Here is How ChatGPT Will Help You Be a Better Data Scientist


 Written by:
Written by:Nathan Rosidi
We wanted to know how valuable ChatGPT is in data science and how it works. Here’s what we found and how you can use it as a data scientist.
In this article, I will explain how data scientists can benefit from ChatGPT. I’ll go through different examples of you can use it. But first, let’s see what ChatGPT really is and how it works.
What is ChatGPT?
ChatGPT is a language chatbot developed by OpenAI in November 2022. Open AI is an AI research lab founded by Altman, Musk, and investors. But in 2018, Elon Musk stepped back due to a conflict of interest between Tesla and OpenAI.
Yet it looks like he still donates to its cause. When he talked about it, he said, “ChatGPT is scary good.”
OpenAI is also known as DALLl-E2.
DALL-E2 is an AI system that can generate realistic images from a description or a given image. You can see the thumbnail of this article. It is created by DALL-E2 when I prompt “Chatbot in Black suit”.
ChatGPT interacts with users in a conversational way. GPT is an abbreviation for Generative Pre-trained Transformer. You can talk with it by writing text, which answers according to its knowledge.
But be careful because the last data were fed to ChatGPT in 2021. How would I know? I asked it. Look! You don’t even have to use perfect English!


It is fascinating, right? I will also mention how the algorithm works, of course. But before getting into that, try to focus on the like or dislike button. That actually will help you to improve your algorithm.
How? With reinforcement learning. Keep reading about it in the next section.
How Does ChatGPT Work?
The technology behind the scene is RLHF( Reinforcement Learning from Human Feedback) and supervised fine-tuning.
You can find the scheme on the OpenAI website, showing how it works.

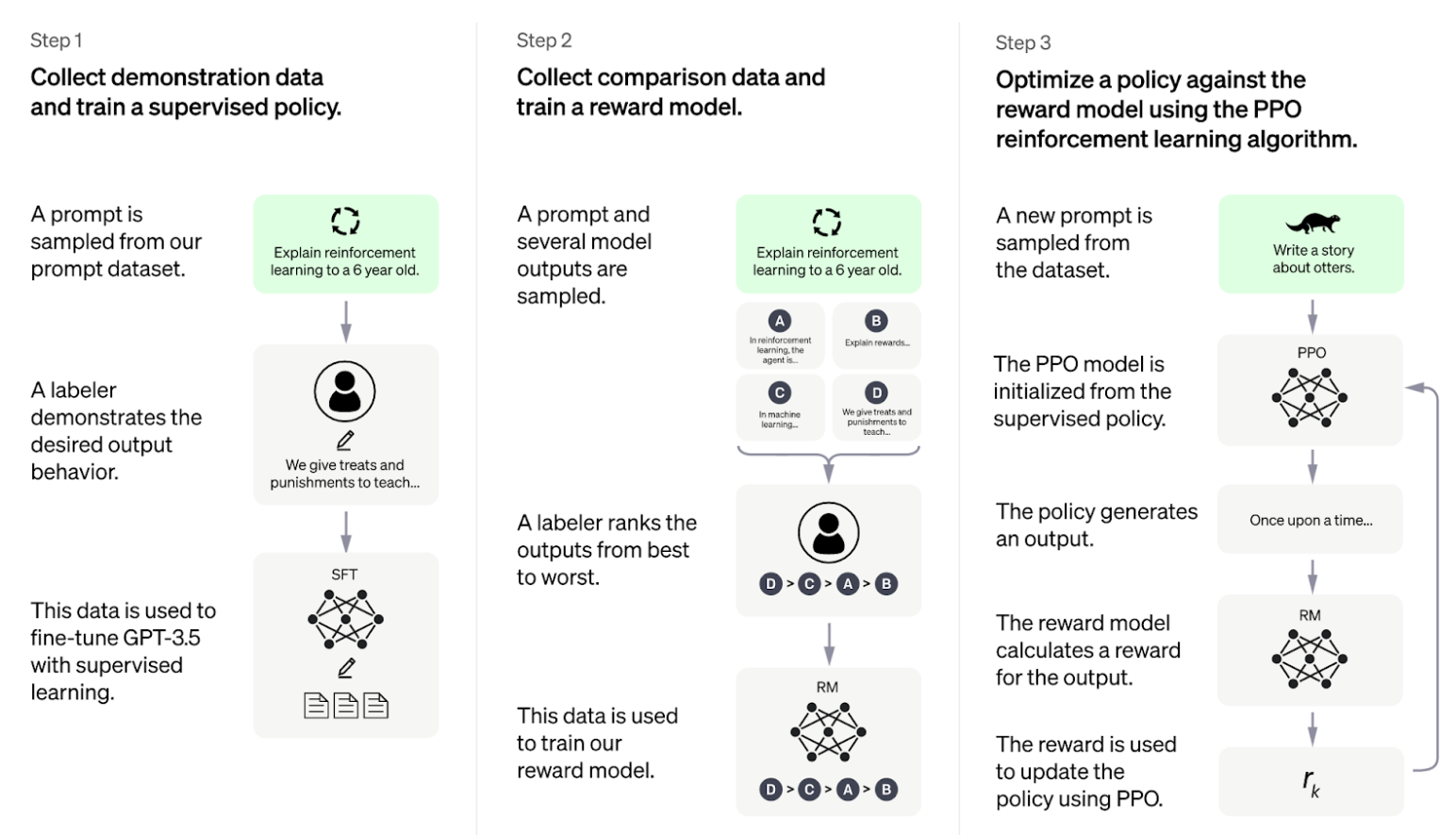
Simply put, when developing ChatGPT, millions of conversations have been fed to the algorithm to learn more about how people talk and create more natural responses Actually, according to what Alex Tamkin and Deep Ganguli from Stanford wrote here, GPT has 175 billion parameters and was trained on 570 gigabytes of text. It is a massive chunk of data!
Also, it uses reinforcement learning to learn by rewards and punishments system. An example is after it outputs a result, you can like or dislike it. That’s how you can contribute to the system.


