Database Interview Questions


Categories:
 Written by:
Written by:Nathan Rosidi
We’ll show you the most common SQL concepts you need to know to solve database interview questions.
Today, the database is almost a synonym with SQL. Even though those are two separate things, the popularity of SQL for working with databases made it unimaginable to know databases without knowing SQL or vice versa.
In this article, we’ll solely focus on SQL coding questions. This is the single most important technical skill for anyone working with databases. Of course, it’s not the only skill, so you might want to find out the other skills needed to be a data scientist.
All other database interview questions can contain a little bit of this or a little bit of that, depending on the job description. But by covering the SQL questions, we’ll cover one technical skill that is, almost without exception, required in every data science job you take up. Be it data analyst, data engineer, or data scientist; you’ll have to know SQL.
We’re going to show you topics that represent the SQL knowledge required for every data science position.
How will we approach this? On the StrataScratch platform, the questions are also categorized in the topic family. We’ll use this to give you the most popular topics as a common ground for every data science job position.
The Seven Common Topics Tested in SQL Database Interview Questions
The topics most tested are:
- Aggregate functions and the DISTINCT clause
- WHERE clause
- GROUP BY clause
- Ranking rows and LIMIT clause
- Subqueries and CTEs
- JOINs
- Data organizing and pattern matching
We’ll shortly explain every concept, and then we’ll go through some SQL database interview questions that test it. These concepts are, of course, interweaving, so usually, several of those concepts are tested in one question, sometimes even all of them.

1. Aggregate Functions and the DISTINCT Clause
The aggregate functions, as the name suggests, aggregate data. How do they do that? They perform a calculation on a data set and return one row with a single value.
Maybe you don’t know they’re called that, but you probably used some of the most popular aggregate functions:
- SUM()
- COUNT()
- MIN()
- MAX()
- AVG()
For example, this easy Twitch database interview question requires both aggregate functions and GROUP BY knowledge:
Last Updated: February 2021
Calculate the average session duration (in seconds) for each session type?
Link to the question: https://platform.stratascratch.com/coding/2011-session-type-duration
Answer:
SELECT session_type,
avg(session_end -session_start) AS duration
FROM twitch_sessions
GROUP BY session_type;To solve this problem, you need to calculate the session duration using the AVG() function on a difference between session start and end, i.e., the session duration. Since you have to show data on a session type level, you’ll also have to use GROUP BY on a session_type column.
The code will return this result:
Aggregation of data is one of the main ways to organize and clean data, which is one of the data scientist’s jobs. A great way to practice aggregate functions is the Mode Analytics SQL tutorial on aggregate functions. Of course, you can solve some of the StrataScratch interview questions too.
For example, the Unique Users Per Client Per Month question by Microsoft:
Last Updated: March 2021
Write a query that returns the number of unique users per client per month.
“Write a query that returns the number of unique users per client per month”
Or maybe a little more complex one by DoorDash:
“Write a query that returns the average order cost per hour during hours 3 PM -6 PM (15-18) in San Jose. For calculating time period use 'Customer placed order datetime' field. Earnings value is 'Order total' field. Order output by hour.”
One of the useful tools for data scientists is the DISTINCT clause, which selects only unique values. This is helpful when you have to report on events that can happen multiple times on various levels, e.g., a customer, order, day level. It is often used with aggregate functions, that’s why we’ll show it to you in this section.
To solve this Postmates database interview question, you’ll need the DISTINCT clause:
Last Updated: February 2021
How many customers placed an order and what is the average order amount?
“How many customers placed an order and what is the average order amount?”
Link to the question: https://platform.stratascratch.com/coding/2013-customer-average-orders
Answer:
In this query, you’ll use the COUNT() to count the number of customers. You need the DISTINCT keyword to count every customer only once. There’s also an AVG() function for calculating the average order amount.
Here’s the output:
2. WHERE Clause
In SQL, the WHERE clause serves as a data filter. Once the filtering criteria are set up using the WHERE clause, the SQL statement will return data that fulfill these criteria.
