CONCAT() in SQL: Tips and Techniques for Efficient Queries

Categories:
 Written by:
Written by:Nathan Rosidi
CONCAT() in SQL is a data concatenation method. Learn about the tips, techniques, and practical examples of how to use it efficiently in SQL queries.
Concatenate (verb), “to link together in a series or chain”, according to the Merriam-Webster dictionary. What does it mean in the context of SQL, what do you “link together” in SQL queries, and how?
The answer to the latter question is the CONCAT() function, which I’ll introduce you to in this article. You’ll learn its syntax, common use cases, and advanced techniques for concatenation. I’ll also talk about database-specific variations of CONCAT() and show you practical examples by solving a couple of interview questions from our platform.
What is Concatenation in SQL?
Now, let’s answer the question of what do you link together. In SQL, concatenation means joining two or more strings (or values) into a single string. It is commonly used for merging data from multiple columns, formatting data to make it more readable, or creating a custom output, such as adding labels and joining them with dynamic data from a table.
What is concatenation also? One of the favorite topics in the SQL interview questions.
Basic Syntax of the SQL CONCAT() Function
The CONCAT() function is your main tool for concatenating data in SQL. Its syntax is:
CONCAT(string1, string2, ..., stringN)The string1, string2, ..., stringN part represents strings you want to concatenate. Note: CONCAT() also accepts other data types, such as dates and numbers, but it implicitly casts them to strings when concatenating.
Here’s a simple example of how SQL CONCAT() works. If you have a table named employees…
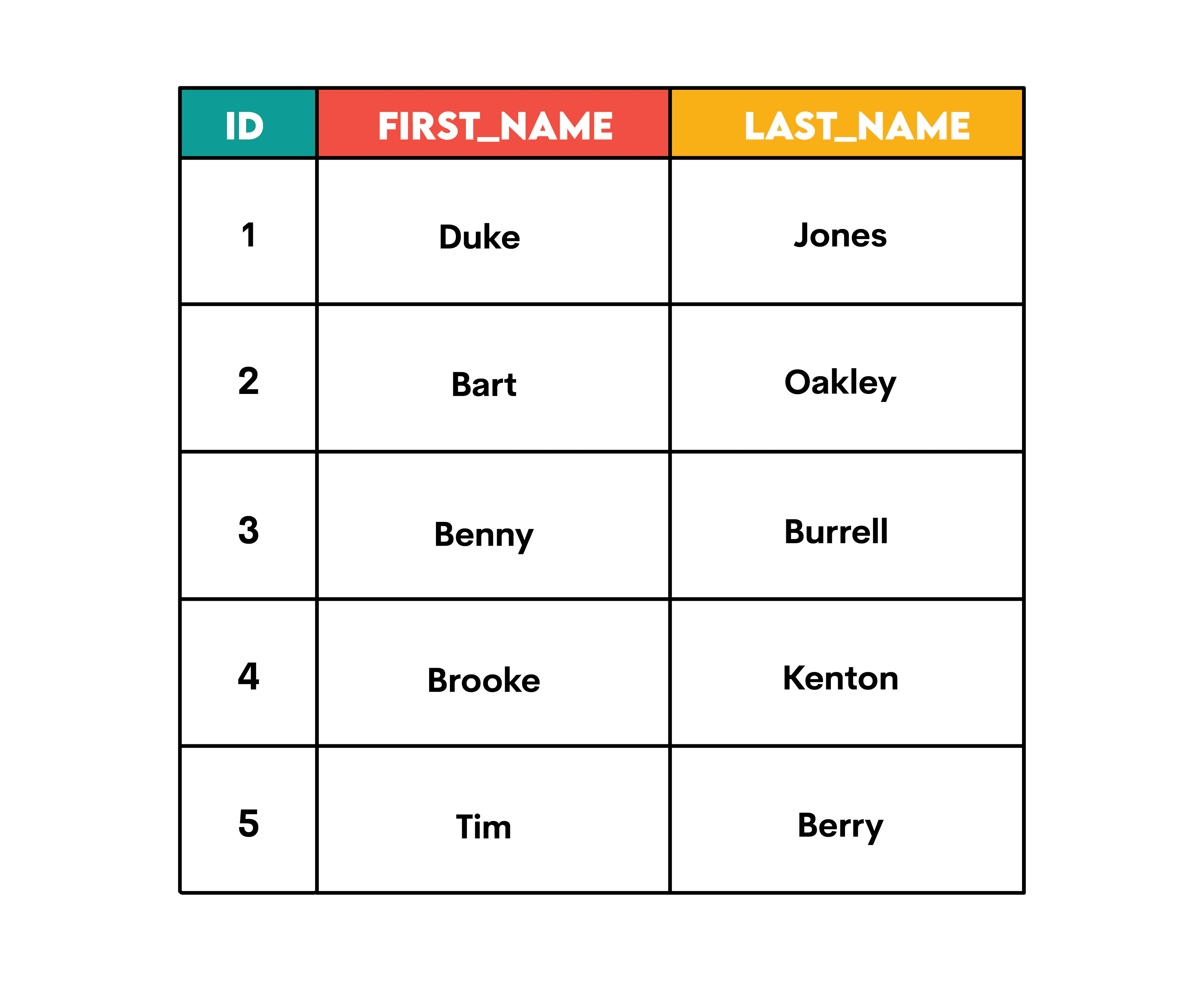