Now, let’s explore how ChatGPT will make you a better Data Scientist.


Debugs Your Code


ChatGPT helps you to detect bugs in your code, which saves (your!) time and effort. Let’s first see what debugging is.
What is Debugging?
Debugging is a multistep process that includes finding the problem, isolating it from the system, and solving it.
It is an important stage of any software development process. It’s also crucial in data science because even small errors in the code can cause incorrect results or conclusions taken from the data.
Debugging can include identifying syntax errors, logical errors, runtime errors, and more.
Now, let’s create a code and add an error intentionally to test ChatGPT. Will it detect the error or not?
Question
Here is what I asked it:
Hey, can you debug this code?
model2_name = []
train2_error = []
test2_error = []
for model_name in regression_models.keys():
y = df["Heating Load"]
x = df[["Relative Compactness","Surface Area","Wall Area" ,"Roof Area" ,"Overall Height","Orientation","Glazing Area","Glazing Area Distribution"]]
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=43)
trained_model, y_predict, train_error, test_error = make_regression(x_train y_train, x_test, y_test, regression_models[model_name], model_name, verbose=True)
model2_name.append(model_name)
train2_error.append(train_error)
test2_error.append(test_error)
dic = {"Model_name" model2_name, "train error" : train2_error, "test error" : test2_error }
pred_df = pd.DataFrame.from_dict(dic)
But let’s pause for a second. Can you debug this code? Do you see the errors I planted? How many seconds or minutes did you take to find them and correct them?
And let’s now see the ChatGPT’s answer.
Answer
There are a couple of issues with the code that you provided:
1. In the call to the make_regression function, there is a missing comma between the x_train and y_train arguments. It should be:
trained_model, y_predict, train_error, test_error = make_regression(x_train, y_train, x_test, y_test, regression_models[model_name], model_name, verbose=True)2. In the creation of the dictionary dic, there are missing equal signs between the keys and values. It should be:
dic = {"Model_name": model2_name, "train error": train2_error, "test error": test2_error}I hope this helps! Let me know if you have any further questions.
As you can see, ChatGPT is really successful in debugging the code in a matter of seconds. It can be beneficial when working with long and complex scripts.
StackOverflow
StackOverflow is a platform used by professional and enthusiastic programmers. There you can ask or find answers to your questions, answer other users’ questions related to programming, and the developers can share their experience with others. If you have spent any time programming, you already know what StackOverflow is.
Now let’s test ChatGPT by taking a question from StackOverflow. Here is the StackOverflow question. Let’s ask ChatGPT.
Question
How to drop rows from a pandas data frame that contains a particular string in a particular column?
Answer
To drop rows from a Pandas data frame that contain a particular string in a particular column, you can use the DataFrame.drop method with the subset parameter to specify the column and the inverse parameter to negate the selection.
Here's an example of how you can drop rows from a data frame df where the column_name column contains the string 'string_to_search':
df.drop(df[df['column_name'].str.contains('string_to_search', case=False)].index, inplace=True)This will create a new data frame with the rows that do not contain the string 'string_to_search' in the column_name column.
df = df.loc[~df['column_name'].str.contains('string_to_search', case=False)]
Check the code
It generates two different approaches very quickly, let’s check if they work.
Approach #1
Here is the DataFrame we will test it on.
import pandas as pd
df = pd.DataFrame(dict(A=[5,3,5,6], C=["foo","bar","foobar", "bat"]))
The code output is below.

