Facebook Data Engineer Interview Questions


Categories:
 Written by:
Written by:Nathan Rosidi
Interview questions for all the data engineers that wish to work at Meta/Facebook. We carefully selected the interview questions to reflect the data engineer job description as closest as possible.
If you want to work at Meta/Facebook as a data engineer, we’re sorry, but you’ll have to go through the interviews to get a job.
That’s a must for everybody and the only part of the selection process you can influence directly and quickly. You can’t intentionally differ from other candidates in education, experience, and knowledge in the short term; it is what it is. What you can do to be in a better position than other candidates is to be prepared for the questions appearing in the job interview. And you’ll need to know the job interview questions, right?
We don’t have a crystal ball to tell you which questions you’ll get at your interview. What we do have are the job interview questions from the previous Facebook/Meta interviews. They cover certain topics of interest for data engineers, so going through them is the safest bet to be prepared when you face the interviewer.
We'll show you the selected list of questions based on the specific tasks performed by data engineers.
Hey, What Are You Doing?
The prerequisite to being good at something is knowing what you should do. As a data engineer, you are responsible for extracting, transforming, and loading (ETL) data. This includes working with data but also data infrastructure to get the data to other users. Your concern is data quality and availability, which is ensured through developing, maintaining, and optimizing data infrastructure.
In the words of Meta/Facebook’s data engineer job description, you will “design, build and launch extremely efficient and reliable data pipelines”, “build data expertise and own data quality”, and “use your data and analytics experience to ‘see what’s missing’”.
One of the main requirements for data engineers is the SQL experience because you’ll be most of the time working with databases. With SQL being a programming language developed exactly for that purpose, it’s a no-brainer to test your SQL knowledge in the job interview.
SQL Coding Interview Questions

SQL interview questions are usually practical, meaning they test your SQL knowledge through writing a code that solves actual business problems in the data engineering domain. This generally means the SQL concepts a data engineer must know are not different from most other data science jobs. In fact, these questions are also often asked in data science interviews, too. The thing is, the scenarios in the questions we’re going to show you are much closer to the day-to-day job of a data engineer and the way they use SQL daily.
Framework For Solving the Data Engineer Coding Questions
Keep in mind that structuring your code is as important as writing the correct code. When it comes to writing a code, don��’t jump to it immediately. After reading a question, try to implement a framework for solving it.
Why is this important? Using a framework helps you break down your answer into several logical steps, which has significant benefits.
- It makes sure you understand the question and the required output
- It helps in avoiding unnecessarily complicated solutions
- It helps in defining assumptions
- It saves time
The framework we like to use consists of four steps:
- Exploring the dataset
- Identifying columns needed for solving the question
- Writing out the coding logic
- Writing a code
We’ll explain each step and show you how to implement them on several examples.
1. Exploring the Dataset
Every question will give you tables to work with. Take your time to go through every table’s column, and understand the data types and how data is structured.
Why is that important? Depending on the data types, you’ll choose the adequate function for your solution. Also, it will tell you if you need to convert the data type, for example, integer into decimal. Are dates entered as text or as a timestamp?
Apart from data types, the data structure is also important. In short, you need to understand what the tables actually represent. That way, you can determine if there are or can be duplicate values or NULL values, which then influence your code further. For example, choosing the correct JOIN or whether you need to use the DISTINCT clause.
When possible, preview the available data and look at the concrete values the tables contain.
2. Identifying Columns
Usually, not every column available is required to solve the question. Identify the columns you will need to solve the question before you start writing a code, and disregard the rest. That way, you reduce the amount of data you’re working with, and when the time comes, you can focus on coding. This already helps lay out the structure of the code in your mind.
But don’t let it stay there!
3. Writing Out the Code Logic
Yes, this literally means writing on a piece of paper or a whiteboard. Break down the code into steps. If you do that, it’ll be easier for you to write a code, check it, and correct it before you finish it. Also, you help the interviewer. In turn, they can help you because they’ll, too, have a clear idea of what you’re doing and can lead you towards the right solution if you get stuck.
