Easy Guide to Python Hashmaps


Categories:
 Written by:
Written by:Nathan Rosidi
What are Python hashmaps, what are the basic operations and advanced techniques, and how to use them in practice? We answer all that and more in this article.
Hashmaps are a fundamental tool for storing and accessing data in a highly-efficient way.
In this guide, I’ll walk you through the essentials of Python hashmaps, from basic operations to advanced techniques and best practices.
There will also be plenty of practical examples and solving a couple of our algorithm interview questions.
What is a Python Hashmap?
Python hashmaps, often called Python dictionaries, are data structures that store key-value pairs.
The keys act like labels to retrieve values quickly without needing to search through the entire dataset.
Python dictionaries use hash functions internally to map keys to specific memory locations, enabling fast lookups. This makes them highly efficient for tasks like counting, organizing, or creating mappings between datasets. Python hashmaps shine because they allow various types of keys—strings, numbers, or even tuples—as long as the keys are immutable.
Python Hashmaps: Dictionary Basics
In this section, I’ll cover two basic areas of Python hashmap knowledge.


How Python Dictionaries Work as Hashmaps
Python dictionaries rely on hashing—a process where a unique, fixed-size identifier (a hash) is generated for keys. Behind the scenes, Python uses an optimized hash table algorithm, ensuring constant-time complexity for most operations.
Here’s an example of how hashing is done, where the input value is x, and the number of hash keys is n.

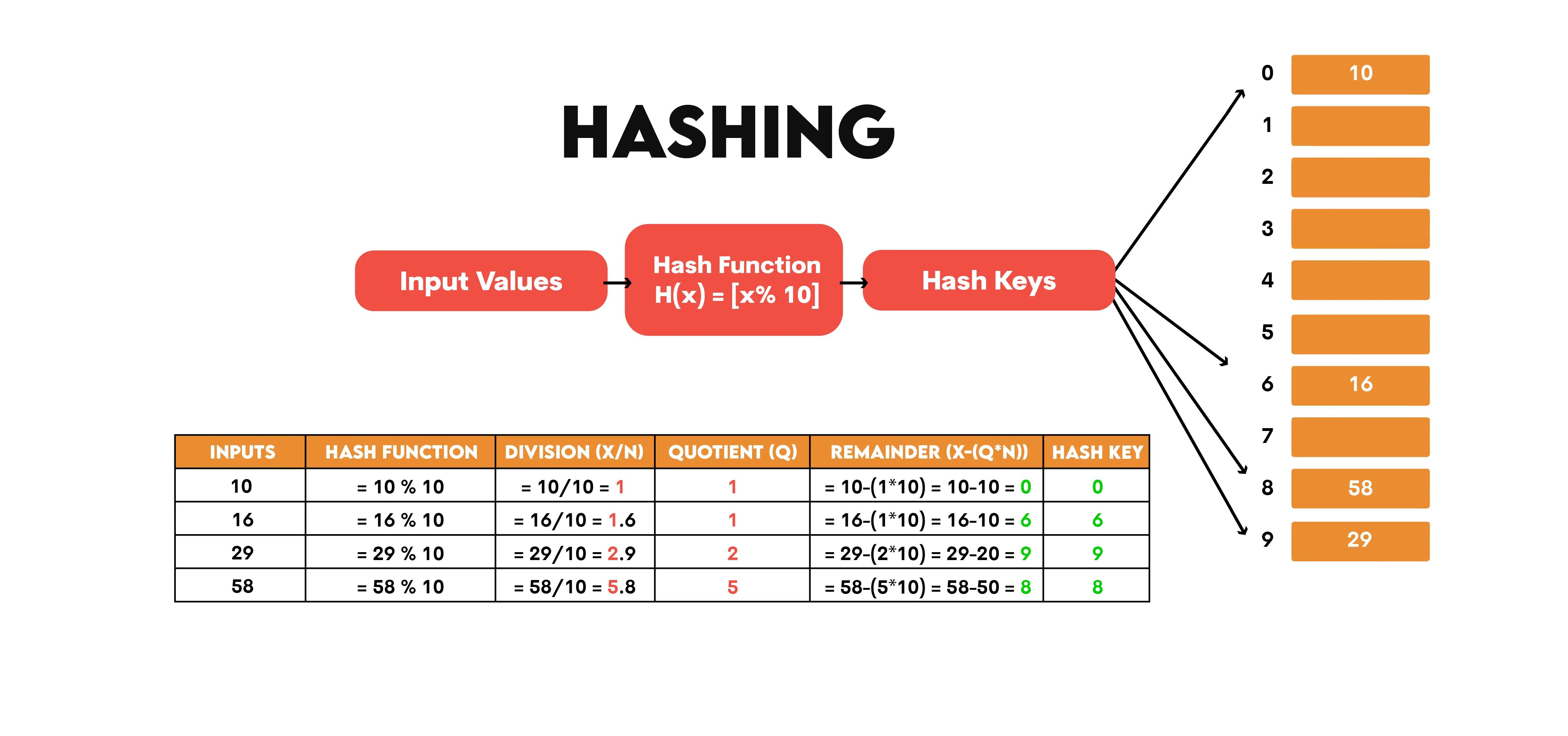
Basic Operations
The basic operations in Python dictionaries include the following.