…and write this query…
SELECT CONCAT(first_name, ' ', last_name) AS full_name
FROM employees;
…you will get the employees' names in one column.
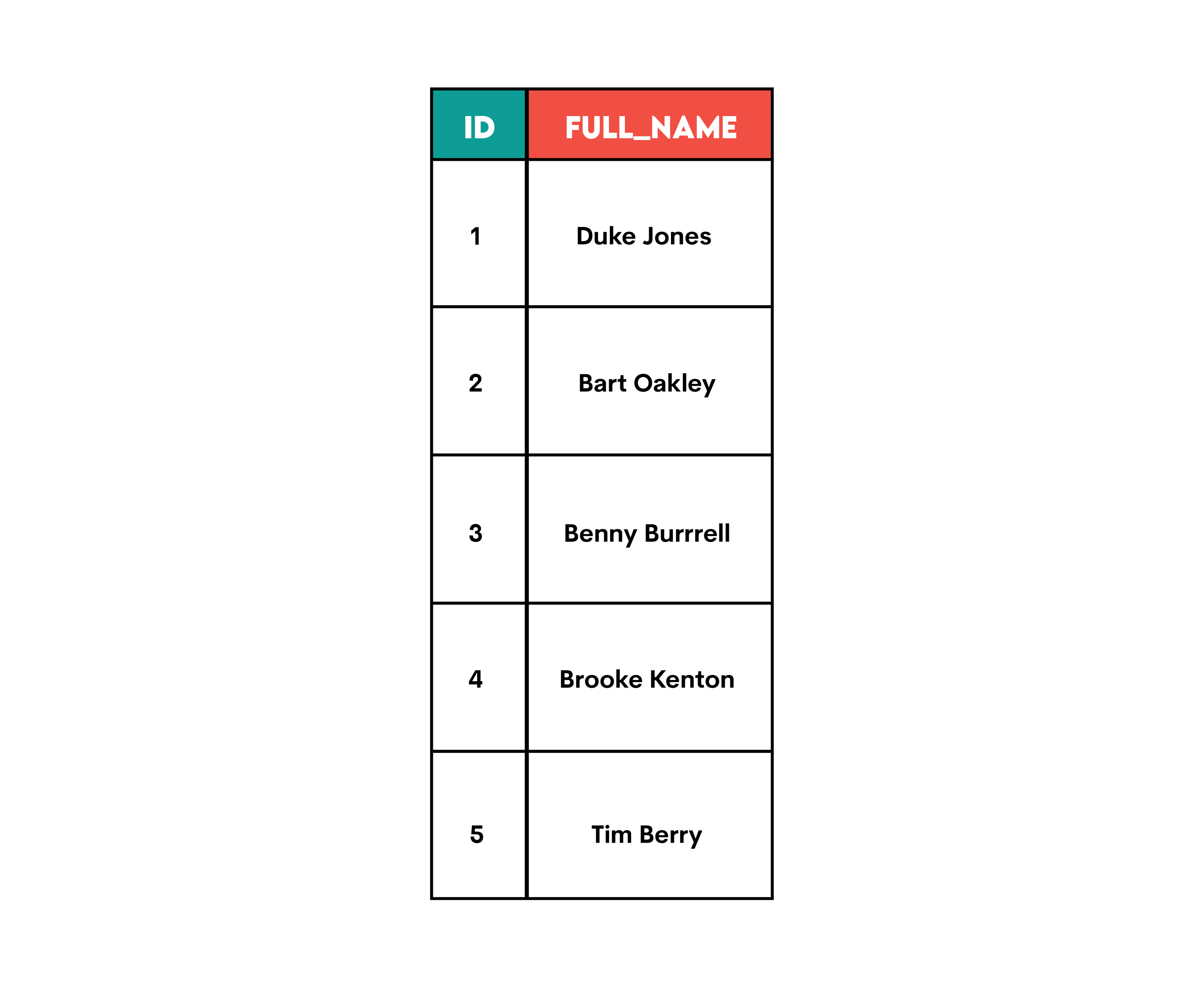
What we did above in CONCAT() is merge three strings. Three? Yes, three: the first name, a whitespace (in the single quotes), and the last name.
Common Use Cases for CONCAT() in SQL
CONCAT() is used in these SQL statements:
- SELECT
- UPDATE
- INSERT
- CASE WHEN
It is also used in these SQL clauses:
- WHERE
- ORDER BY
- GROUP BY
- HAVING
Let’s now talk about the scenarios where CONCAT() is used most commonly.

1. Combining Columns in SELECT Queries
For example, there’s a table named customers.
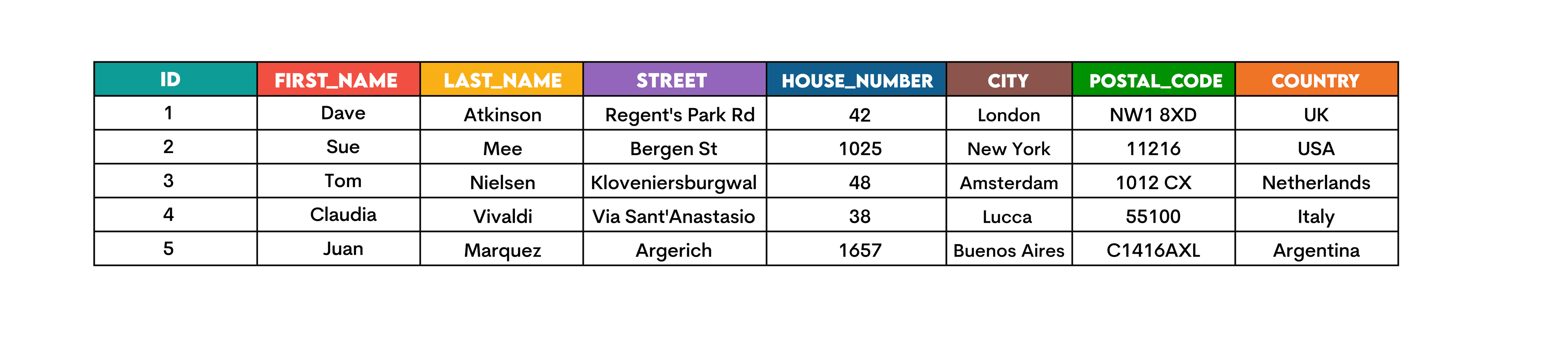
You might want to show customers’ street and house numbers as one string like shown below. The first and last names are separated by whitespace written in single quotes (' ').