This Forbes database interview question asks you to filter data in a very straightforward way:
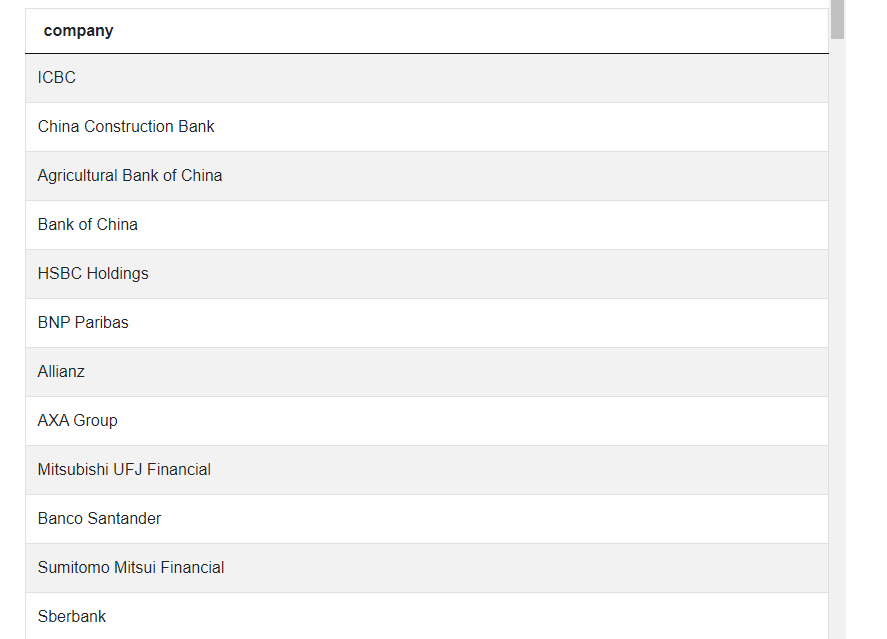
“Find companies in the financial sector based on Europe and Asia.”
Link to the question: https://platform.stratascratch.com/coding/9678-find-finance-companies-based-in-europe-and-asia
Answer:
SELECT
company
FROM forbes_global_2010_2014
WHERE
(continent = 'Asia' OR continent = 'Europe') AND
(sector = 'Financials');You’re working with only one table here. You have to set two criteria using the WHERE clause to get the correct result. The first one is the companies have to be from Europe or Asia. The second one is the company’s sector has to be financial.
Run the code, and you’ll get this output. We’re showing only several first rows here:

The WHERE clause can also be used with the SELECT statement too. One good example of how this is done is the Top Cool Votes database interview question by Yelp:
Last Updated: March 2020
Find the review_text that received the highest number of cool votes.
Output the business name along with the review text with the highest number of cool votes.
Link to the question: https://platform.stratascratch.com/coding/10060-top-cool-votes
Answer:
SELECT business_name,
review_text
FROM yelp_reviews
WHERE cool =
(SELECT max(cool)
FROM yelp_reviews);This query simply selects all the business and review texts. However, we don’t need all this data, but only the business with the highest number of ‘cool’ votes. The criteria are stated in the WHERE clause, and the businesses with the highest number of ‘cool’ votes are selected with the help of the MAX() aggregate function in the SELECT statement.
And this is the output:
For practicing the WHERE clause, you can select from numerous StrataScratch questions that test that. It could be a rather simple one, like this one by Ring Central:
Last Updated: January 2021
Return a list of users with status free who didn’t make any calls in Apr 2020.
Or it could be a hard one, as this one by Microsoft:
Last Updated: March 2021
Select the most popular client_id based on a count of the number of users who have at least 50% of their events from the following list: 'video call received', 'video call sent', 'voice call received', 'voice call sent'.
3. GROUP BY Clause
The following important SQL interview topic for any aspiring data scientist for database interview questions is the GROUP BY clause. Because, aside from aggregating and filtering data, you’ll also have to group it. That’s exactly what the GROUP BY clause does: it groups all the rows with the same value in the column(s) you’re grouping by.
This clause is also often used with the aggregate functions. That’s why it’s important to know both.
To solve the following SQL database interview question from Airbnb, you’ll have to know the aggregate functions, the GROUP BY clause, and also the HAVING clause, which is also common with the GROUP BY:
Last Updated: January 2018
Find the average number of beds in each neighborhood that has at least 3 beds in total.
Output results along with the neighborhood name and sort the results based on the number of average beds in descending order.