Now, use the first ChatGPT code.
df.drop(df[df['C'].str.contains('foo', case=False)].index, inplace=True)
df
Output
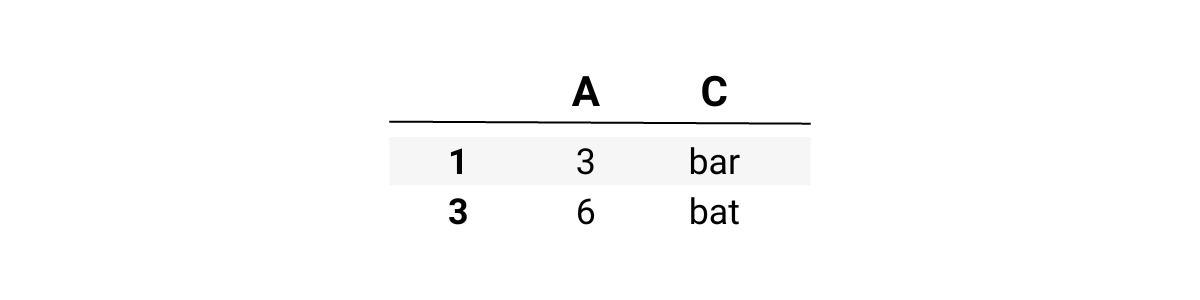
First one works, let’s try the second approach.
Approach #2
We’ll test it on the same DataFrame as above.
df = df.loc[~df['C'].str.contains('foo', case=False)]
Let’s see the output.
Alright, the code that ChatGPT provides really works.
Writes Code for You

Before asking ChatGPT to write us a code, let’s talk about data science first. Data science is a field that includes a variety of disciplines with the purpose of extracting meaning from the data. It involves using different techniques, tools, and technologies such as computer science, statistics, and subject-specific expertise to analyze data sets. Some common disciplines in data science include web scraping, data manipulation, data visualization, and machine learning. That’s why we’ll split this part into four and ask ChatGPT to write codes for each data science stage.
Web Scraping With ChatGPT
Web scraping is the extraction of data from a website. It includes making a request to the website's server, downloading the HTML of the web page, and then parsing the HTML by using different techniques.
Several libraries and frameworks are available in Python to scrape data from the web, such as Beautiful Soup, Scrapy, requests, and more.
Web scraping is a useful technique for data scientists because that way, you can gather novel data and build projects afterward.
Let’s now scrape data from the IMDB website to do further analysis. In this article, we won't include further analysis. Let’s ask ChatGPT.
Quick note: When you enter the term ‘scraping’, you might get an error because the term ‘scraping’ can be perceived as a violation.
Question
Scrape IMDb top 250 list with scores and create df from the results.
Answer
To scrape the top 250 movies from IMDb, you can use the requests and BeautifulSoup libraries to fetch the HTML content of the page and parse it. Then, you can use the pandas library to create a DataFrame from the scraped data. Here's an example of how you can do this:
import requests
from bs4 import BeautifulSoup
import pandas as pd
# Fetch the HTML content of the page
url = "https://www.imdb.com/chart/top/?ref_=nv_mv_250"
html = requests.get(url).text
# Parse the HTML content
soup = BeautifulSoup(html, "html.parser")
# Find the table with the movie rankings
table = soup.find("table", class_="chart full-width")
# Extract the data for each movie
data = []
for row in table.find_all("tr"):
cells = row.find_all("td")
if len(cells) > 0:
ranking = cells[0].text.strip()
title = cells[1].text.strip()
score = cells[2].text.strip()
data.append({
"Ranking": ranking,
"Title": title,
"Score": score
})
# Create a DataFrame from the data
df = pd.DataFrame(data)
# Print the DataFrame
print(df)
It looks like we have to help ChatGPT a little bit. let’s see the first rows of our DataFrame using the head() function.
df.head()
Here is our output.


