Finding Maximum Values in SQL: Aggregation Techniques

Categories:
 Written by:
Written by:Nathan Rosidi
MAX() in SQL is a straightforward aggregation method for finding maximum values. Learn here about its syntax and use cases through real interview examples.
Did you know there’s a simple way to find the highest value in a column without writing complex logic? That is what the MAX() function does in SQL. It’s a function that helps simplify one of the common operations in data aggregation. Used with some other SQL functions, it can power up your queries.
I’ll guide you through MAX() syntax and practical examples so you can find maximum values on your own.
What Is the MAX() Function in SQL?
MAX() is an SQL aggregate function used to find the highest value in a specified column. The function works on numerical (the highest number), string (the string that comes last alphabetically), and date & time data types (the latest date or time) data types.
SQL Syntax for Using MAX()
MAX in SQL follows a simple syntax you’re probably already familiar with from other aggregate functions.
SELECT MAX(column_name)
FROM table_name;
As a simple example, here’s the album_sales table.
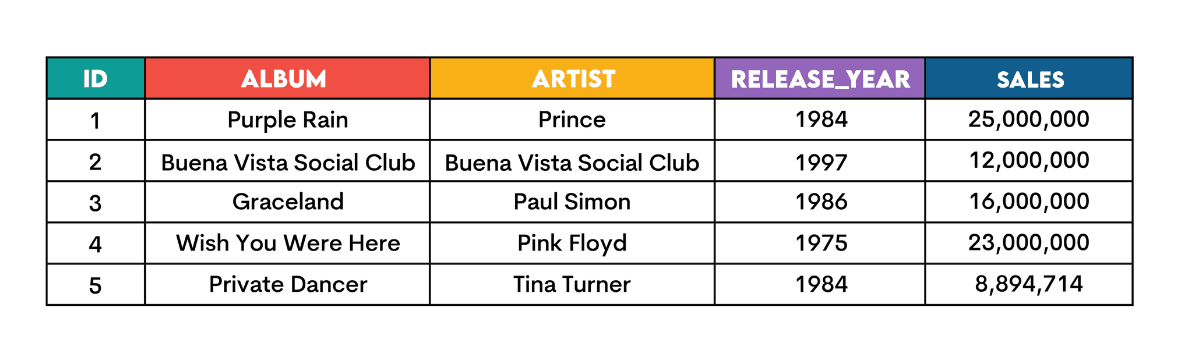
The simplest way of using MAX() is shown in the query below, which finds the highest sales.
SELECT MAX(sales) AS highest_sales
FROM album_sales;
The highest sales is 25,000,00

Now that you know the basic syntax of MAX(), let’s see its use cases.
Where to Use the MAX Function in SQL? Different Use Cases
There are several common ways to use MAX() in an SQL query.

1. Using MAX() in SELECT
This is the simplest application of MAX() that you already saw in the previous section. So, no need to go into details about it. It will suffice to say that by using MAX() in SELECT, I mean the aggregated MAX() column is the only column in SELECT, so there’s no GROUP BY.
However, I won’t miss the opportunity to show you an example from our platform.
Practical Example
Here’s a question from Salesforce and LinkedIn.
Unique Highest Salary
Last Updated: May 2019
Find the highest salary among salaries that appears only once.
Link to the question: https://platform.stratascratch.com/coding/9919-unique-highest-salary
The question gives you the table employee to find the highest salary among salaries that appear only once.
When using MAX() in SQL, it doesn’t matter where the data comes from. In the previous example, I referenced a table in FROM. In this example, the data will be from a subquery, which looks like shown below.
It’s a SELECT statement that lists all the salary amounts that appear only once. This is achieved by grouping by salary, then using HAVING and COUNT() to find only salaries where count is one.
SELECT salary
FROM employee
GROUP BY salary
HAVING COUNT(salary) = 1
Here’s the output.
| salary |
|---|
| 100000 |
| 700 |
| 200000 |
| 1100 |
| 2200 |
| 250000 |
| 150000 |
| 1500 |
To solve the question, you need to find the highest value returned by SELECT above. This is done by embedding the code in the main SELECT and using MAX() on the salary column.
SELECT MAX(salary) AS max_salary
FROM (SELECT salary
FROM employee
GROUP BY salary
HAVING COUNT(salary) = 1
) AS t;
The output is 250,000.
| max_salary |
|---|
| 250000 |
2. Using MAX() With GROUP BY
In this scenario, MAX() is still used directly in SELECT. However, it’s not the only column, but several others are added. By doing so, you label your maximum value, i.e., you can display info about it, not only show the sole highest value.
To be able to do so, you must list all the non-aggregate columns appearing in SELECT in GROUP BY.
Here’s the syntax.
SELECT column_1,
column_2,
…
MAX(column_n) AS column_alias
FROM table_name
GROUP BY column_1, column_2, …;
Practical Example
The interview question by Google and Amazon asks you to find the latest log in date for each video game player.