4. Coding
After following the previous steps, writing a code will almost be a technicality. You can focus on syntax and write a code that will work and return the required output, which is the point of the interview questions.
Facebook Data Engineer Interview Question #1: Find the Maximum Step Reached for Every Feature
Find the maximum step reached for every feature. Output the feature id along with its maximum step.
Link to the question: https://platform.stratascratch.com/coding/9774-find-the-maximum-step-reached-for-every-feature
Solution Framework
1. Exploring the Dataset
This question asks you to work with only one table:
You can see that every feature can have multiple users and vice versa. Also, the steps reached are unique for the feature_id and user_id combination.
The last column shows the year, month, day, hour, minute, and second of the step that was reached.
2. Identifying Columns
There are four columns in the table:
- feature_id
- user_id
- step_reached
- timestamp
The question doesn’t require showing the date or time in any form. Therefore, you can ignore the column timestamp.
Also, you don’t need the column user_id, so you can safely ignore it, too.
The only two columns you’ll use in the code are
- feature_id
- Step_reached
3. Writing Out the Code Logic
- Select the feature – to show the highest step reached by feature and not overall
- Find the maximum step reached – MAX()
- Use table – FROM clause
- Group by the feature
4. Coding
1. Select the feature.
SELECT feature_id,2. Calculate the maximum step reached using the aggregate function MAX().
SELECT feature_id,
MAX(step_reached) AS max_step_reached
3. Both columns are from the only table you have at your disposal, which needs to be referenced in the FROM clause.
SELECT feature_id,
MAX(step_reached) AS max_step_reached
FROM facebook_product_features_realizations
4. Finally, group the data by feature to get the complete solution.
SELECT feature_id,
MAX(step_reached) AS max_step_reached
FROM facebook_product_features_realizations
GROUP BY feature_id;
Output
Run the code and compare it with the output below; they should be the same.
Facebook Data Engineer Interview Question #2: SMS Confirmations From Users
Last Updated: November 2020
Meta/Facebook sends SMS texts when users attempt to 2FA (2-factor authenticate) into the platform to log in. In order to successfully 2FA they must confirm they received the SMS text message. Confirmation texts are only valid on the date they were sent.
Unfortunately, there was an ETL problem with the database where friend requests and invalid confirmation records were inserted into the logs, which are stored in the 'fb_sms_sends' table. These message types should not be in the table.
Fortunately, the 'fb_confirmers' table contains valid confirmation records so you can use this table to identify SMS text messages that were confirmed by the user.
Calculate the percentage of confirmed SMS texts for August 4, 2020. Be aware that there are multiple message types, the ones you're interested in are messages with type equal to 'message'.
Link to the question: https://platform.stratascratch.com/coding/10291-sms-confirmations-from-users
Solution Framework
1. Exploring the Dataset
Here, you’ll work with two tables: fb_sms_sends and fb_confirmers
The column ds shows the year, month, and day of the sent message. It’s logical to conclude that the dates aren’t unique, which the preview confirms.
Countries are not shown in full but as abbreviations. While each abbreviation should mean only one country, the countries can appear multiple times.
The carrier is the telecommunication company through which the message is sent. They, too, appear several times.
Looking at the full data, you can see that the phone numbers are unique. This means there are no multiple messages sent to the same phone number.
The type column contains data about the message type and, erroneously, the type of notification, too.
Table: fb_confirmers
It’s safe to assume that the dates in this table are not unique, while the phone number is.
You can see there are no primary and foreign keys you can use to join these tables if needed.
2. Identifying Columns
There are five columns in the table fb_sms_sends.
- ds
- country
- carrier
- phone_number
- type
You’re not interested in country and carrier. The question doesn’t ask you to do anything with them, so you can ignore these columns.
The phone number is needed because every number equals a sent message. Also, you need SMS texts only for a specific date and only a certain type of message.
Therefore, you’ll use three columns from the table fb_sms_sends.