1. Creating a Dictionary
A dictionary in Python is created using curly braces ({}).
# Create a dictionary
dictionary = {'name': 'William', 'age': 28, 'city': 'Cairo'}
print(dictionary)
Another option is to use the dict() constructor.
# Create a dictionary using dict()
dictionary = dict(name='William', age=28, city='Cairo')
print(dictionary)
Both codes return the same output.

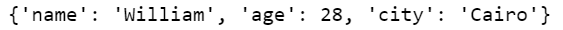
2. Accessing Dictionary Elements
To retrieve a value from a dictionary, use the dictionary[key] format.
dictionary = {'name': 'William', 'age': 28, 'city': 'Cairo'}
# Access elements
print("Name:", dictionary['name'])
The code outputs all the values from the key ‘name’ and labels it as ‘Name:’.

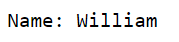
3. Add or Update Elements
One of the basic dictionary operations is assigning a value to a key to add a new key-value pair or update an existing one.
dictionary = {'name': 'William', 'age': 28, 'city': 'Cairo'}
# Add or update elements
dictionary['age'] = 31 # Update existing key
dictionary['profession'] = 'Engineer' # Add new key-value pair
print("Updated Dictionary:", dictionary)
The above code updates the ‘age’ key with the value 31. It also adds a ‘profession’ key with the value ‘Engineer’. Here’s the output.


4. Remove Elements
You can use methods like del or pop() to delete entries.
With del, you remove a key-value pair from the dictionary permanently. This is the syntax.
del dictionary[key]
Let’s remove the city from the example dictionary.
dictionary = {'name': 'William', 'age': 28, 'city': 'Cairo'}
# Remove elements
del dictionary['city'] # Delete a key-value pair
print("After Deletion:", dictionary)
Here’s what the dictionary looks like after deletion.

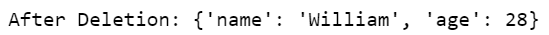
If you use pop() instead, it will delete a key-value pair from the dictionary and return the associated value.
Here’s the syntax.
value = dictionary.pop(key, [default])
Applied to our example when removing ‘city’ from the dictionary.
dictionary = {'name': 'William', 'age': 28, 'city': 'Cairo'}
# Use pop method to remove and return a value
city = dictionary.pop('city')
print("Popped City:", city)
print("Final Dictionary:", dictionary)
The output shows the values of the city key we removed and the final dictionary.


Advantages of Using Python Hashmaps
There are several important advantages that using hashmaps in Python brings.


1. Fast Lookups: Hashing ensures that hashmaps have an average time complexity of O(1), which you’ll particularly admire when working with large datasets.
2. Flexibility: Hashmaps' flexibility means they allow diverse types of keys, such as strings and integers, as long as they are immutable. This flexibility increases hashmaps’ range of use cases.
3. Dynamic Size: Hashmaps don’t require manual adjustments when they need to grow or shrink, making them convenient for dynamic datasets.
4. Rich Functionality: Python dictionaries have built-in methods for common tasks (key lookups, value retrievals, merging datasets) and advanced features, such as default dictionaries and comprehensions.
5. Easy-to-Read Syntax: Python dictionaries have very clear syntax, making them easily readable and intuitive, even for beginners.
Common Python Hashmap Operations
I’ll show you three common operations in Python dictionaries.

I’ll enhance each of these operations explanations by showing you an algorithm question example from StrataScratch.
1. Checking the Existence of a Key
Before you access a dictionary value, checking if the key exists is often useful to avoid errors.
To do so, use the in or not in keys.
Here’s how you can iterate through keys in a dictionary we’ve been using so far.
# Iterate through keys in a dictionary
dictionary = {'name': 'William', 'age': 28, 'city': 'Cairo'}
for key in dictionary:
print(f"Key: {key}")
This code outputs all the keys existing in the dictionary.