SELECT id,
CONCAT(house_number, ' ', street) AS street
FROM customers;
Here’s the output.

Practical Example
This interview question by Amazon and Visa asks you to list the full names of the employees with the highest salaries in one column and their salaries in the other.
Highest Salary & Full Name
Find the employee(s) earning the highest salary. Your output should include two columns: one for the full name of the employee (first and last name combined) and another for their corresponding salary.
Link to the question: https://platform.stratascratch.com/coding/9866-highest-salary-and-full-name
You’re given the worker table.
The solution is simple. Concatenate the employees’ first and last names with the blank space between them (in single quotes). Then find the employees with the highest salary by comparing their salary with the overall highest salary in the WHERE clause.
SELECT CONCAT(first_name, ' ', last_name) AS employee_name,
salary
FROM worker
WHERE salary = (SELECT MAX(salary)
FROM worker);
The output shows two employees with the highest salary, which is 500,000.
| employee_name | salary |
|---|---|
| Jura Jomun | 980000 |
2. Formatting Data for Output
The SQL CONCAT() function is also useful when you want to format data, for example, by combining several columns and adding labels to make the data more readable.
One example is to rework the query above to concatenate all the columns to get customers’ names and shipping addresses in one column. You can also add labels ‘Customer’, ‘Street’, ‘City’, and ‘Country’ in the following way.
You’d concatenate all the columns as shown below. Of course, you want to make the output readable, so leave a whitespace after labels and commas, but also separate the strings directly by having a whitespace in single quotes (' ').
SELECT first_name,
last_name,
CONCAT('Customer: ', first_name, ' ', last_name, ', ', 'Street: ', house_number, ' ', street, ', ', 'City: ', city, ' ', postal_code, ', ', 'Country: ', country) AS shipping_info
FROM customers;
This is what you get, having the data in the column shipping_info formatted the way you want them printed on the packages.

Practical Example
Let’s rework the interview question from the previous example. Imagine that, in addition to employees' names in one column, you also need to show the date they joined the company and their department.
Here’s how you could do it. Amend the previous code by adding the columns joining_date and department. To make all this more readable, add labels in front of those columns, namely 'joined: ' and 'department: '. Also, separate each piece of data with a comma and a blank space behind it.
SELECT CONCAT(first_name, ' ', last_name, ', ', 'joined: ', joining_date, ', ', 'department: ', department) AS employee_name,
salary
FROM worker
WHERE salary = (SELECT MAX(salary)
FROM worker);
Here’s the output.
| employee_name | salary |
|---|---|
| Jura Jomun | 980000 |
3. Creating Composite Keys
Concatenation in SQL is also used when you want to create composite keys, i.e., a combination of multiple columns that will uniquely identify a data row.
For example, you’re working with a hotel booking dataset named booking.