Link to this database interview question: https://platform.stratascratch.com/coding/9627-3-bed-minimum
Answer:
SELECT neighbourhood,
avg(beds) AS n_beds_avg
FROM airbnb_search_details
WHERE neighbourhood IS NOT NULL
GROUP BY neighbourhood
HAVING sum(beds) >= 3
ORDER BY n_beds_avg DESC;This query selects the neighbourhood and calculates the average number of beds using the AVG() aggregate function. To get the average on a neighbourhood level, you need to group data by this column. This database interview question also requires that neighbourhoods shown should have at least three beds in total. To calculate this, you need the SUM() aggregate function put in the HAVING clause.
The HAVING clause is also used for filtering data along with the WHERE clause. The main difference is that WHERE is used before grouping data while HAVING is used after you’ve grouped the data.
Finally, the code above sorts data by the average number of beds in descending order. To do that, you need the ORDER BY clause. This nicely leads us to the fourth important SQL topic for database interview questions.
Before that, here’s the code output:
4. Ranking Rows and LIMIT Clause
Ranking rows is usually done by one of the following window functions:
- ROW_NUMBER()
- RANK()
- DENSE_RANK()
SQL window functions, by definition, are the SQL functions that use the set of data (or window) to perform the calculation. They can seem similar to the aggregate functions, but the main difference is the window functions don’t show the result in one row, but they leave the original data and return results in an additional column beside it.
The Ranking Most Active Guests database interview question by Airbnb is a good example:
Identify the most engaged guests by ranking them according to their overall messaging activity. The most active guest, meaning the one who has exchanged the most messages with hosts, should have the highest rank. If two or more guests have the same number of messages, they should have the same rank. Importantly, the ranking shouldn't skip any numbers, even if many guests share the same rank. Present your results in a clear format, showing the rank, guest identifier, and total number of messages for each guest, ordered from the most to least active.
Link to the question: https://platform.stratascratch.com/coding/10159-ranking-most-active-guests
Answer:
SELECT
DENSE_RANK() OVER(ORDER BY sum(n_messages) DESC) as ranking,
id_guest,
sum(n_messages) as sum_n_messages
FROM airbnb_contacts
GROUP BY id_guest
ORDER BY sum_n_messages DESC;This query uses the DENSE_RANK() to rank guests by the sum of number of their messages. Along with rank, the output will show the guest ID and the total number of messages per guest. The result will be shown by the number of messages in descending order.
Here it is:
LIMIT is also used for ranking rows. Its primary function is to limit the number of rows shown in the output. Combine it with ORDER BY, and you have a great tool for showing top N values, which is often in reporting.
When speaking of using LIMIT, this database interview question from Yelp is a good showcase of its use:
Find the top 5 businesses with the most check-ins. Output the business id along with the number of check-ins.
Link to the question: https://platform.stratascratch.com/coding/10053-most-checkins
Answer:
SELECT
business_id,
sum(checkins) AS n_checkins
FROM yelp_checkin
GROUP BY
business_id
ORDER BY
n_checkins DESC
LIMIT 5;
Again, you have to know aggregate functions here. The SUM() function, more specifically, to sum the number of check-ins. Since you want your data on a business level, you’ll have to use GROUP BY. Then you order data according to the number of check-ins in descending order. To get the top five, you just need to limit the output to the first five rows.
And there it is:
5. Subqueries and CTEs
For more complex queries, it’s often necessary to know subqueries or CTEs, ideally both.
A subquery is a query within a larger query. It can usually be found in another SELECT statement or in the WHERE clause.
Let’s see how subqueries work by answering the database interview question from Spotify. Aside from subqueries, you also need to know aggregate functions, the WHERE, GROUP BY, and ORDER BY clauses.
Find the number of songs of each artist which were ranked among the top 10 over the years. Order the result based on the number of top 10 ranked songs in descending order.
Link to the question: https://platform.stratascratch.com/coding/9743-top-10-songs
Answer:
SELECT
artist,
count(distinct song_name) AS top10_songs_count
FROM
(SELECT
artist,
song_name
FROM billboard_top_100_year_end
WHERE
year_rank <= 10
) temporary
GROUP BY
artist
ORDER BY
top10_songs_count DESC;This query selects artists and counts the number of distinct songs. It does that from a subquery. This subquery searches for songs that were among the top 10 over the years. After that, the result is grouped on an artist level and sorted by the number of distinct songs in descending order.