Let’s now look at the interview question to put this dictionary operation in a real-world context.
Example
The question by Stitch Fix asks you to write a function to sample a certain number of elements from a multimodal distribution. As an input, N will be the number of samples, K is the keys (list of possible elements), and W will be the list of weights for each key.
Write a function to sample a certain number of elements from a multimodal distribution.
You can take as input N - number of samples, K - keys (list of possible elements), and W - list of weights for each key. Call random.seed(0) before sampling so your function’s output matches exactly with the test cases
Link to the question: https://platform.stratascratch.com/algorithms/10430-sampling-from-multimodal-distribution
Here are constraints:
- n: an integer representing the number of samples to be generated
- keys: a list of any type representing the possible elements to be sampled from
- weights: a list of floats representing the weights for each key
- The lengths of the keys and weights lists must be equal
We will implement this problem using dictionaries.
As a first step, let’s import the random module and set a random seed for reproducibility. That way, we’re making the random number predictable.
import random
random.seed(0)
Next, we define the sample_multimodal function with an input dictionary containing the inputs: "n", "keys", and "weights".
def sample_multimodal(input):
N = input["n"]
K = input["keys"]
W = input["weights"]
Now, we randomly sample N elements from the list K based on the weights W using the choices() method. The weights=W part determines the likelihood of each element being picked. The k=N part specifies the number of elements to sample. Finally, we return the list of randomly sampled elements.
# Sample N elements based on the weights W
sampled_elements = random.choices(K, weights=W, k=N)
The question doesn’t require this, but let’s build a check into the code to see if the function accessed all the required keys.
This part of the code ensures the input dictionary contains all the required keys. In the if key not in input part, we check whether each required key is present in the dictionary; if it’s not a KeyError will be raised with a descriptive message.
Finally, we return the list of randomly sampled elements.
This is the complete code.
import random
random.seed(0)
def sample_multimodal(input):
N = input["n"]
K = input["keys"]
W = input["weights"]
# Sample N elements based on the weights W
sampled_elements = random.choices(K, weights=W, k=N)
# Check if the function accessed all the required keys
required_keys = ["n", "keys", "weights"]
for key in required_keys:
if key not in input:
raise KeyError(f"The key '{key}' is missing from the input dictionary.")
return sampled_elements
Here’s the output.
Expected Output
Official output:
["c", "b", "c", "c", "a"]Official output:
["apple", "banana", "apple", "cherry", "apple", "banana", "apple", "cherry", "banana", "apple"]Official output:
[]Official output:
["x", "x", "y", "x", "y"]Official output:
["gamma", "beta", "delta", "alpha", "gamma", "beta", "alpha"]2. Looping Through a Hashmap
Using loops, you can iterate through a hashmap’s keys, values, or both.
- keys() – Looping through keys.
- values() – Looping through values.
- items() – Looping through both keys and values.
Here’s how you loop through keys.
# Create a dictionary
dictionary = {'name': 'William', 'age': 28, 'city': 'Cairo'}
# Loop through keys
for key in dictionary.keys():
print("Key:", key)
Here’s the output.
Looping through values is the same, only you use values() instead of keys().
# Loop through values
for value in dictionary.values():
print("Value:", value)
Here’s the output.

Of course, you can also loop through both simultaneously.
# Loop through keys and values
for key, value in dictionary.items():
print(f"{key}: {value}")
Here’s the output.