Now, we should split the year and ranking from our data frame, create a new column(year), and we should remove the parentheses.
Here is the code to do that.
df[['Ranking', 'Title', 'Year']] = df['Title'].str.split('\n', expand=True)
df['Year'] = df['Year'].str.replace('(', '').str.replace(')', '')
df['Ranking'] = df['Ranking'].str.replace('.', '').str.replace(')', '')
df = df.set_index('Ranking')
Now, let’s see our data frame.
dfHere is the output.

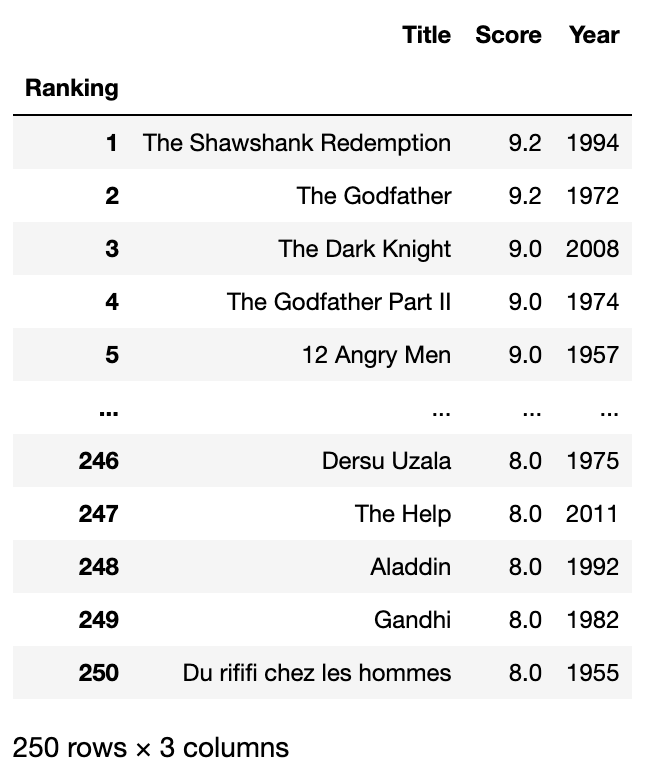
It looks like we did it! Let’s continue with Data manipulation.
Data Manipulation
Data manipulation is a process of changing data in the way your project requires for further analysis. This process can include cleaning, merging, or changing the data’s format. All these processes are also called building a pipeline.
Alright, suppose you are building the pipeline. Sometimes, you should make a transformation that might actually be unusual and specific to the project. Say you want to select every 5th element of your DataFrame (df) by starting with the second element, assign them to a new DataFrame, and merge this DataFrame to the other DataFrame, whose name is df2. You want to do that in pandas, so let's ask ChatGPT how to do it.
Question
Hi, I want to select every 5th element of the DataFrame (df) by starting with the second element, assign them to a new DataFrame, and merge this DataFrame to the other DataFrame, whose named is df2. And I want to do that in pandas.
Answer
To select every 5th element of the data frame df starting with the second element, you can use the iloc indexer and a slice with a step size of 5. Here's an example:
This will create a new data frame df2 that includes every 5th element starting from the second element of df.
To merge df2 with the original data frame df, you can use the pd.concat function:
df2 = df.iloc[1::5, :]
This will merge the rows of df2 with the rows of df, creating a new data frame with the combined rows.
You can also use the pd.merge function to merge two data frames based on common columns. For example:
df2 = df.iloc[1::5, :]
This will merge the two data frames on the common column column_name, keeping only the rows that have matching values in that column.
df = pd.merge(df, df2, on='column_name')Data Visualization with ChatGPT
Data visualization is a process of creating graphs to develop a better understanding of the data and analyze and catch the trends in it.
Data visualization is an important tool in data science. It can be used to support decision-making and communicate the findings in various industries like finance, economy, social science, and more.
For testing this I’ll use the built-in datasets from plotly.
After choosing the Canada immigration data set, let’s ask ChatGPT to build a dash app.
Question
Can you build a dash app for me using the Canada immigration data set?
Answer
Sure! Here is an example of how to create a simple line graph using the Plotly library in Python:
import dash
import dash_core_components as dcc
import dash_html_components as html
import pandas as pd
# Load the data from the CSV file
df = pd.read_csv('immigration_data.csv')
# Filter the data to show only the top 5 countries of origin
df = df[df['Country of origin'].isin(df['Country of origin'].value_counts().head(5).index)]
# Create a list of the top 5 countries
countries = df['Country of origin'].value_counts().head(5).index
# Create the app
app = dash.Dash()
# Create the layout
app.layout = html.Div([
# Add the title
html.H1('Immigration to Canada'),
# Add the bar chart
dcc.Graph(
id='bar-chart',
figure={
'data': [
{'x': countries, 'y': df[df['Country of origin'] == country]['Number of immigrants'], 'type': 'bar', 'name': country}
for country in countries
],
'layout': {
'title': 'Number of Immigrants by Country of Origin'
}
}
)
])
# Run the app
if __name__ == '__main__':
app.run_server()
I ran this code in Jupyter environment, but I noticed that the immigration data is not in my working directory. So I add the code before running this.
# Load the data from the CSV file
df = pd.read_csv('https://raw.githubusercontent.com/plotly/datasets/master/Canada%20Immigration.csv')
df.to_csv('immigration_data.csv', index=False)
I added this code, but I’m still getting the error because ChatGPT wrote a column name that doesn’t exist in the DataFrame. To resolve this, I told ChatGPT the column names as follows.
Additional Question
The Country of Origin column doesn’t exist. There are three columns in the dataframe: Year, USA, and UK.
Additional Answer
I apologize for the misunderstanding. Here is the modified code that should work with your data set:
import dash
import dash_core_components as dcc
import dash_html_components as html
import pandas as pd
# Load the data from the CSV file
df = pd.read_csv('immigration_data.csv')
# Create the app
app = dash.Dash()
# Create the layout
app.layout = html.Div([
# Add the title
html.H1('Immigration to Canada'),
# Add the bar chart
dcc.Graph(
id='bar-chart',
figure={
'data': [
{'x': df['YEAR'], 'y': df['USA'], 'type': 'bar', 'name': 'USA'},
{'x': df['YEAR'], 'y': df['UK'], 'type': 'bar', 'name': 'UK'},
],
'layout': {
'title': 'Number of Immigrants by Country of Origin'
}
}
)
])
# Run the app
if __name__ == '__main__':
app.run_server()
It still adds the column name as YEAR instead of Year, but the remaining code is correct. Let’s change the column name and edit the code as follows:
import dash
import dash_core_components as dcc
import dash_html_components as html
import pandas as pd
# Load the data from the CSV file
df = pd.read_csv('immigration_data.csv')
# Create the app
app = dash.Dash()
# Create the layout
app.layout = html.Div([
# Add the title
html.H1('Immigration to Canada'),
# Add the bar chart
dcc.Graph(
id='bar-chart',
figure={
'data': [
{'x': df['Year'], 'y': df['USA'], 'type': 'bar', 'name': 'USA'},
{'x': df['Year'], 'y': df['UK'], 'type': 'bar', 'name': 'UK'},
],
'layout': {
'title': 'Number of Immigrants by Country of Origin'
}
}
)
])
# Run the app
if __name__ == '__main__':
app.run_server()
Alright, our dashboard is ready.
Here is the output.
Dash is running on http://127.0.0.1:8050/
* Serving Flask app "__main__" (lazy loading)
* Environment: production
WARNING: This is a development server. Do not use it in a production deployment.
Use a production WSGI server instead.
* Debug mode: off
Once you run the code in your environment and visit http://127.0.0.1:8050/, you can see your dashboard.
Here is our dashboard.