If you like Elvis Presley, you’ll be happy to see him on top of our result:
CTE stands for Common Table Expression, and it has a similar function to subquery. They are used to write more complex queries and to translate calculation logic that has several steps to a database language.
This database interview question by Yelp is a good start for showing you how CTE works:
Find the top 5 cities with the highest number of 5-star businesses.
The output should include the city name and the total count of 5-star businesses in that city, considering both open and closed businesses. If two or more cities have the same number of 5-star businesses, assign them the same rank, and skip the next rank accordingly. For example, if two cities tie for 1st place, the following city should be ranked 3rd.
Link to the question: https://platform.stratascratch.com/coding/10148-find-the-top-10-cities-with-the-most-5-star-businesses
Answer:
WITH cte_5_stars AS
(SELECT city,
count(*) AS count_of_5_stars,
rank() over(
ORDER BY count(*) DESC) AS rnk
FROM yelp_business
WHERE stars = 5
GROUP BY 1)
SELECT city,
count_of_5_stars
FROM cte_5_stars
WHERE rnk <= 5
ORDER BY count_of_5_stars DESC;Like any CTE, this one is initiated by the keyword WITH. The SELECT statement select cities with five stars, then it counts them and ranks them. The next SELECT statement references the CTE to select only those cities where their rank is five or lower, i.e., outputs the top five cities.
These are the top cities:
6. JOINs
For anyone who wants to use more than one table in a database, which is probably most users, knowing JOINs is essential. It’s due to the database logic, where the database is normalized, and data is separated in multiple tables.
One of the data scientists’ main jobs is to work with raw data and transform it into formats suitable for others. To do that, they need to combine multiple tables. Without JOINs, they wouldn’t be able to do that. If you’re not sure about the difference between various data science jobs, this guide through 14 different data science job positions will make everything clear.
This Amazon database interview question tests JOINs nicely. Along with that, you’ll also have to show knowledge of aggregate functions, WHERE, GROUP BY, and HAVING clauses, as well as subqueries.
Last Updated: May 2019
Find the customer with the highest daily total order cost between 2019-02-01 to 2019-05-01. If customer had more than one order on a certain day, sum the order costs on daily basis. Output customer's first name, total cost of their items, and the date.
For simplicity, you can assume that every first name in the dataset is unique.
Link to this database interview question: https://platform.stratascratch.com/coding/9915-highest-cost-orders
Answer:
SELECT first_name,
sum(total_order_cost) AS total_order_cost,
order_date
FROM orders o
LEFT JOIN customers c ON o.cust_id = c.id
WHERE order_date BETWEEN '2019-02-1' AND '2019-05-1'
GROUP BY first_name,
order_date
HAVING sum(total_order_cost) =
(SELECT max(total_order_cost)
FROM
(SELECT sum(total_order_cost) AS total_order_cost
FROM orders
WHERE order_date BETWEEN '2019-02-1' AND '2019-05-1'
GROUP BY cust_id,
order_date) b);The query uses the SUM() aggregate function to calculate the total order cost. To get all data you need, you have to LEFT JOIN two tables. Data is filtered on order date using the WHERE clause. Next, data is grouped by the customer’s first name and order date. You need to output the customer with the highest daily total order. To do that, you need the HAVING clause to get data where the sum of the order costs per customer and per date is equal to the order maximum. This is where you need another aggregate functions, which is MAX().
Here’s the output:
Check out our post "How to Join 3 or More Tables in SQL" where we talk about using this commonly required SQL concept.
7. Data Organizing and Pattern Matching
One of the data scientists' jobs is to organize, clean, and analyze data. During this analysis, they’ll usually try to find some patterns in the data. You might ask "isn’t that something a data engineer does?". Well, yes and no. To understand the difference between data scientists and data engineers, have a look at the blog post comparing these two careers.
One good example of covering organizing data is this database interview question by the City of San Francisco:
Last Updated: May 2018
Classify each business as either a restaurant, cafe, school, or other.
