Shawn has to be written like below, i.e., with the capital ‘S’.
SELECT first_name,
last_name
FROM employees
WHERE first_name LIKE 'Sha_n%';
If the search is case-insensitive, then you could even write the query with the lowercase ‘s’; it would nevertheless return Shaun or Shawn.
SELECT first_name,
last_name
FROM employees
WHERE first_name LIKE 'sha_n%';
Here’s an overview of the most popular databases and their default search setup.
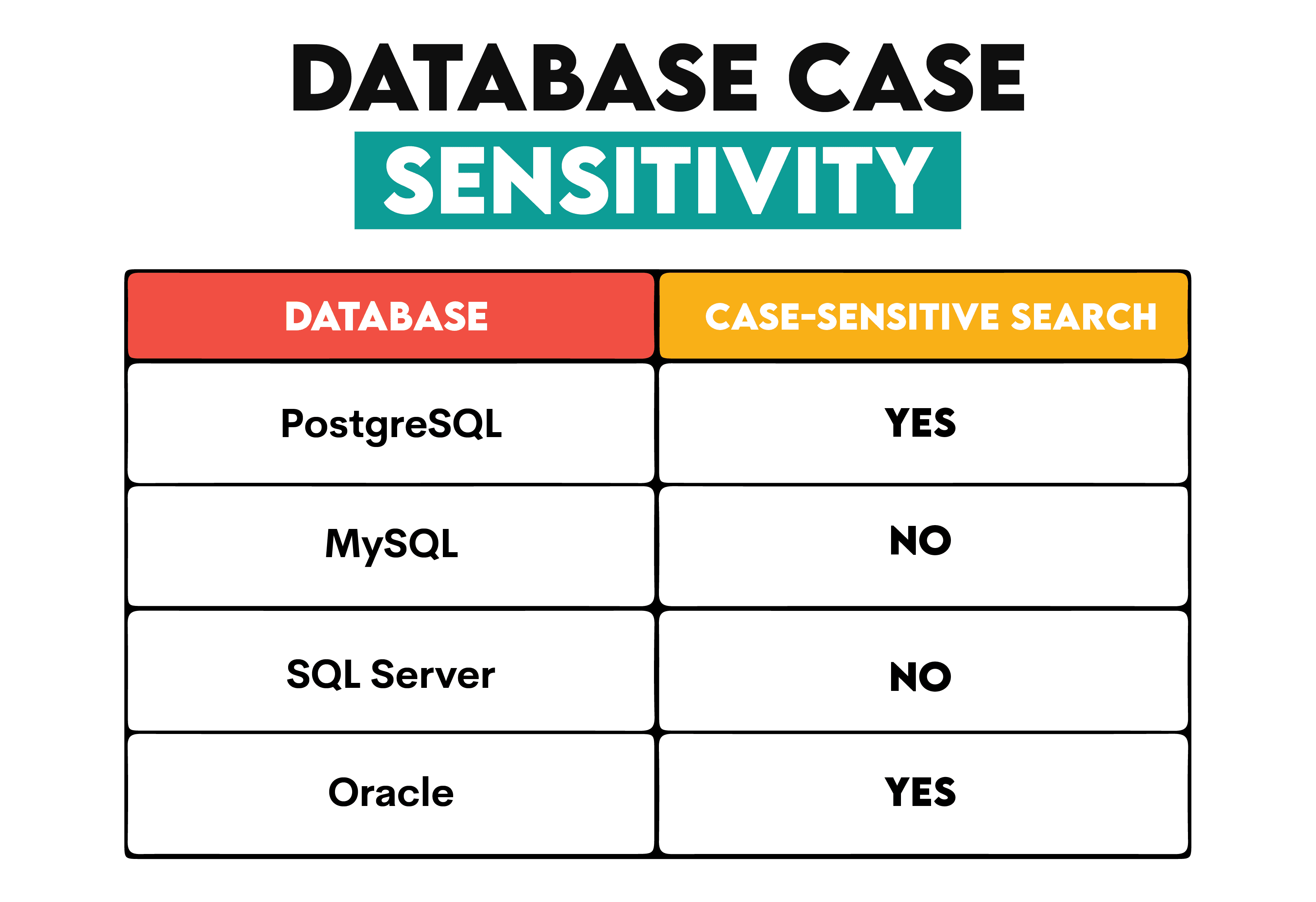
In most examples, we will use the PostgreSQL syntax, so it’s important to say it has the operator ILIKE. It’s the same as LIKE, with the same syntax, only case-insensitive. We’ll use both, depending on the suitability.
So, remember: LIKE for case-sensitive searches, ILIKE for case-insensitive searches.