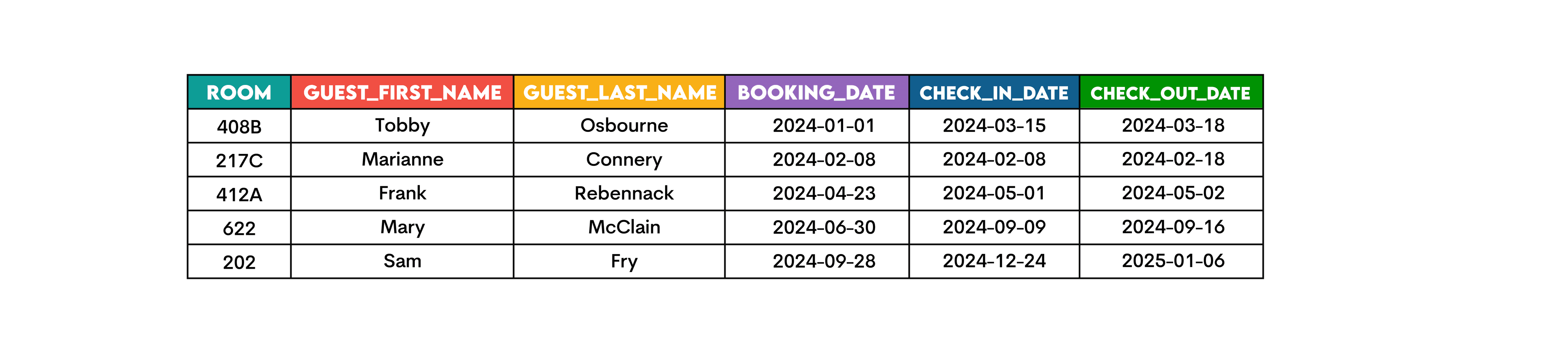
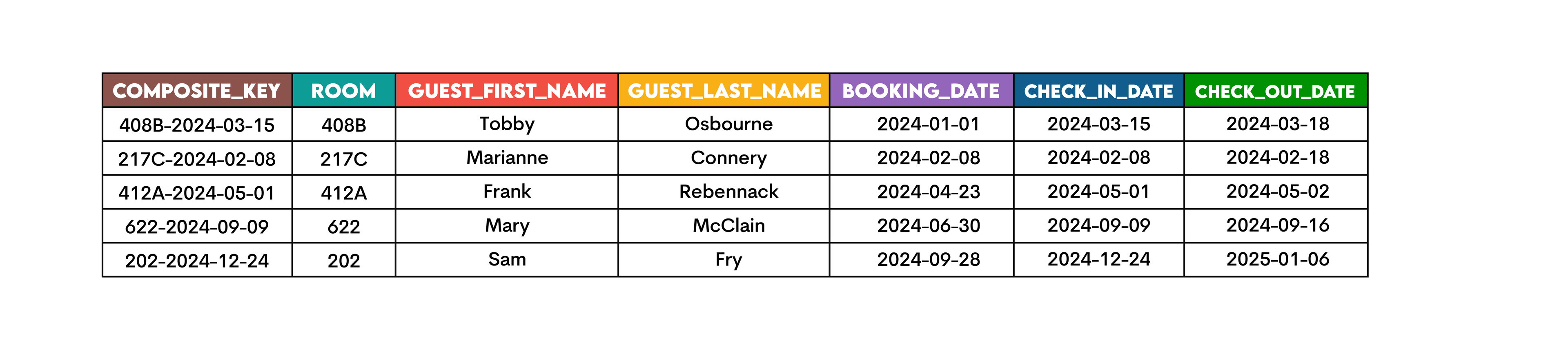
You want to create a composite key out of the room number and the check-in date to make sure no double bookings were made for the same room for the same check-in day.
To do that, use CONCAT() to concatenate the columns room and check_in_date with a hyphen.
SELECT CONCAT(room, '-', check_in_date) AS composite_key,
room,
guest_first_name,
guest_last_name,
booking_date,
check_in_date,
check_out_date
FROM bookings;
This is the output.
Practical Example
Here’s a question from Amazon and ActiveCampaign interviews.
Marketing Campaign Success [Advanced]
You have the marketing_campaign table, which records in-app purchases by users. Users making their first in-app purchase enter a marketing campaign, where they see call-to-actions for more purchases. Find how many users made additional purchases due to the campaign's success.
The campaign starts one day after the first purchase. Users with only one or multiple purchases on the first day do not count, nor do users who later buy only the same products from their first day.