• A restaurant should have the word 'restaurant' in the business name. • A cafe should have either 'cafe', 'café', or 'coffee' in the business name. • A school should have the word 'school' in the business name. • All other businesses should be classified as 'other'. • Ensure each business name appears only once in the final output. If multiple records exist for the same business, retain only one unique instance.
The final output should include only the distinct business names and their corresponding classifications.
Link to the question: https://platform.stratascratch.com/coding/9726-classify-business-type
Answer:
SELECT distinct business_name,
CASE
WHEN business_name ilike any(array['%school%']) THEN 'school'
WHEN lower(business_name) like any
(array['%restaurant%']) THEN 'restaurant'
WHEN lower(business_name) like any
(array['%cafe%', '%café%', '%coffee%']) THEN 'cafe'
ELSE 'other'
END AS business_type
FROM sf_restaurant_health_violations;This question requires you to clean data and organize it into business types. There are specific criteria needed for that, as stated in the CASE WHEN statement.
Your organized data will look like this:
Once the data is organized, you’ll need to find patterns in it. One good example for practicing this is the Meta/Facebook interview question:
“Find how the number of `likes` are increasing by building a `like` score based on `like` propensities. A `like` propensity is defined as the probability of giving a like amongst all reactions, per friend (i.e., number of likes / number of all reactions).
Output the average propensity alongside the corresponding date and poster. Sort the result based on the liking score in descending order.
In `facebook_reactions` table `poster` is user who posted a content, `friend` is a user who saw the content and reacted. The `facebook_friends` table stores pairs of connected friends.”
Link to the question: https://platform.stratascratch.com/coding/9775-liking-score-rating
Answer:
WITH p AS
(SELECT SUM(CASE
WHEN reaction = 'like' THEN 1
ELSE 0
END)/COUNt(*)::decimal AS prop,
friend
FROM facebook_reactions
GROUP BY 2)
SELECT date_day,
poster,
avg(prop)
FROM facebook_reactions f
JOIN p ON f.friend= p.friend
GROUP BY 1,
2
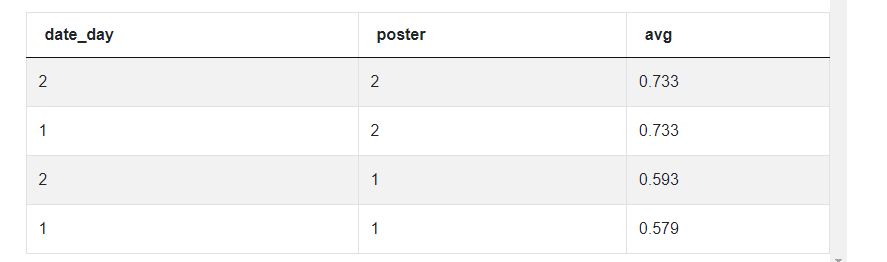
ORDER BY 3 DESC;The first concept here is the CTE which is initiated using the keyword WITH. It allocates the value 1 to every like, then sums the likes, and divides the sum by the number of all reactions. Data is then grouped by a friend. This is how we get the propensity defined in the question.
The following SELECT statement uses the CTE to calculate the average propensity using the AVG() functions. To do that, you need to JOIN two tables, group data by date and poster, and order it by propensity in descending order.
Your output should be this:

Conclusion
In total, we’ve covered seven SQL topics tested in database interview questions:
- Aggregate functions and the DISTINCT clause
- WHERE clause
- GROUP BY clause
- Ranking rows and LIMIT clause
- Subqueries and CTEs
- JOINs
- Data organizing and pattern matching
The SQL database interview questions heavily test all seven topics. You should always expect these topics because you’ll have to use them extensively if you want to work in data science.
Even though all the topics are a must, some topics are more important to specific jobs than others. Data scientists, data engineers, and data analysts will all have to know subqueries and CTEs, JOINs, and all other functions used for organizing data and finding patterns in it.
So don’t avoid these topics. But if you want to be a data engineer, you should put even more emphasis on JOINs. The same goes with data scientists and data analysts placing emphasis on all SQL concepts that are used in organizing data and finding patterns.
The best advice is to go through all these topics to make sure you have a firm grasp of the most tested SQL concepts in the job interviews. Some additional SQL questions that you must prepare are covered by the article "SQL interview questions".
Share