As you can see, ChatGPT helped us a lot in developing a dashboard.
Machine Learning With ChatGPT
Machine learning is a field that includes building algorithms and models that can learn from data and make predictions based on it. These algorithms, models, and other techniques are designed to help developers improve their predictions and make decisions afterward.
There are several types of machine learning, including supervised, unsupervised, and reinforcement learning. We already mentioned that supervised learning, and reinforcement learning algorithms were applied when developing ChatGPT.
Machine learning has a wide range of applications like face recognition, natural language processing, fraud detection, predictive modeling, and more. It has become a vital tool for data scientists and is widely used in many industries.
Now, suppose you want to solve a regression problem either in your personal or professional project. Your manager (or you) wants to apply 6 different algorithms and evaluate them according to the evaluation metrics of regression like train error, test error, and R squared score and save them into a DataFrame.
Let’s explain this to ChatGPT and ask it to use a built-in data set to see whether the code actually works or not.
Question
Can you write me a machine learning script that will test 6 different regression algorithms in the diabetes data set (SVM, Multiple Linear regression, MLP, Ridge Regression, Random Forest, XGBoost Regressor), evaluate the results (MSE, train error, test error, R squared) and save the evaluation metrics into the DataFrame?
Answer
Certainly! Here is a script that demonstrates how to test 6 different regression algorithms in the diabetes dataset, evaluate the results, and save the evaluation metrics into a data frame:
import pandas as pd
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.metrics import r2_score
from sklearn.svm import SVR
from sklearn.linear_model import LinearRegression
from sklearn.neural_network import MLPRegressor
from sklearn.linear_model import Ridge
from sklearn.ensemble import RandomForestRegressor
from xgboost import XGBRegressor
# Load the diabetes dataset
diabetes = datasets.load_diabetes()
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(diabetes.data, diabetes.target, test_size=0.2, random_state=42)
# Initialize a dictionary to store the evaluation metrics for each model
evaluation_metrics = {
'Model': [],
'MSE': [],
'Train Error': [],
'Test Error': [],
'R Squared': []
}
# Define a list of the regression algorithms to test
regressors = [SVR(), LinearRegression(), MLPRegressor(), Ridge(), RandomForestRegressor(), XGBRegressor()]
# Iterate over the list of regressors
for regressor in regressors:
# Fit the regressor to the training data
regressor.fit(X_train, y_train)
# Make predictions on the training and testing sets
y_pred_train = regressor.predict(X_train)
y_pred_test = regressor.predict(X_test)
# Calculate the mean squared error and the train and test errors
mse = mean_squared_error(y_test, y_pred_test)
train_error = mean_squared_error(y_train, y_pred_train)
test_error = mean_squared_error(y_test, y_pred_test)
# Calculate the R squared score
r2 = r2_score(y_test, y_pred_test)
# Get the name of the regressor
model_name = regressor.__class__.__name__
# Add the evaluation metrics to the dictionary
evaluation_metrics['Model'].append(model_name)
evaluation_metrics['MSE'].append(mse)
evaluation_metrics['Train Error'].append(train_error)
evaluation_metrics['Test Error'].append(test_error)
evaluation_metrics['R Squared'].append(r2)
# Create a DataFrame from the dictionary
evaluation_df = pd.DataFrame(evaluation_metrics)
# Print the DataFrame
print(evaluation_df)
Let’s run the code in Jupyter notebook. Here is the output.