- ds
- phone_number
- type
When it comes to the table fb_confirmers, it contains the correct records of the confirmed messages. There are two columns, and you’ll need them both.
- date
- phone_number
3. Writing Out the Code Logic
- LEFT JOIN tables ON ds = date AND phone_number = phone_number – to get the message sent to a particular phone number on a particular date, in case there are multiple messages sent to one phone number
- COUNT() the phone numbers from the table fb_confirmers – the number of confirmed messages
- Convert to float to get the precise value
- Divide with COUNT() of the phone number from the table fb_sms_sends – the number of all the sent messages
- Multiply by 100 to get the percentage
- WHERE – '08-04-2020' AND 'message'
4. Coding
Again, use the above layout to write the solution.
1. First, join the tables.
FROM fb_sms_sends a
LEFT JOIN fb_confirmers b ON a.ds = b.date
AND a.phone_number = b.phone_number
The tables are given aliases to write the rest of the code easier.
2. Use the COUNT() function to get the confirmed messages
SELECT COUNT(b.phone_number)
FROM fb_sms_sends a
LEFT JOIN fb_confirmers b ON a.ds = b.date
AND a.phone_number = b.phone_number
3. Then, convert the result to float. In PostgreSQL, you can use a double colon (::) for converting data types.
SELECT COUNT(b.phone_number)::float
FROM fb_sms_sends a
LEFT JOIN fb_confirmers b ON a.ds = b.date
AND a.phone_number = b.phone_number
4. Next, divide the first count by the number of sent messages.
SELECT COUNT(b.phone_number)::float / COUNT(a.phone_number)
FROM fb_sms_sends a
LEFT JOIN fb_confirmers b ON a.ds = b.date
AND a.phone_number = b.phone_number
5. You need a percentage, so multiply the division result by 100. The column that will show the percentage of confirmed messages is named perc.
SELECT COUNT(b.phone_number)::float / COUNT(a.phone_number) * 100 AS perc
FROM fb_sms_sends a
LEFT JOIN fb_confirmers b ON a.ds = b.date
AND a.phone_number = b.phone_number
6. The final step is to filter data using the WHERE clause, and you get the final solution.
SELECT COUNT(b.phone_number)::float / COUNT(a.phone_number) * 100 AS perc
FROM fb_sms_sends a
LEFT JOIN fb_confirmers b ON a.ds = b.date
AND a.phone_number = b.phone_number
WHERE a.ds = '08-04-2020'
AND a.type = 'message';
Output
Here’s what the code returns.
Facebook Data Engineer Interview Question #3: Users By Average Session Time
Last Updated: July 2021
Calculate each user's average session time, where a session is defined as the time difference between a page_load and a page_exit. Assume each user has only one session per day. If there are multiple page_load or page_exit events on the same day, use only the latest page_load and the earliest page_exit, ensuring the page_load occurs before the page_exit. Output the user_id and their average session time.
Link to the question: https://platform.stratascratch.com/coding/10352-users-by-avg-session-time
Solution Framework
1. Exploring the Dataset
There’s only one table: facebook_web_log
This means the user can appear multiple times, and there can also be multiple instances of the same action. Of course, this can’t happen simultaneously, so every log will have a distinct timestamp.
2. Identifying Columns
The table has three columns, and you will need all three of them.
- user_id
- timestamp
- action
The output will surely have the column user_id because the question asks you to output it. The column timestamp will be used to calculate the average session time. Also, use the column action to determine a session, defined as the difference between a page_load and page_exit.
3. Writing Out the Code Logic
1. Write a CTE – to get the session duration per user and date
- Self-join table using JOIN where user_id = user_id – use aliases to differentiate between the table for finding page loads and the table for finding logouts
- Select user_id
- Select timestamp and convert it to date so you can distinguish between sessions on different dates
- MIN() – Find the first log out and convert to timestamp
- MAX() – Find the latest load of the page, convert it to timestamp and subtract it from the previous calculation
- WHERE – find only 'page_load' AND 'page_exit' AND data where the log out is after the page load
- GROUP BY user and timestamp
- Turn the SELECT statement into a CTE – WITH clause
2. Write a query referencing CTE – to show the average session duration by userFROM – reference the CTE
- Select user_id
- Calculate the average session duration – AVG()
- Group data by user
4. Coding
1) The first step is to write a CTE that will output the session duration by user and date.