Basic Usage of SQL LIKE
Now that we have the fundamentals in place let's learn how to use LIKE in practice.
Simple Pattern Matching
How to perform a simple pattern matching using LIKE is demonstrated in this Shopify interview question.
Shipped by Speedy Express
Last Updated: June 2022
How many orders were shipped by Speedy Express in total?
Link to the question: https://platform.stratascratch.com/coding/2116-shipped-by-speedy-express
The question asks you to find the number of orders shipped by Speedy Express.
There are two tables to work with. The first table is shopify_orders.
The second is shopify_carriers.
The solution is simple. It joins the tables and uses COUNT(*) to count the orders. To do that only for the Speedy Express carrier, we need to look in the column name for this pattern defined in LIKE.
Also, since we’re using the case-insensitive search (LIKE), we need to spell the carrier name correctly with a capital ‘S’ and a capital ‘E’.
SELECT COUNT(*) AS n_shipped
FROM shopify_orders
JOIN shopify_carriers ON carrier_id = id
WHERE name LIKE 'Speedy Express';
The output shows there are seven orders shipped by Speedy Express.
| n_shipped |
|---|
| 7 |
Of course, using LIKE in that manner actually looks for an exact string, so you could get the same result using the equals operator (=) instead.
SELECT COUNT(*) AS n_shipped
FROM shopify_orders
JOIN shopify_carriers ON carrier_id = id
WHERE name = 'Speedy Express';
Pattern Matching Using the % Wildcard
I’ll show you two examples of using the percentage wildcard. The first example uses the single % wildcard, while the second uses two.
Single % Wildcard
Here’s an interesting example by Google.
Number Of Custom Email Labels
Find the number of occurrences of custom email labels for each user receiving an email. Output the receiver user id, label, and the corresponding number of occurrences.
Link to the question: https://platform.stratascratch.com/coding/10120-number-of-custom-email-labels
The question requires us to find the number of occurrences of custom email labels for each user receiving an email.
We need to query two tables, the first one being google_gmail_emails.
The second table is named google_gmail_labels.
The solution selects the required columns and uses COUNT(*) to find the number of email label occurrences.
However, we only need to output emails with custom labels. Scrolling through the table google_gmail_labels reveals multiple custom labels, e.g., ‘Custom_3’ or ‘Custom_2’.
So, we basically need to look for all the labels that begin with ‘custom’. That’s exactly what we do by specifying putting the % wildcard at the end of the ‘custom%’ pattern in ILIKE. It will case-insensitively look for the labels that begin with ‘custom’, regardless of what follows it, if anything.
SELECT to_user AS user_id,
label,
COUNT(*) AS n_occurences
FROM google_gmail_emails e
INNER JOIN google_gmail_labels l
ON e.id = l.email_id
WHERE l.label ILIKE 'custom%'
GROUP BY to_user, label;
The output shows the user ID, the email labels, and the number of occurrences.
| user_id | label | n_occurences |
|---|---|---|
| 114bafadff2d882864 | Custom_1 | 2 |
| 114bafadff2d882864 | Custom_2 | 1 |
| 114bafadff2d882864 | Custom_3 | 1 |
| 157e3e9278e32aba3e | Custom_1 | 1 |
| 157e3e9278e32aba3e | Custom_2 | 4 |
Double % Wildcard
As we already mentioned, using LIKE is not limited to WHERE. You can use it in the conditional expression CASE WHEN like this Airbnb interview question requires.
Total Searches For Rooms
Last Updated: February 2018
Find the total number of searches for each room type (apartments, private, shared) by city.
Link to the question: https://platform.stratascratch.com/coding/9638-total-searches-for-rooms
You need to find the total number of searches for each room type using the table airbnb_search_details.
The room types are apartment, private, and shared. We select the city and then count the searches for each room type separately using COUNT(), CASE WHEN, and LIKE.
The LIKE operator is used to look for the keywords ‘apt’, ‘private’, and ‘shared’ anywhere in the string, which we achieve by putting the % wildcard on both sides of the string. In other words, the room type string can, for example, start with ‘apt’, end with it, or contain it anywhere in the name.
The CASE WHEN statement says that whenever the data matches the pattern stated in LIKE, it will output the column id, and COUNT() will count it as one search. If the data doesn’t match the pattern in LIKE, CASE WHEN will output NULL, which can’t be counted by COUNT().