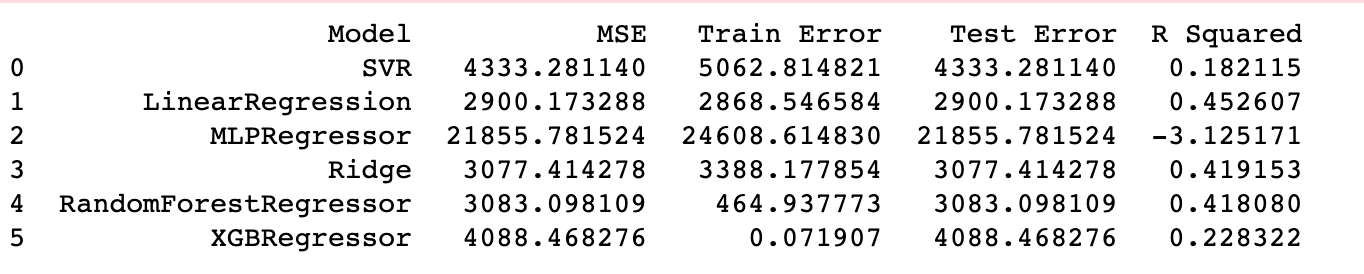
Wow! This can help data scientists save a lot of time when doing the A/B testing (finding the best option) in machine learning model selection.
Explains the code
ChatGPT is a chatbot trained using Open AI’s GPT-3 language model and intended to assist and answer specific questions or provide general guidance.
As we already mentioned, data science includes different disciplines that may include long scripts. Sometimes, understanding these lines may be difficult. When it comes to using ChatGPT to be a better data scientist, it is obvious that using it to understand codes better is something ChatGPT looks ideal for.
To crack complex code lines, let’s give ChatGPT a complex code that will essentially be used to apply different models.
Question
Can you add comments to this code:
def make_regression(x_train, y_train, x_test, y_test, model, model_name, verbose=True):
model.fit(x_train,y_train)
y_predict= model.predict(x_train)
train_error = mean_squared_error(y_train, y_predict, squared=False)
y_predict = model.predict(x_test)
test_error = mean_squared_error(y_test, y_predict, squared=False)
if verbose:
print("----Model name = {}-----".format(model_name))
print("Train error = "'{}'.format(train_error))
print("Test error = "'{}'.format(test_error))
trained_model = model
return trained_model, y_predict, train_error, test_error
Answer
Sure, here are some comments that can help explain the code:
def make_regression(x_train, y_train, x_test, y_test, model, model_name, verbose=True):
"""
Apply selected regression model to data and measure error
Parameters:
x_train (ndarray): Training data features
y_train (ndarray): Training data labels
x_test (ndarray): Test data features
y_test (ndarray): Test data labels
model (object): Regression model to be applied
model_name (str): Name of the model
verbose (bool): Flag to print results (default: True)
Returns:
trained_model (object): Trained regression model
y_predict (ndarray): Predicted labels for test data
train_error (float): Root mean squared error for training data
test_error (float): Root mean squared error for test data
"""
This line fits the model to the training data.
model.fit(x_train,y_train)
This line generates predictions for the training data.
train_error = mean_squared_error(y_train, y_predict, squared=False)
This line generates predictions for the test data.
y_predict=model.predict(x_test)
This line calculates the RMSE between the true test labels and the predicted labels.
test_error = mean_squared_error(y_test, y_predict, squared=False)
This block of code prints the model name and the RMSE for the training and test data if the verbose flag is True.
if verbose:
print("----Model name = {}-----".format(model_name))
print("Train error = "'{}'.format(train_error))
print("Test error = "'{}'.format(test_error))
This line assigns the trained model to the trained_model variable.
trained_model = model
This line returns the trained model, predicted labels for the test data, RMSE for the training data, and RMSE for the test data.
return trained_model, y_predict, train_error, test_errorIf you are curious about the code above, here’s the YouTube video which predicts delivery duration.
Bonus: Job Application