Let’s now see a practical application of this.
Example
Here’s an interview question by EY. It asks you to find the minimum number of coins you must select to make up the given amount of money, assuming an unlimited number of coins from each denomination.
Given an amount of money and a list of coin denominations, what is the minimum number of coins you must select to make up that amount, assuming an unlimited number of coins from each denomination?
Link to the question: https://platform.stratascratch.com/algorithms/10420-minimum-coins-for-total-amount
Here are the given constraints.
- The input variable amount is an integer representing the target amount of money.
- The input variable coins is a list of integers representing the available coin denominations.
- The list coins can have any length.
- The elements in the list coins can be positive integers.
- The elements in the list coins can be in any order.
- The target amount amount can be any non-negative integer.
- The target amount amount can be equal to zero.
- The target amount amount can be greater than zero.
- The target amount amount can be larger than the maximum value that can be represented by an integer.
Now, let’s see the solution. Start with min_coins(input), which extracts the amount and coins from the input.
def min_coins(input):
amount = input["amount"]
coins = input["coins"]
Then, initialize a list dp; dp[i] represents the minimum number of coins required to make up the amount i. So, in our case, the list is of length amount + 1 with all elements set to float('inf') because initially, they are considered unreachable. It is so because the program has no way of determining how to make amounts other than 0, e.g., 1, 2, 3, etc. The starting point is dp[0], which is set to 0, meaning that zero coins are needed to make an amount of 0. The dp list will be used to store the minimum number of coins needed for each amount from 0 to amount.
dp = [float('inf')] * (amount + 1)
dp[0] = 0
We now add two for loops.
The outer loop iterates through all possible amounts from 1 to amount.
The inner loop iterates through each coin denomination. If the current coin is less than or equal to the current amount (i), we calculate dp[i - coin] + 1. This represents the minimum number of coins needed to make up the amount i - coin, plus 1 additional coin (the current coin). The dp[i] list is then updated with the smaller value between its current value and dp[i - coin] + 1.
for i in range(1, amount + 1):
for coin in coins:
if coin <= i:
dp[i] = min(dp[i], dp[i - coin] + 1)
Let’s now add something that is not required by the question: showing the keys and values of the input, which will be shown along with our algorithm output. We use the for loop and the items() method to iterate through input and show the keys and values with the descriptive message.
print("Contents of the input dictionary:")
for key, value in input.items():
print(f"{key}: {value}")
Now, as the last step, the function we defined checks if dp[amount] is different from float('inf'). If it is, the target amount can be reached, and the function returns the minimum number of coins needed, i.e., dp[amount]. Otherwise, the function returns -1, as the target amount can’t be reached.
Here’s the complete code.
def min_coins(input):
amount = input["amount"]
coins = input["coins"]
dp = [float('inf')] * (amount + 1)
dp[0] = 0
for i in range(1, amount + 1):
for coin in coins:
if coin <= i:
dp[i] = min(dp[i], dp[i - coin] + 1)
# Loop through the hashmap
print("Contents of the input dictionary:")
for key, value in input.items():
print(f"{key}: {value}")
return dp[amount] if dp[amount] != float('inf') else -1
Here’s also the output.
Expected Output
Official output:
3Official output:
-1Official output:
03. Merging Two Hashmaps
Another common operation is merging two hashmaps. For this operation, you can use three approaches; the overview is given below.


Let’s see how all three approaches work.
The update() Method
We will create two dictionaries and update the first dictionary with the second dictionary using the update() method.
dict1 = {'name': 'William', 'age': 28, 'city': 'Cairo'}
dict2 = {'profession': 'Engineer', 'education': 'PhD'}
dict1.update(dict2) # Modifies dict1 in-place
print(dict1)
Here’s the output.

The | Operator
By using this operator, you can create a new dictionary by merging two dictionaries.
In the example, I’ll output the merged dictionary along with the original ones so you can see they didn’t change.
dict1 = {'name': 'William', 'age': 28, 'city': 'Cairo'}
dict2 = {'profession': 'Engineer', 'education': 'PhD'}
merged_dict = dict1 | dict2 # Creates a new dictionary
print(merged_dict)
print(dict1)
print(dict2)
Here’s the output.


The ** Unpacking Operator
Here’s how to merge hashmaps with the unpacking operator **. It, too, leaves the original dictionaries as they are and creates a new dictionary.
I’ll show all three dictionaries so you can see it for yourself.
dict1 = {'name': 'William', 'age': 28, 'city': 'Cairo'}
dict2 = {'profession': 'Engineer', 'education': 'PhD'}
merged_dict = {**dict1, **dict2} # Creates a new dictionary
print(merged_dcit)
print(dict1)
print(dict2)
Here’s the output.