1. Select and self-join the table, and give the aliases.
SELECT
FROM facebook_web_log t1
JOIN facebook_web_log t2 ON t1.user_id = t2.user_id
In the self-join, the table facebook_web_log is given aliases twice so we can distinguish between them as any other two tables. One table will be for page loads, and the other table will be for logouts.
2. Now select the user_id column.
SELECT t1.user_id
FROM facebook_web_log t1
JOIN facebook_web_log t2 ON t1.user_id = t2.user_id
3. Select the timestamp and convert it to date.
SELECT t1.user_id,
t1.timestamp::date AS date
FROM facebook_web_log t1
JOIN facebook_web_log t2 ON t1.user_id = t2.user_id 4. Then calculate the earliest log out and convert it from datetime to timestamp.
SELECT t1.user_id,
t1.timestamp::date AS date,
MIN(t2.timestamp::TIMESTAMP)
FROM facebook_web_log t1
JOIN facebook_web_log t2 ON t1.user_id = t2.user_id
5. Do the same with the latest load of the page and subtract the two values.
SELECT t1.user_id,
t1.timestamp::date AS date,
MIN(t2.timestamp::TIMESTAMP) - MAX(t1.timestamp::TIMESTAMP) AS session_duration
FROM facebook_web_log t1
JOIN facebook_web_log t2 ON t1.user_id = t2.user_id
6. After that, you need to filter data using the WHERE clause.
SELECT t1.user_id,
t1.timestamp::date AS date,
MIN(t2.timestamp::TIMESTAMP) - MAX(t1.timestamp::TIMESTAMP) AS session_duration
FROM facebook_web_log t1
JOIN facebook_web_log t2 ON t1.user_id = t2.user_id
WHERE t1.action = 'page_load'
AND t2.action = 'page_exit'
AND t2.timestamp > t1.timestamp
7. Group by user and date.
SELECT t1.user_id,
t1.timestamp::date AS date,
MIN(t2.timestamp::TIMESTAMP) - MAX(t1.timestamp::TIMESTAMP) AS session_duration
FROM facebook_web_log t1
JOIN facebook_web_log t2 ON t1.user_id = t2.user_id
WHERE t1.action = 'page_load'
AND t2.action = 'page_exit'
AND t2.timestamp > t1.timestamp
GROUP BY 1,2
8. Use the WITH clause to make this SELECT statement a CTE.
WITH all_user_sessions AS
(SELECT t1.user_id,
t1.timestamp::date AS date,
MIN(t2.timestamp::TIMESTAMP) - MAX(t1.timestamp::TIMESTAMP) AS session_duration
FROM facebook_web_log t1
JOIN facebook_web_log t2 ON t1.user_id = t2.user_id
WHERE t1.action = 'page_load'
AND t2.action = 'page_exit'
AND t2.timestamp > t1.timestamp
GROUP BY 1,2)
2) Now comes the SELECT statement that uses data from the CTE.
1. Reference the CTE in the FROM clause.
SELECT
FROM all_user_sessions
2. Select the users.
SELECT user_id
FROM all_user_sessions
3. After that, use the AVG() function.
SELECT user_id,
AVG(session_duration)
FROM all_user_sessions
4. Finally, group data by user.
SELECT user_id,
AVG(session_duration)
FROM all_user_sessions
GROUP BY user_id
When you get all the steps together, you get the solution.