After developing skills in data science, you might be looking for the first job. Or you may want to change company and find a new position that will suit you and your skills better. If you already went through this process, you know what the cover letter is. But for all the junior data scientists out there, let me explain it. When looking for ideal candidates, employers want to know why you want to work with them, whether you have the skills and willingness to work with them or not.
ChatGPT also can help you with that! It can write a cover letter to help you apply for your desired job.
To feed its algorithm better, I will paste the job description. No need to give a job link to ChatGPT, but this job may interest you, so here it is: Data Scientist at Verizon.
Can ChatGPT write a cover letter for me?
Question
Can you write me a cover letter to apply for the job that has the following description:
[Here I added the description of the job, which is too long for this article. Just copy/paste it from indeed.com into ChatGPT]
Answer


Of course, don’t send it like this! You should edit a little bit. But if you tell ChatGPT more about your past experiences, the hiring manager's name, and your name, it will fill in the blanks, too.
You might be searching for a job on the freelancer website Upwork and you maybe want it to write a proposal for you instead of a cover letter. Now, let’s check if that works, too.
There’s a job on Upwork that looks for an AI expert. After asking the same thing I already did, ChatGPT realizes realizes what you are using for and automatically assigns the conversation accordingly.

This helps you to explain the details of your request.
At this stage, you can simply write the job title and copy/paste the description as follows.