Let’s now use these methods in a real-world scenario.
Example
Here’s a question from a Meta interview.
Given a list of numbers, calculate the number of times you need to add each specific number so that every distinct number appears with the same frequency.
Link to the question: https://platform.stratascratch.com/algorithms/10388-balancing-frequency-of-integers
The question wants you to write an algorithm that, with a given list of integers, will find out how many additions are needed for each element so that each integer appears with equal frequency.
Here are the constraints.
- The input variable nums is a list of integers.
- The length of the list nums can be any positive integer.
- The integers in the list nums can be positive, negative, or zero.
- The integers in the list nums can be repeated.
- The integers in the list nums can be in any order.
- The values of the integers in the list nums are within the range of integer values that can be stored in Python.
In the code, we define a function equal_frequency, which calculates the additional frequency needed for each number in a list nums to reach the maximum frequency found in the list. It uses a dictionary to store and process the frequency of each number.
Let’s go through the details of the algorithm.
First, we define the function and the freq dictionary. The for loop counts how many times each number appears in the list nums. The logic is this: if the number num is already a key in freq, increment its value (or frequency), and if it’s not in freq, add it with an initial frequency of 1.
def equal_frequency(nums):
freq = {}
for num in nums:
if num in freq:
freq[num] += 1
else:
freq[num] = 1
The next code block calculates the highest and lowest frequencies among all numbers, and their difference.
max_freq = max(freq.values())
min_freq = min(freq.values())
diff = max_freq - min_freq
Next, we create another dictionary, namely additions. The idea is to identify which numbers need additional occurrences to reach the max_freq and save the required additions in the dictionary.
additions = {}
for num, frequency in freq.items():
if frequency < max_freq:
additions[num] = diff
As the final step, we display the additions dictionary. The complete code is this.
def equal_frequency(nums):
freq = {}
for num in nums:
if num in freq:
freq[num] += 1
else:
freq[num] = 1
max_freq = max(freq.values())
min_freq = min(freq.values())
diff = max_freq - min_freq
additions = {}
for num, frequency in freq.items():
if frequency < max_freq:
additions[num] = diff
return additions
Here’s the output.
Expected Output
Official output:
{"1": 2, "2": 1}Official output:
{"0": 2, "2": 1}Official output:
{}OK, we’ve solved the question, but merging the dictionaries was nowhere in sight. We’ll add it now.
Let’s say you want to output the additions dictionary, as in the above code, but also want to create a new dictionary that merges freq and additions dictionaries.
You could use the | operator before the return command and add the merged dictionary to the output.
def equal_frequency(nums):
freq = {}
for num in nums:
if num in freq:
freq[num] += 1
else:
freq[num] = 1
max_freq = max(freq.values())
min_freq = min(freq.values())
diff = max_freq - min_freq
additions = {}
for num, frequency in freq.items():
if frequency < max_freq:
additions[num] = diff
# Merge the dictionaries
merged = freq | additions
return additions, merged
By showing both dictionaries, you can analyze the adjustments in additions separately and see the consolidated frequencies in merged form.
Expected Output
Official output:
{"1": 2, "2": 1}Official output:
{"0": 2, "2": 1}Official output:
{}Python Hashmaps vs Other Data Structures
Other common data types in Python are lists, tuples, and sets. As a general rule, use those data types and dictionaries in the following cases:
- Dictionaries: For fast lookups or when associating related data (e.g., 'name' -> 'William').
- Lists: For sequential storage or iteration when the order of elements matters.
- Tuples: For immutable collections that should not be modified.
- Sets: For scenarios when you need to ensure elements are unique (e.g., removing duplicates).
Here’s an overview of the data type features.

When to Avoid Hashmaps
While hashmaps are go-to data structures, they’re not always the best fit. Here are some of those situations.

1. When Ordering Matters: Dictionaries didn’t maintain the insertion order of keys and values until Python 3.7. (officially guaranteed in Python 3.8). They do now. However, structures like lists are more suitable for strict ordering requirements. Another option is to use OrderedDict from the collections module; it provides additional features for more advanced ordering of dictionaries.
2.For Sequential Access: If your data requires sequential processing (elements are accessed in the order they are stored), data structures like lists and tuples are more suitable than dictionaries. This is because lists and tuples are designed for index-based access, efficient iteration, and they guarantee order.
3. Memory Constraints: Dictionaries consume more memory than structures like lists or sets because they store keys and their associated values internally. This requires storing additional metadata, such as hash codes and pointers, alongside the actual data.
4. For Small, Fixed Collections: Using tuples or lists in such scenarios is much better because they are simpler, more memory-efficient, and, in the case of tuples, immutable.
Advanced Techniques With Python Hashmaps
Besides the common operations, there are also advanced techniques that extend the hashmap use.

1. Default Dictionaries (From Collections Module)
Default dictionaries (defaultdict) are special types of dictionaries from Python’s collections module. They automatically assign a default value to a key if it doesn’t exist. It’s helpful when you want to avoid KeyError, e.g., when appending values to the non-existent key.
Here’s an example. If you wanted to append values the regular way, it would require manual initialization of each key. The logic is to check if a key exists, create it if it doesn’t, and then append a value like this.
regular_dict = {}
# Regular dictionary requires manual key creation
if 'cars' not in regular_dict:
regular_dict['cars'] = []
regular_dict['cars'].append('Renault')
if 'cars' not in regular_dict:
regular_dict['cars'] = [] # Repeated logic
regular_dict['cars'].append('Mercedes')
if 'motorcycles' not in regular_dict:
regular_dict['motorcycles'] = []
regular_dict['motorcycles'].append('Kawasaki')
print(regular_dict)
Here’s the output.