Latest Login Date
Last Updated: February 2022
For each video game player, find the latest date when they logged in.
Link to the question: https://platform.stratascratch.com/coding/2091-latest-login-date
You’re working with the table players_logins.
The query is really quite simple. Use MAX() to find the latest login dates. To do so by a player, add player_id in SELECT and group by the same column. To make the output more readable, you can ascendingly order by the player ID.
SELECT player_id,
MAX(login_date) AS latest_login_date
FROM players_logins
GROUP BY player_id
ORDER BY player_id ASC;
Here’s the output.
| player_id | max |
|---|---|
| 101 | 2021-12-19 |
| 103 | 2021-12-23 |
| 104 | 2022-01-14 |
| 105 | 2022-01-10 |
| 102 | 2022-01-15 |
| 106 | 2022-01-26 |
3. Using MAX() in WHERE
You can’t use MAX() in WHERE directly because WHERE filters data before aggregation, so no aggregate functions are allowed in that filtering clause.
But all is not lost because you can place MAX() in a subquery and use it as a filtering condition in WHERE. That way, you can filter records based on the maximum value in a column.
Here’s the syntax.
SELECT column_1
FROM table_name
WHERE column_2 =
(SELECT MAX(column_2)
FROM table_name);
Practical Example
This question by Forbes and Apple asks you to find the date when Apple’s opening stock price was at its highest.
Find the date with the highest opening stock price
Find the date when Apple's opening stock price reached its maximum
Link to the question: https://platform.stratascratch.com/coding/9613-find-the-date-with-the-highest-opening-stock-price
You’re provided with the table named aapl_historical_stock_price.
I’d first write a subquery that finds the highest opening stock price.
SELECT MAX(open)
FROM aapl_historical_stock_price
The next step is to place this subquery in the WHERE clause so it can search for a date where the opening price equals the highest historical opening price.
SELECT date
FROM aapl_historical_stock_price
WHERE open =
(SELECT MAX(open)
FROM aapl_historical_stock_price);
The output shows that the date with the highest opening Apple stock price is 2012-09-21.
| date |
|---|
| 2012-09-21 |
Note: Using MAX() in WHERE is also one of the examples of how you can use MAX() in a subquery. That way, you can use MAX() in a subquery in other clauses that allow subqueries, such as FROM, HAVING, or JOIN.
4. Using MAX() in HAVING
Unlike in WHERE, you can use MAX() directly in HAVING. This scenario allows you to filter data after the aggregation by comparing it to the maximum value.
Here’s the syntax.
SELECT column_1,
column_2,
…,
MAX(column_n) AS column_alias
FROM table_name
GROUP BY column_2, column_2, …
HAVING MAX(column_n) condition;
Practical Example
Here’s a question by Forbes that we’ll modify to suit our purpose.
Most Profitable Financial Company
Find the most profitable company from the financial sector. Output the result along with the continent.
Link to the question: https://platform.stratascratch.com/coding/9663-find-the-most-profitable-company-in-the-financial-sector-of-the-entire-world-along-with-its-continent
The question provides the table forbes_global_2010_2014.
We won’t look for the most profitable company in the financial sector. Instead, let’s list the sectors and their companies, but we’ll include only sectors where the highest market value of a company is above 200.
To solve this problem, first select the sector column, group by it, and use MAX() to find the highest market value.
Then, use the same MAX() construct in HAVING to include only the sectors whose highest market value is above 200.
Finally, sort the data by the market value descendingly to make the output more readable.
SELECT sector,
MAX(marketvalue) AS highest_market_value
FROM forbes_global_2010_2014
GROUP BY sector
HAVING MAX(marketvalue) > 200
ORDER BY highest_market_value DESC;
Here’s the output.
| sector | highest_market_value |
|---|---|
| Information Technology | 483.1 |
| Energy | 422.3 |
| Financials | 309.1 |
| Health Care | 277 |
| Industrials | 259.6 |
| Consumer Discretionary | 247.9 |
| Consumer Staples | 239.6 |
Combining MAX() With Other SQL Clauses
We’ve used MAX() only with one table in FROM so far. However, you can easily use MAX() with JOIN in SQL.
Combining MAX() With JOIN
When you combine MAX() with JOIN in SQL, it becomes possible to look for the highest value in all the joined tables, which significantly broadens the function’s use.
Just follow the JOIN syntax. Regarding MAX(), nothing changes.
SELECT t1.column_1,
MAX(t2.column_2) AS column_alias
FROM table_1 t1
JOIN table_2 t2
ON t1.column_1 = t2.column_1
GROUP BY t1.column_1;
Practical Example
Let’s solve this question by Noom.
Process a Refund
Last Updated: August 2022
Calculate and display the minimum, average and the maximum number of days it takes to process a refund for accounts opened from January 1, 2019. Group by billing cycle in months.