SELECT city,
COUNT(CASE
WHEN room_type ILIKE '%apt%' THEN id
ELSE NULL
END) apt_count,
COUNT(CASE
WHEN room_type ILIKE '%private%' THEN id
ELSE NULL
END) private_count,
COUNT(CASE
WHEN room_type ILIKE '%shared%' THEN id
ELSE NULL
END) shared_count
FROM airbnb_search_details
GROUP BY 1;
Here’s the required output.
| city | apt_count | private_count | shared_count |
|---|---|---|---|
| DC | 0 | 1 | 0 |
| Chicago | 3 | 1 | 0 |
| LA | 34 | 25 | 4 |
| NYC | 43 | 35 | 3 |
| SF | 3 | 4 | 0 |
| Boston | 1 | 3 | 0 |
Advanced Pattern Matching Techniques
Now, we will show several examples of advanced pattern matching.
Using the Underscore (_) Wildcard for Single Character Matching
We’ll use the question by Google and Netflix and change its requirements so it requires using the underscore wildcard.
Top Percentile Fraud
Last Updated: November 2020
We want to identify the most suspicious claims in each state. We'll consider the top 5% of claims (those at or above the 95th percentile of fraud scores) in each state as potentially fraudulent.
Your output should include the policy number, state, claim cost, and fraud score.
Link to the question: https://platform.stratascratch.com/coding/10303-top-percentile-fraud
There’s the fraud_score dataset.
We will use it to output the policy, claim cost, and fraud score and rank them by the fraud score ascendingly. We will do that only for the policies whose numerical part of the name is above 1149 but below 1160.
The data in the column policy_num is text type, not numerical, so we can’t use the numerical comparison operator. How do we then solve this problem? We can, of course, use LIKE with the underscore wildcard.
We list the relevant columns and use DENSE_RANK() to rank policies by the fraud score. To do that only for the policies satisfying the above criteria, we simply write the policy name as ‘ABCD115_’. This will return all the policies from ABCD1150 to ABCD1159.
SELECT policy_num,
claim_cost,
fraud_score,
DENSE_RANK() OVER (ORDER BY fraud_score) AS rank_fraud_score
FROM fraud_score
WHERE policy_num ILIKE 'ABCD115_';
Here’s the list of these ten policies.
| policy_num | claim_cost | fraud_score | rank_fraud_score |
|---|---|---|---|
| ABCD1159 | 4794 | 0.02 | 1 |
| ABCD1150 | 1997 | 0.03 | 2 |
| ABCD1156 | 1238 | 0.25 | 3 |
| ABCD1158 | 2958 | 0.28 | 4 |
| ABCD1155 | 2139 | 0.44 | 5 |
| ABCD1154 | 2956 | 0.54 | 6 |
| ABCD1152 | 1494 | 0.64 | 7 |
| ABCD1157 | 4017 | 0.64 | 7 |
| ABCD1153 | 1385 | 0.79 | 8 |
| ABCD1151 | 2874 | 0.96 | 9 |
Using the Square Bracket ([ ]) Wildcard for Character Range Matching
I’ll use this example from the City of Los Angeles, the City of San Francisco, and Tripadvisor.
Find the lowest score for each facility in Hollywood Boulevard
Last Updated: July 2020
Find the lowest score per each facility in Hollywood Boulevard. Output the result along with the corresponding facility name. Order the result based on the lowest score in descending order and the facility name in the ascending order.
Link to the question: https://platform.stratascratch.com/coding/10180-find-the-lowest-score-for-each-facility-in-hollywood-boulevard
We’ll work with the table los_angeles_restaurant_health_inspections.
We’ll ignore the question requirements and make our own. Let’s write a query that will show the grades and the highest and the lowest scores by grade.
We heard that the grades go from A to F, but we want only the three best grades, i.e., A, B, and C.
We use the MIN() and MAX() aggregate functions in the query to find the highest and lowest scores. To output only the desired grades, we can use the square brackets wildcard to specify the value range. In this case, it’s A-C, i.e., it will include grade A, grade C, and anything in between, which is only grade B, in this case.
SELECT grade,
MIN(score) AS min_score,
MAX(score) AS max_score
FROM los_angeles_restaurant_health_inspections
WHERE grade LIKE '[A-C]'
GROUP BY grade
ORDER BY grade;
Unfortunately, this code will work only in SQL Server, but not in PostgreSQL. Why? Because it doesn’t support character ranges within square brackets. One of the solutions for this problem is to use the tilde operator (~) instead of LIKE. It is the operator for regular expression matching.
So, the code rewritten for PostgreSQL looks like this.
SELECT grade,
MIN(score) AS min_score,
MAX(score) AS max_score
FROM
los_angeles_restaurant_health_inspections
WHERE grade ~ '[A-C]'
GROUP BY grade
ORDER BY grade;
In both cases, the output is as shown below.
| grade | min_score | max_score |
|---|---|---|
| A | 90 | 100 |
| B | 80 | 88 |
| C | 70 | 79 |
Combining %, _, and [ ] for Complex Patterns
Now that we learned how to use each wildcard separately, let’s combine them in one LIKE operator and search for complex patterns.