Otherwise, if you try to add value to a non-existing key, it would raise a KeyError. So, you’d have to repeat the logic from the example above if it weren’t for defaultdict that simplifies the process because the key initialization is automatic.
from collections import defaultdict
default_dict = defaultdict(list)
# No need to check if the keys exist
default_dict['cars'].append('Renault')
default_dict['cars'].append('Mercedes')
default_dict['motorcycles'].append('Kawasaki')
print(default_dict)
Here’s the output.


Let’s now see its application.
Example
Amazon's question asks you to find common elements in two given lists and return all aspects, even if they are repeated.
Find common elements in 2 given lists and return all aspects even if they are repeated.
Link to the question: https://platform.stratascratch.com/algorithms/10410-common-elements-with-repeated-values
The question gives these constraints.
- The input variables list1 and list2 should be of type List[int].
- The input lists can have any length.
- The elements in the input lists can be repeated.
- The elements in the input lists can be in any order.
- The input lists can contain both positive and negative integers.
- The input lists can contain zero as an element.
- The input lists can be empty.
We’ll solve the question using defaultdict.
We import defaultdict from the collections module and define the common_elements function. The input is expected to be a dictionary containing two lists: list1 and list2.
from collections import defaultdict
def common_elements(input):
list1 = input["list1"]
list2 = input["list2"]
Next, defaultdict(int) initializes a dictionary with a default value of 0 for keys that don’t exist. This eliminates the need to check whether a key exists before incrementing its value.
# Use defaultdict to simplify key existence checks
counter1 = defaultdict(int)
counter2 = defaultdict(int)
These dictionaries will keep track of how many times each item appears in list1 and list2.
The two for loops iterate over each list and increment the count of each element.
# Populate counter1
for item in list1:
counter1[item] += 1 # No need for manual checks
# Populate counter2
for item in list2:
counter2[item] += 1 # No need for manual checks
Now, we can find the common elements between the two lists. The for loop iterates through each key in counter1 and checks if it exists in counter2. If a key exists in both dictionaries, the minimum count of that key between the two dictionaries is stored in the common dictionary.
# Find common elements
common = {}
for key in counter1:
if key in counter2:
common[key] = min(counter1[key], counter2[key])
Finally, we construct the result list by repeating each key in the common dictionary according to its count. The extend() method appends a list of [key] * count to result.
This is the complete code.
from collections import defaultdict
def common_elements(input):
list1 = input["list1"]
list2 = input["list2"]
# Use defaultdict to simplify key existence checks
counter1 = defaultdict(int)
counter2 = defaultdict(int)
# Populate counter1
for item in list1:
counter1[item] += 1 # No need for manual checks
# Populate counter2
for item in list2:
counter2[item] += 1 # No need for manual checks
# Find common elements
common = {}
for key in counter1:
if key in counter2:
common[key] = min(counter1[key], counter2[key])
# Build the result
result = []
for key, count in common.items():
result.extend([key] * count)
return result
Here’s the output.
Expected Output
Official output:
[2, 2, 3, 4]Official output:
[-1, 0, 1, 2]Official output:
[]2. Hashmap of Hashmaps (Nested Dictionaries)
Nested dictionaries or hashmaps of hashmaps are what you think they are: dictionaries within a dictionary. They are used to represent complex structures, such as nested data or grouped information.
You create it directly by using Python’s dictionary literals ({}) to define keys and their values, where a value itself is another dictionary.
Here’s an example of how to do it. In a nested dictionary, we create two other dictionaries: car and motorcycle.
# Nested dictionary example
nested_dict = {
'car': {'brand': 'Renault', 'model': 'Clio'},
'motorcycle': {'brand': 'Kawasaki', 'model': 'Ninja 500 SE'}
}
# Access nested data
print("Car's Brand:", nested_dict['car']['brand'])
print("Motorcycle's Model:", nested_dict['motorcycle']['model'])
# Add a new key to the inner dictionary
nested_dict['car']['model_year'] = '2018'
print("Updated Nested Dictionary:", nested_dict)
Here’s the code output.