Note: The time frame for a refund to be fully processed is from settled_at until refunded_at.
Link to the question: https://platform.stratascratch.com/coding/2125-process-a-refund
You’ll need to work with three tables here. The first one is noom_signups.
The second table is noom_transactions.
The third table is noom_plans.
The task is to find the minimum, average, and maximum number of days it takes to process a refund by a billing cycle in months. This calculation must be performed only on accounts opened on January 1, 2019, or later.
Start by aggregating data. Refund processing starts with settled_at and ends with refunded_at. The difference between these two days is the number of days the refund processing took place. Apply the minimum, average, and maximum calculations to those differences and select the billing_cycle_in_months column.
Then, you join the table like you would in any other query. In this case, we join the tables noom_transactions and noom_signups on the signup ID, then add the noom_plans and join it with the previous table on the plan IDs.
After that, use WHERE to output only accounts opened on January 1, 2019, and later. Finally, group the output by the billing_cycle_in_months.
SELECT billing_cycle_in_months,
MIN(refunded_at - settled_at) AS min_days,
AVG(refunded_at - settled_at) AS avg_days,
MAX(refunded_at - settled_at) AS max_days
FROM noom_transactions t
JOIN noom_signups s ON t.signup_id = s.signup_id
JOIN noom_plans p ON s.plan_id = p.plan_id
WHERE started_at >= '2019-01-01'
GROUP BY billing_cycle_in_months;
Here’s the output.
| billing_cycle_in_months | min_days | avg_days | max_days |
|---|---|---|---|
| 6 | 6 | 9 | 14 |
| 12 | 6 | 9.5 | 13 |
| 1 | 4 | 10.44 | 21 |
Using MAX() with DISTINCT
If you want to use MAX() with DISTINCT in SQL, it’s done like this.
SELECT MAX(DISTINCT column_name)
FROM table_name;
The most important thing to remember is that DISTINCT goes inside the MAX() function.
Practical Example
Here’s the question by Amazon and General Assembly that I’ll rework.
Duplicate Training Lessons
Last Updated: August 2022
Display a list of users who took the same training lessons more than once on the same day. Assume that each u_name is unique. Output their usernames, training IDs, dates and the number of times they took the same lesson.
Link to the question: https://platform.stratascratch.com/coding/2130-duplicate-training-lessons
There are two tables. However, we’ll need only the second table, training_details, as the reworked requirement is to show the list of users and each user's latest training date.
You might attempt to solve it this way.
SELECT u_id,
MAX(training_date)
FROM training_details
GROUP BY u_id, training_id, training_date
ORDER BY u_id;
However, it won’t return the desired result, as most users took trainings on several dates. Because of that, the output shows each training date by the user.
| u_id | max |
|---|---|
| 1 | 2022-08-01 |
| 2 | 2022-08-08 |
| 2 | 2022-08-12 |
| 2 | 2022-08-17 |
| 3 | 2022-08-01 |
The solution is to use DISTINCT this way. This query retrieves the latest unique training date for each user.
SELECT u_id,
MAX(DISTINCT training_date)
FROM training_details
GROUP BY u_id
ORDER BY u_id;
Here are the first five rows of the output.
| u_id | max |
|---|---|
| 1 | 2022-08-01 |
| 2 | 2022-08-17 |
| 3 | 2022-08-14 |
| 4 | 2022-08-20 |
| 5 | 2022-08-23 |
Common Mistakes and Optimization Tips
There are not many common mistakes when using MAX in SQL, as it is a regular aggregation function with a straightforward syntax.
However, pay attention to these two situations.
Using MAX() With GROUP BY: As with all aggregate functions, don't forget to add GROUP BY if you’re selecting unaggregated columns along with MAX(). All the unaggregated columns from SELECT must also go in GROUP BY; otherwise, the query won’t run.
MAX() With NULLs: By default, SQL MAX() ignores NULL values. In most cases, this doesn’t create any issues. But if, for some reason, you want to consider NULLs, replace them with a meaningful default value, e.g., using COALESCE().
Regarding optimizing queries with MAX(), consider these two tips.
Index Columns: Index the columns used in MAX(), as this allows the database to find the maximum value faster, especially when data is large.
Avoid Unnecessary Joins: While using JOINs allows you to find maximums on a wider range of data, which is nice, don’t overuse them. Use JOINs only when necessary.
Conclusion
MAX() is one of the regular Postgres aggregate functions. You saw how easy it is to use it and find the maximum values with its straightforward syntax.
We discussed several scenarios of using MAX() in SQL, such as in SELECT, with GROUP BY, in WHERE, and HAVING. I tried to make this as practical as possible by showing you examples of actual interview questions. You’re in a good spot now. Just continue practicing using MAX() and other aggregate functions on StrataScratch.
Share