WITH all_user_sessions AS
(SELECT t1.user_id,
t1.timestamp::date AS date,
MIN(t2.timestamp::TIMESTAMP) - MAX(t1.timestamp::TIMESTAMP) AS session_duration
FROM facebook_web_log t1
JOIN facebook_web_log t2 ON t1.user_id = t2.user_id
WHERE t1.action = 'page_load'
AND t2.action = 'page_exit'
AND t2.timestamp > t1.timestamp
GROUP BY 1,
2)
SELECT user_id,
AVG(session_duration)
FROM all_user_sessions
GROUP BY user_id;
Output
The code outputs two users and their average session duration.
Facebook Data Engineer Interview Question #4: Acceptance Rate By Date
Last Updated: November 2020
Calculate the friend acceptance rate for each date when friend requests were sent. A request is sent if action = sent and accepted if action = accepted. If a request is not accepted, there is no record of it being accepted in the table. The output will only include dates where requests were sent and at least one of them was accepted, as the acceptance rate can only be calculated for those dates. Show the results ordered from the earliest to the latest date.
Link to the question: https://platform.stratascratch.com/coding/10285-acceptance-rate-by-date
Now, try to apply the framework to write a solution in the widget. See if it gives you the desired output.
Solution Approach
- Use one CTE to get the data for the sent friend requests.
- The second CTE will fetch data for all the accepted friend requests.
- The main SELECT statement will use the CTEs’ results. Join the CTEs using the LEFT JOIN where the senders' IDs are the same, and the receivers’ IDs are the same.
- Use two COUNT() functions to get the number of users who received and sent the friend request.
- Divide these two numbers and convert them to a decimal number to get the acceptance rate.
- To get the rate by date, you need the date column in the SELECT statement.
- Group by date.
Output
Facebook Data Engineer Interview Question #5: Spam Posts
Last Updated: June 2020
Calculate the percentage of spam posts in all viewed posts by day. A post is considered a spam if a string "spam" is inside keywords of the post. Note that the facebook_posts table stores all posts posted by users. The facebook_post_views table is an action table denoting if a user has viewed a post.
Link to the question: https://platform.stratascratch.com/coding/10134-spam-posts
Solution Approach
- Select the post_date in the FROM clause of the main query.
- In the same subquery, use the CASE statement in the SUM() function to get the number of viewed posts.
- Use JOIN within a subquery to join the tables provided on a post_id column.
- Group by post_date.
- LEFT JOIN the first subquery with the second one on the post_date column.
- Select the post_date in the second subquery.
- In the same subquery, use the CASE statement in the SUM() function to get the number of viewed spam posts.
- Join the tables within the subquery using JOIN on the post_id column.
- Filter data in the subquery using the WHERE and ILIKE clause to get only spam posts.
- Group data in the second subquery by post_date
Try using the widget to write a code following these instructions.
Output
Did you get the below table as an output?
Facebook Data Engineer Interview Question #6: Highest Energy Consumption
Last Updated: March 2020
Find the date with the highest total energy consumption from the Meta/Facebook data centers. Output the date along with the total energy consumption across all data centers.
Link to the question: https://platform.stratascratch.com/coding/10064-highest-energy-consumption
Solution Approach
- Write the first CTE that selects all data from all three available tables and combines their results using the UNION ALL set operator.
- Use the second CTE to calculate the total energy consumption by date: select the date and sum the consumption using the data from the first CTE
- Group by date in the second CTE.
- Order the second CTE’s output by date in ascending order.
- The third CTE is for finding the highest energy consumption. Use the MAX() function on the data from the second CTE for that.
- Use JOIN in the main SELECT statement to use data from the second and third CTE.
- Show the total energy by date.
Now you need to turn this into a code.
Output
What did you get as an output?
Facebook Data Engineer Interview Question #7: Successfully Sent Messages
Last Updated: June 2018
Find the ratio of successfully received messages to sent messages.
Link to the question: https://platform.stratascratch.com/coding/9777-successfully-sent-messages
Solution Approach
- Write the SELECT statement that will contain only two subqueries – one for getting the number of received messages, the other for the number of sent messages.
- In the first subquery, use the COUNT() function to find the number of the received messages.