Here’s the interview question by Google.
Activity Rank
Last Updated: July 2021
Find the email activity rank for each user. Email activity rank is defined by the total number of emails sent. The user with the highest number of emails sent will have a rank of 1, and so on. Output the user, total emails, and their activity rank.
• Order records first by the total emails in descending order. • Then, sort users with the same number of emails in alphabetical order by their username. • In your rankings, return a unique value (i.e., a unique rank) even if multiple users have the same number of emails.
Link to the question: https://platform.stratascratch.com/coding/10351-activity-rank
We’ll not solve it, we’ll only use its dataset, which consists of one table named google_gmail_emails.
We want to output the list of all email senders whose code starts with the letters from C to E and the third character is ‘e’.
We will have to use the [ ] wildcard, so let’s write the code in SQL Server, since PostgreSQL doesn’t allow that wildcard with LIKE.
The query selects a distinct combination of the email sender, receiver and the sending day.
To output the list only for the specific senders, we need to use LIKE in WHERE. The pattern in LIKE first specifies the range of first letters, i.e., C-E. We want the sender code to start with one of those letters, so this range is followed by % wildcard. We also want that the third character is ‘e’, and the second character can be anything; we don’t care about it. That’s why we add the underscore wildcard to replace the second character, which should be then followed by the letter ‘e’.
SELECT DISTINCT from_user,
to_user,
day
FROM google_gmail_emails
WHERE from_user LIKE '[C-E]_e%';
Look at the output, and you’ll see only senders matching the pattern in LIKE. Actually, there’s only one such email sender.
| from_user | to_user | day |
|---|---|---|
| e0e0defbb9ec47f6f7 | 157e3e9278e32aba3e | 7 |
| e0e0defbb9ec47f6f7 | 2813e59cf6c1ff698e | 4 |
| e0e0defbb9ec47f6f7 | 32ded68d89443e808 | 6 |
| e0e0defbb9ec47f6f7 | 47be2887786891367e | 8 |
| e0e0defbb9ec47f6f7 | 55e60cfcc9dc49c17e | 5 |
Performance Considerations
While using pattern matching with LIKE is necessary to achieve querying flexibility, it can have a detrimental influence on query performance.
This primarily applies to using LIKE with a leading wildcard – e.g., ‘%son’ – which hinders the use of indexes. They depend on starting characters for quickly locating data, which is negated by using a leading wildcard, i.e., you want the data to start with any character.
Mitigating Performance Issues
One approach is to use the full-text search. Here’s an example for PostgreSQL that looks in the column name of the table employees to return all the employees whose last name contains ‘son’.
SELECT *
FROM employees
WHERE to_tsvector(last_name) @@ to_tsquery('son');
The full-text indexes are optimized for searching within text data. The to_tsvector function converts the column last_name into a text search vector. The to_tsquery function converts the search term into a text search query.
The @@ operator checks if the text search vector on the left matches the text search query on the right.
Another approach is reverse indexing. This requires creating an additional column with the reversed data from the column you want to search and indexing it.
ALTER TABLE employees ADD COLUMN reversed_name TEXT;
UPDATE employees SET reversed_last_name = reverse(last_name);
CREATE INDEX idx_reversed_last_name ON employees(reversed_last_name);
Then you can show all the last names ending with ‘son’ like this.
SELECT *
FROM employees
WHERE reversed_last_name LIKE reverse('son%');
The third approach is using trigram indexes. They are useful for approximate string matching and can improve the performance of wildcard searches.
First, you need to enable the pg_trgm extension, which provides functions and operators for determining the similarity of text based on trigram matching. Next, you create a trigram index.
CREATE EXTENSION pg_trgm;
CREATE INDEX idx_last_name_trgm ON employees USING gin (last_name gin_trgm_ops);
Then you can search for the pattern like this.
SELECT *
FROM employees
WHERE last_name LIKE '%son%';
Conclusion
The LIKE operator allows you to look for patterns in text data. Whether it’s case-sensitive or case-insensitive search, depends on the database you use. In PostgreSQL, which is case-sensitive, applying the case-insensitive search is easy: simply use the ILIKE operator instead of LIKE, with the syntax remaining the same.
Using wildcards adds to the search flexibility, increasing your search and data exploration efficiency and allowing you to handle incomplete data, clean it, and customize data retrieval.
Learning how to use LIKE and wildcards effectively requires a lot of practice in actual code writing. You’ll find plenty of examples in our coding questions section, where you can apply LIKE and wildcards in solving real-world problems.
You can find many useful articles in the blog section, such as this one, explaining different SQL query interview questions.
Share