You can also build a nested dictionary dynamically by adding keys and subkeys programmatically, which typically involves loops or conditionals.
Here’s one example of how to do it.
First, create an empty dictionary nested_dict. Then, populate it by iterating over a list of vehicles.
Next, use the for loop to initialize an empty inner dictionary type, if the vehicle['type'] is not already a key in nested_dict.
The query then adds the vehicle’s brand as a key under the type and assigns a dictionary of the vehicle’s details (model, year, etc.) as the value.
You can also see how to access nested data. In the final part of the code, we show how to dynamically add new key-value pairs to the inner dictionary, i.e., "color": "Blue".
# Initialize an empty nested dictionary
nested_dict = {}
# Dynamically populate the nested dictionary
vehicles = [
{'type': 'car', 'brand': 'Renault', 'model': 'Clio', 'model_year': '2018'},
{'type': 'motorcycle', 'brand': 'Kawasaki', 'model': 'Ninja 500 SE', 'model_year': '2021'},
{'type': 'car', 'brand': 'Toyota', 'model': 'Corolla', 'model_year': '2020'}
]
for vehicle in vehicles:
vehicle_type = vehicle['type']
if vehicle_type not in nested_dict:
nested_dict[vehicle_type] = {} # Initialize an empty inner dictionary
# Add details to the inner dictionary
nested_dict[vehicle_type][vehicle['brand']] = {
'model': vehicle['model'],
'model_year': vehicle['model_year']
}
# Access nested data
print("Car's Model (Renault):", nested_dict['car']['Renault']['model'])
print("Motorcycle's Model (Kawasaki):", nested_dict['motorcycle']['Kawasaki']['model'])
# Dynamically update the nested dictionary
nested_dict['car']['Renault']['color'] = 'Blue'
print("Updated Nested Dictionary:", nested_dict)
Here’s the output.


Example
Another interview question by Meta is suitable for demonstrating how nested dictionaries can be used in practice.
Given a 2D array of user IDs, find the number of friends a user has. Note that users can have none or multiple friends.
Link to the question. https://platform.stratascratch.com/algorithms/10404-friend-count-in-user-array/
We’re given a 2D array of user IDs, and the goal is to find the number of friends a user has, with a note that users can have none or multiple friends. We’ll modify the question and also add the indices of the sublists (or rows) to the output.
Here are the constraints.
- The input variable user_ids is a 2D array of user IDs.
- Each element in the user_ids array is a list of integers representing the user IDs.
- The user IDs can be any positive or negative integer value.
- The user_ids array can have any number of rows and columns.
- The user IDs within each row can be in any order.
- The user_ids array can contain duplicate user IDs.
- The output variable is a dictionary (Dict[int, int]) where the keys are the user IDs and the values are the count of friends for each user.
Here’s how we can approach the solution. First, let’s define a function named count_friends. It takes a 2D array user_ids as the input. Within the function we initialize an empty dictionary friend_count; it’ll be used for storing results.
def count_friends(user_ids):
friend_count = {}
Next, the outer for loop uses enumerate() to iterate over user_ids and get both the row index (row_index) and the row itself (row).
The inner loop iterates through each user_id in the current row. If the user_id is not already in friend_count, it creates an entry for it in the dictionary friend_count, thus becoming a dictionary within a dictionary, i.e., a nested dictionary. The total_count is initialized to 0 (it’s the first time the user_id is being processed) and rows to an empty list (it will later store the indices of the rows in which this user_id appears).
Now we can update total_count by incrementing it by 1, reflecting the occurrence of the user_id. Also, we append the current row_index to the rows list, recording where the user_id appeared.
for row_index, row in enumerate(user_ids):
for user_id in row:
if user_id not in friend_count:
friend_count[user_id] = {"total_count": 0, "rows": []}
friend_count[user_id]["total_count"] += 1
friend_count[user_id]["rows"].append(row_index)
Finally, we can return the friend_count dictionary with the complete code looking like this.
def count_friends(user_ids):
friend_count = {}
for row_index, row in enumerate(user_ids):
for user_id in row:
if user_id not in friend_count:
friend_count[user_id] = {"total_count": 0, "rows": []}
friend_count[user_id]["total_count"] += 1
friend_count[user_id]["rows"].append(row_index)
return friend_count
Here’s the output.
Expected Output
Official output:
{"4": 3, "-3": 2, "15": 2, "22": 2}Official output:
{"3": 3, "7": 4, "8": 3}Official output:
{"20": 3, "30": 2, "-10": 3}3. Dictionary Comprehension
A dictionary comprehension in Python is a neat way of creating dictionaries by embedding logic, such as loops and conditional statements, directly within curly braces ({}). This allows you to build dictionaries in one line.
The syntax is as follows.
{key_expression: value_expression for item in iterable if condition}
Here’s the explanation of each code element.
- key_expression: Determines the key for each entry in the dictionary.
- value_expression: Determines the value corresponding to each key.
- iterable: The sequence or collection to iterate over, e.g., a list, range, another dictionary.
- condition: This is an optional filter that determines whether to include an entry.
In this example, I create a dictionary with squares of numbers. In the code, x is a variable used in iteration, representing each integer in the range. The value assigned to it is x**2, i.e., the square of x. The range produces the integers 1, 2, 3, 4, 5 (not 6, as the upper limit is exclusive).
The code iterates over the numbers from 1 to 5, assigns a key to each of them in the dictionary, and the square root of each integer as the corresponding value.
squares = {x: x**2 for x in range(1, 6)}
print("Squares Dictionary:", squares)
Here’s the output.