Link to the question: https://platform.stratascratch.com/coding/514-marketing-campaign-success-advanced
We’ll rework the question slightly. Instead of finding the number of users who made additional in-app purchases due to the marketing campaign's success, we’ll list users' IDs, list the products they purchased, and create a composite key of those two values to uniquely identify each purchase.
Other criteria from the question remain the same, i.e., the list should include only purchases after the initial purchase and products that were not purchased on the first date.
Here’s the table marketing_campaign we’ll work with.
The code is more complex and includes several subqueries. Let’s start from the main SELECT and build the solution from there on.
We select the columns we need – user_id and product_id – from the table marketing_campaign. In addition, we use CONCAT() to create a composite key by concatenating user and product IDs with an underscore between them.
SELECT mc.user_id,
mc.product_id,
CONCAT(mc.user_id, '_', mc.product_id) AS user_product
FROM marketing_campaign mc;
Here’s the partial output of the code so far.
| user_id | product_id | user_product |
|---|---|---|
| 10 | 101 | 10_101 |
| 10 | 119 | 10_119 |
| 10 | 111 | 10_111 |
| 11 | 105 | 11_105 |
| 11 | 120 | 11_120 |
Next, we write a subquery in WHERE, which will return only users who made more than one initial purchase and purchased more than one product, which is the criteria given by the question.
SELECT mc.user_id,
mc.product_id,
CONCAT(mc.user_id, '_', mc.product_id) AS user_product
FROM marketing_campaign mc
WHERE mc.user_id IN
(SELECT user_id
FROM marketing_campaign
GROUP BY user_id
HAVING COUNT(DISTINCT created_at) > 1
AND COUNT(DISTINCT product_id) > 1)
In addition to these two requirements, one also tells us to show only products purchased after the initial purchase date.
It means having additional filtering criteria in WHERE, which will look for the user_product composite keys (created the same way as earlier) that are not returned by yet another subquery. That subquery uses RANK() to rank the orders for each user from the oldest to the latest. The purchases on the first date will be ranked as first, so we’ll use WHERE to exclude all other purchases. In addition, we again create a composite key.
So, overall, this part of the code returns the data about the products purchased after the first purchase by looking for the composite keys that are not returned by the query, meaning they are not ranked as one, meaning they show purchases of the product after the initial purchase.
AND CONCAT(mc.user_id, '_', mc.product_id) NOT IN
(SELECT user_product
FROM
(SELECT *,
RANK() OVER (PARTITION BY user_id ORDER BY created_at) AS rn,
CONCAT(user_id, '_', product_id) AS user_product
FROM marketing_campaign) x
WHERE rn = 1)
Put everything together, group the output by the user and product IDs, and the final code looks like this.
SELECT mc.user_id,
mc.product_id,
CONCAT(mc.user_id, '_', mc.product_id) AS user_product
FROM marketing_campaign mc
WHERE mc.user_id IN
(SELECT user_id
FROM marketing_campaign
GROUP BY user_id
HAVING COUNT(DISTINCT created_at) > 1
AND COUNT(DISTINCT product_id) > 1
)
AND CONCAT(mc.user_id, '_', mc.product_id) NOT IN
(SELECT user_product
FROM (SELECT *,
RANK() OVER (PARTITION BY user_id ORDER BY created_at) AS rn,
CONCAT(user_id, '_', product_id) AS user_product
FROM marketing_campaign
) x
WHERE rn = 1
)
GROUP BY mc.user_id, mc.product_id;
Here are the first several rows of the final output.
| count |
|---|
| 23 |
Advanced Techniques for Efficient SQL Concatenation
In the following part, I will cover techniques you should consider for efficient concatenation in SQL.

1. Using CONCAT() With NULL Values in SQL
If your data contains NULLs, how would CONCAT() handle them? The answer is that CONCAT() automatically treats NULL as an empty string.