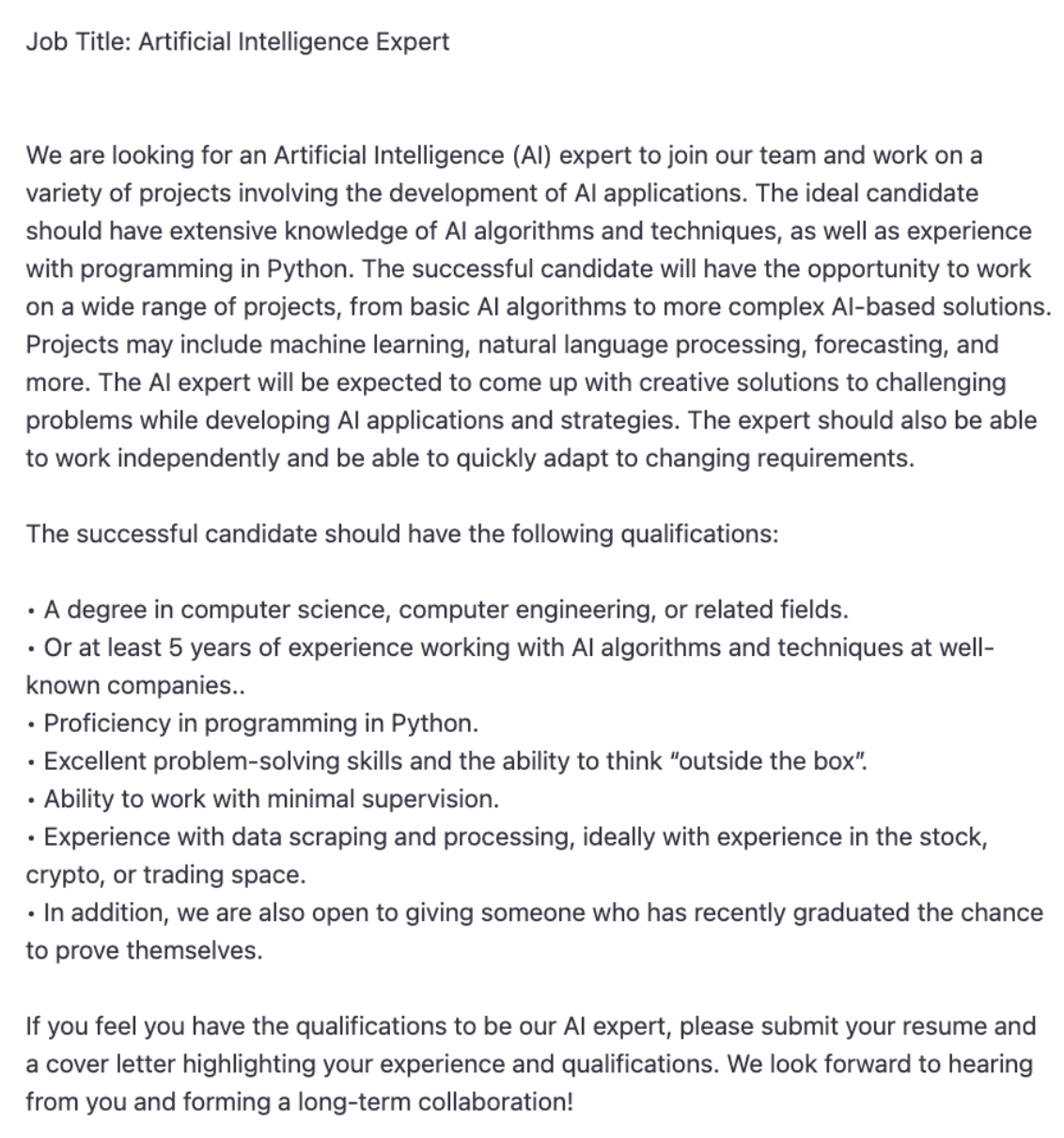
Here is the output of ChatGPT to this query.


Also, you maybe noticed that you could change the output by clicking on regenerate the response. Now let’s do it.


Here is the second version of this output. Also, you can edit your input by clicking the pencil shown on the right in the following image.


After clicking here, you can change the info you already gave to the ChatGPT to fill in the blanks
I add the following info at the beginning of the description.
“The Hiring Manager's name is John.
My name is Nate. My previous company is Apple. I have 5 years of experience in machine learning.
Job Title: Artificial Intelligence Expert”
After that, click on Save & Submit.

Now let’s see ChatGPT’s output.


What About the Cost of ChatGPT?
According to Tom Goldstein, an Associate Professor at Maryland, the cost is $100,000 per day. Yet, the calculation has been made according to the assumptions for the first 5 days and 10 queries per user. Due to changes in these variables, these costs can increase. However, OpenAI might make a special deal with Microsoft Azure, which is a factor that might reduce the costs.
For now, the cost still seems too big for a non-profit product. Actually, it looks like the CEO of Open AI has the same thoughts. On 5 December 2022, Sam Altman, the CEO of Open AI, said they “ will have to monetize it somehow at some point; the compute costs are eye-watering.”
So, unfortunately, it looks like there will be a limit on the query per day/month or price plans in the future.
Conclusion
ChatGPT works beyond imagination! Yet, there are many limitations as we see it. There are many ideas and claims that ChatGPT will replace developers or junior data scientists. This is a controversial statement because, as we can see from the examples, ChatGPT still needs a supervisor to work with because there might be errors. So if you use ChatGPT’s code, do not forget to test this code before running.
On the other hand, it looks like it helps developers to save time.
In this article, I analyzed ChatGPT, and its usage in debugging, writing code, explaining code, and even using it for job applications. These are the ways ChatGPT can make you a better data scientist.
If you like this article, do not forget to visit our platform. There are many other valuable articles, real-life data projects, and interview questions which also help you be a better data scientist.
See you there!
Share