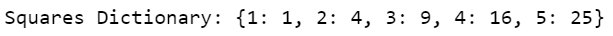
Another example of dictionary comprehension is filtering a dictionary.
In the code below, we iterate through the original dictionary and create a new dictionary based on the filtered values. The for key, value in original.items() part loops through each key-value pair in the original dictionary using the items() method.
If the value is divisible by 2 (without a remainder), the key:value pair is added to the new dictionary.
original = {'a': 1, 'b': 2, 'c': 3, 'd': 4}
filtered = {key: value for key, value in original.items() if value % 2 == 0}
print("Filtered Dictionary:", filtered)
Here’s the output.


We’ll now see how to use it in practice.
Example
We’ll solve this Spotify algorithm interview question.
Write a function to find the square root of all column values in a DataFrame.
Note: The function should only compute the square root for non-negative numbers (i.e., values greater than or equal to 0). If any value in the DataFrame is negative, the function should return None for that particular value.
Link to the question: https://platform.stratascratch.com/algorithms/10400-dataframe-square-root-function
We will write a function that finds the square root of all column values. However, we’ll bypass the use of pandas DataFrame, and use pure Python with dictionary comprehension. The result will be the same, requiring less coding than the official solution.
The input structure is a dictionary where keys are column names (e.g., "A", "B"), and values are lists of values in those columns.
Here’s our solution.
We define the find_square_root. The loop (for key, values in input_data['df'].items()) iterates through each key and its corresponding list of values in the dictionary.
The list comprehension ensures that x is numeric (isinstance(x, (int, float))). It then ensures that x is not negative, which means the square root is only calculated for non-negative numbers. It then computes the square root (x ** 0.5) for valid values. If x is negative or non-numeric, it assigns None.
def find_square_root(input_data):
# Use dictionary comprehension to calculate square root for numeric columns
result = {
key: [x ** 0.5 if isinstance(x, (int, float)) and x >= 0 else None for x in values]
for key, values in input_data['df'].items()
}
return result
Here’s the output.
Expected Output
Official output:
{"A": [2, 4, 5, 6], "B": [1, 2, 3, 4]}Official output:
{"A": [1, 0, 3, 9], "B": [1, 0, 4, 8]}Official output:
{"A": [0.5, 1.5, 2.5, 3.5], "B": [0.5, 1, 1.5, 2.5]}Python Hashmaps Best Practices, Common Errors, and How to Avoid Them
To leverage hashmaps’ full potential, follow these best practices.


1. Use Immutable Keys: Mutable objects, such as lists, can’t be hashed and will raise an error. So, always use immutable objects like strings, numbers, or tuples as keys.
2. Handle Missing Keys: Leverage built-in dictionary methods like get() to handle missing keys elegantly and avoid KeyError.
Here’s a short example where the code returns ‘Not Found’ instead of an error.
dictionary = {'name': 'William'}
print(dictionary.get('age', 'Not Found')) # Returns 'Not Found' instead of raising an error
Here’s the output.


3. Avoid Overwriting Keys: When you construct dictionaries dynamically, be aware that duplicate keys in a dictionary overwrite the previous value, as shown in the example below.
hashmap = {'name': 'William', 'name': 'Zoe'}
print(hashmap)
Here’s the output.
4. Choose Default Dictionaries for Missing Keys: If you repeatedly access keys that might not exist, use defauldict, as we’ve shown earlier, to simplify the logic.
5. Optimize for Large Data: Dictionaries can easily become memory-intensive if you’re using large datasets. Consider using pandas’ DataFrames instead. They are optimized for scalable data operations.
6. Document Your Keys: When using dictionaries, document the keys.
7. Use Dictionary Comprehensions Wisely: While dictionary comprehension can improve code readability and reduce code complexity, it can have the opposite effect if the comprehension becomes too long or involves nested conditionals. In such cases, use traditional loops.
Conclusion
We covered many Python hashmap topics, yet we only scratched the surface. Their vast practical use calls for action from you; nobody will pour the knowledge into your head and teach you all the nuances of using dictionaries. This all comes through practice. If you don’t use Python dictionaries in your everyday work, solving the algorithm interview questions is the best way to get practical experience.
Share