- Use CAST() to convert the COUNT() result to a decimal number.
- Reference the table facebook_messages_received in the FROM clause.
- Use the COUNT() function in the second subquery to find the number of the sent messages.
- Reference the table facebook_messages_sent in the FROM clause.
- Divide the result of the two subqueries to find the ratio.
Try it yourself in the widget!
Output
You should get this output.
Facebook Data Engineer Interview Question #8: Recommendation System
Last Updated: December 2021
You are given the list of Facebook friends and the list of Facebook pages that users follow. Your task is to create a new recommendation system for Facebook. For each Facebook user, find pages that this user doesn't follow but at least one of their friends does. Output the user ID and the ID of the page that should be recommended to this user.
Link to the question: https://platform.stratascratch.com/coding/2081-recommendation-system
Solution Approach
- In the SELECT statement, JOIN the two tables where the friend ID equals the user ID.
- Select only the unique user ID and page ID combinations.
- Use the WHERE and the NOT EXISTS clauses to find the pages the user doesn’t follow, but one of their friends does.
- Write a subquery to set up the filtering condition. In the subquery, select all columns from the table users_pages.
- Then, use the WHERE clause in the subquery, too. The condition should include only data where the user_id is the same in both tables, and the page_id is also the same in both tables.
Write your solution here and compare the result with the official output below.
Output
Facebook Data Engineer Interview Question #9: Cum Sum Energy Consumption
Last Updated: April 2020
Calculate the running total (i.e., cumulative sum) energy consumption of the Meta/Facebook data centers in all 3 continents by the date. Output the date, running total energy consumption, and running total percentage rounded to the nearest whole number.
Link to the question: https://platform.stratascratch.com/coding/10084-cum-sum-energy-consumption
Solution Approach
This question’s solution is partially the same as the question #6’s. The two CTEs, one that merges all the tables output with UNION ALL and the other one for calculating the total energy by date, are exactly the same.
So are the first four steps in writing the code.
- Write the first CTE that selects all data from all three available tables and combines their results using the UNION ALL set operator.
- Use the second CTE to calculate the total energy consumption by date: select the date and sum the consumption using the data from the first CTE
- Group by date in the second CTE.
- Order the second CTE’s output by date in ascending order.
- In the main query, select the date from the second query.
- Use the SUM() window function to calculate the cumulative total energy by ordering partition by date in ascending order.
- The third column in the SELECT statement multiplies the cumulative total energy by 100.
- Then the result is divided by the subquery, which uses the SUM function and data from the second CTE to calculate the total energy consumption.
- Round the division result to the nearest whole number.
Use the widget for writing a code.
Output
Here’s what you should get.
Facebook Data Engineer Interview Question #10: Find the Number of Processed and Not-Processed Complaints of Each Type
Find the number of processed and non-processed complaints of each type. Replace NULL values with 0s. Output the complaint type along with the number of processed and not-processed complaints.
Link to the question: https://platform.stratascratch.com/coding/9790-find-the-number-of-processed-and-not-processed-complaints-of-each-type
Solution Approach
- Select the column type from the subquery.
- This subquery selects the columns type and processed from the table.
- Use the COUN() function to find the number of complaints.
- In the main query, use the CASE statement in the MAX() function to find the number of processed complaints – it takes the values from the column n_entries when the complaint is processed and replaces NULL values with zeros
- Use the CASE statement and the MAX() function again. This time to find the number of the non-processed complaints by allocating values from the column n_entries when the complaint is not processed and showing zeros instead of NULLs.
- Group the result by type.
Output
Can you get the output below?
System Design
Data engineers have to be familiar with system design. Firstly, because they build data pipelines, which are systems within data systems. Also, they will closely work with data architects, modelers, and administrators.
To get a feeling of what the system design means for data engineers at Meta/Facebook, consider these questions.
Facebook Data Engineer Interview Question #11: Subpopulations


Link to the question: https://platform.stratascratch.com/technical/2004-subpopulations
Facebook Data Engineer Interview Question #12: Comparing Performance of Engines


Link to the question: https://platform.stratascratch.com/technical/2006-comparing-performance-of-engines
Facebook Data Engineer Interview Question #13: Are We Friends?

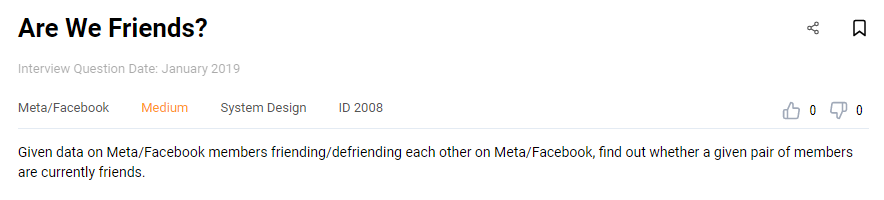
Link to the question: https://platform.stratascratch.com/technical/2008-are-we-friends
Facebook Data Engineer Interview Question #14: GROUP or ORDER BY

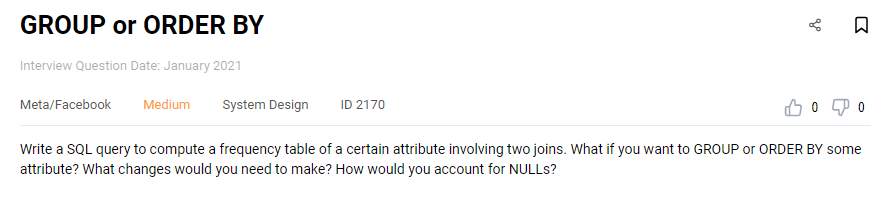
Link to the question: https://platform.stratascratch.com/technical/2170-group-or-order-by
Facebook Data Engineer Interview Question #15: Friends You May Know

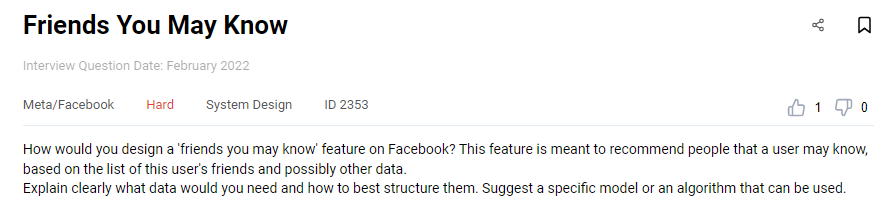
Link to the question: https://platform.stratascratch.com/technical/2353-friends-you-may-know
Technical Interview Questions
These types of questions also test the SQL knowledge but in a theoretical sense. For example, they could ask you to explain the join types, the difference between the WHERE and HAVING clauses, or between the subqueries and CTEs. You’re not asked to write a code, but you still need to know a particular SQL concept.
The Meta/Facebook example from our platform is the one below.
Facebook Data Engineer Interview Question #16: Views and Storage Space


The short (and correct!) answer to this question would be: No.
However, the interviewer will probably ask you to elaborate on that. Expanding on your answer shouldn't be difficult if you know what the views in SQL are, how they are called, and where you can find its result.
Also, check out our post "Data Engineer Interview Questions" to find more questions from other top companies like Google, Amazon, Shopify, etc.
Summary
We hope you got a flavor of what you can expect from the Meta/Facebook interview questions for a data engineering position.
It’s vital that you carefully read the job description before deciding on which interview questions you should focus on. Meta/Facebook is a big company. While the general tasks are the same for most data engineers, they could also significantly differ depending on which department you’ll be working in. For example, the data engineering job can be more product development, marketing, or investment-oriented. Always tailor your preparation to a specific job ad.
But a general guideline will always work. Go through the SQL Coding, System Design, and Technical interview questions, and you can be sure you’re on the right track to practice all the topics necessary for data engineers at Meta/Facebook.
Share