For example, if you have this code…
SELECT id,
CONCAT(first_name, ' ', last_name) AS full_name
FROM employees;
… and this data in the table…
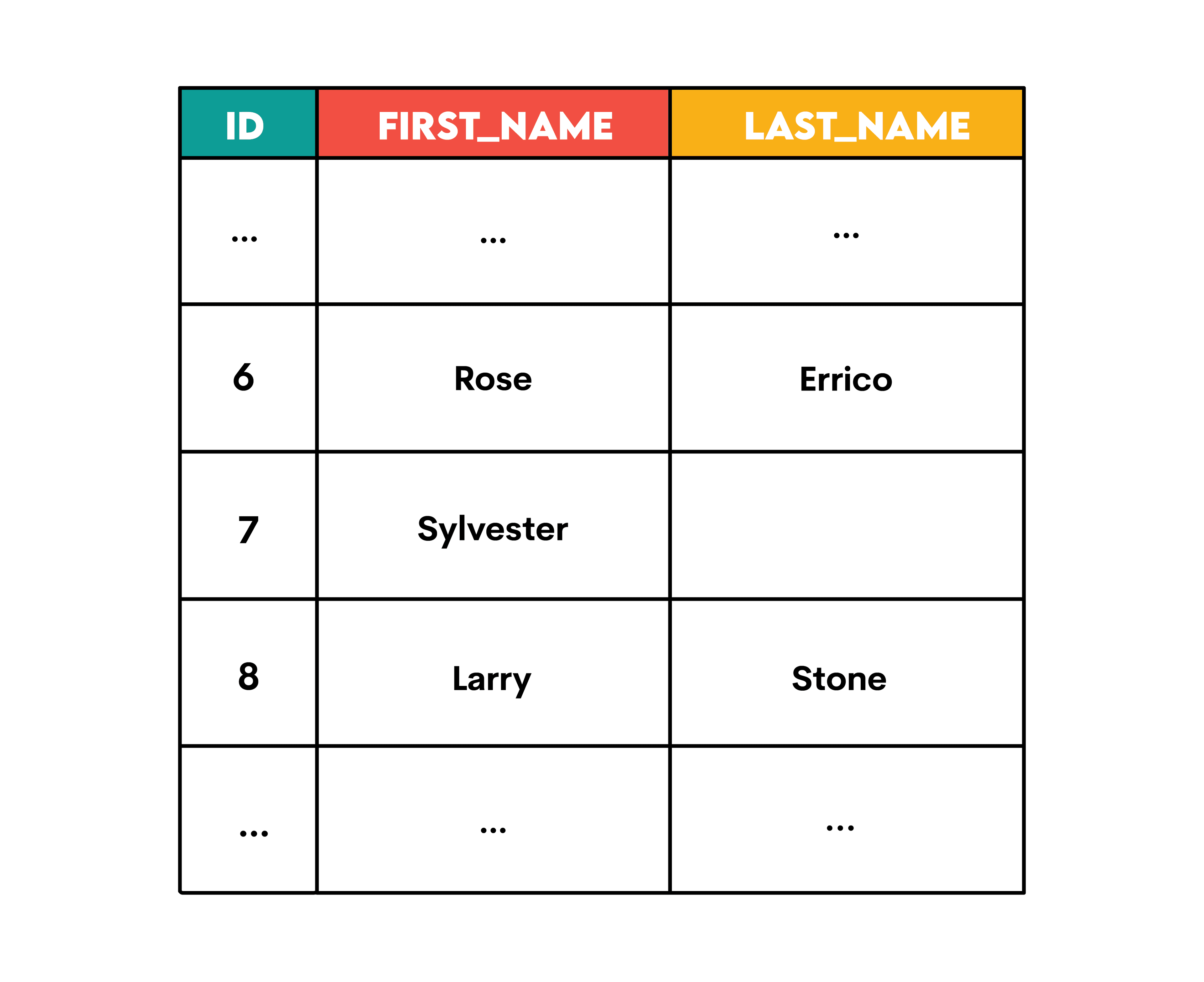
… the output will be this one.
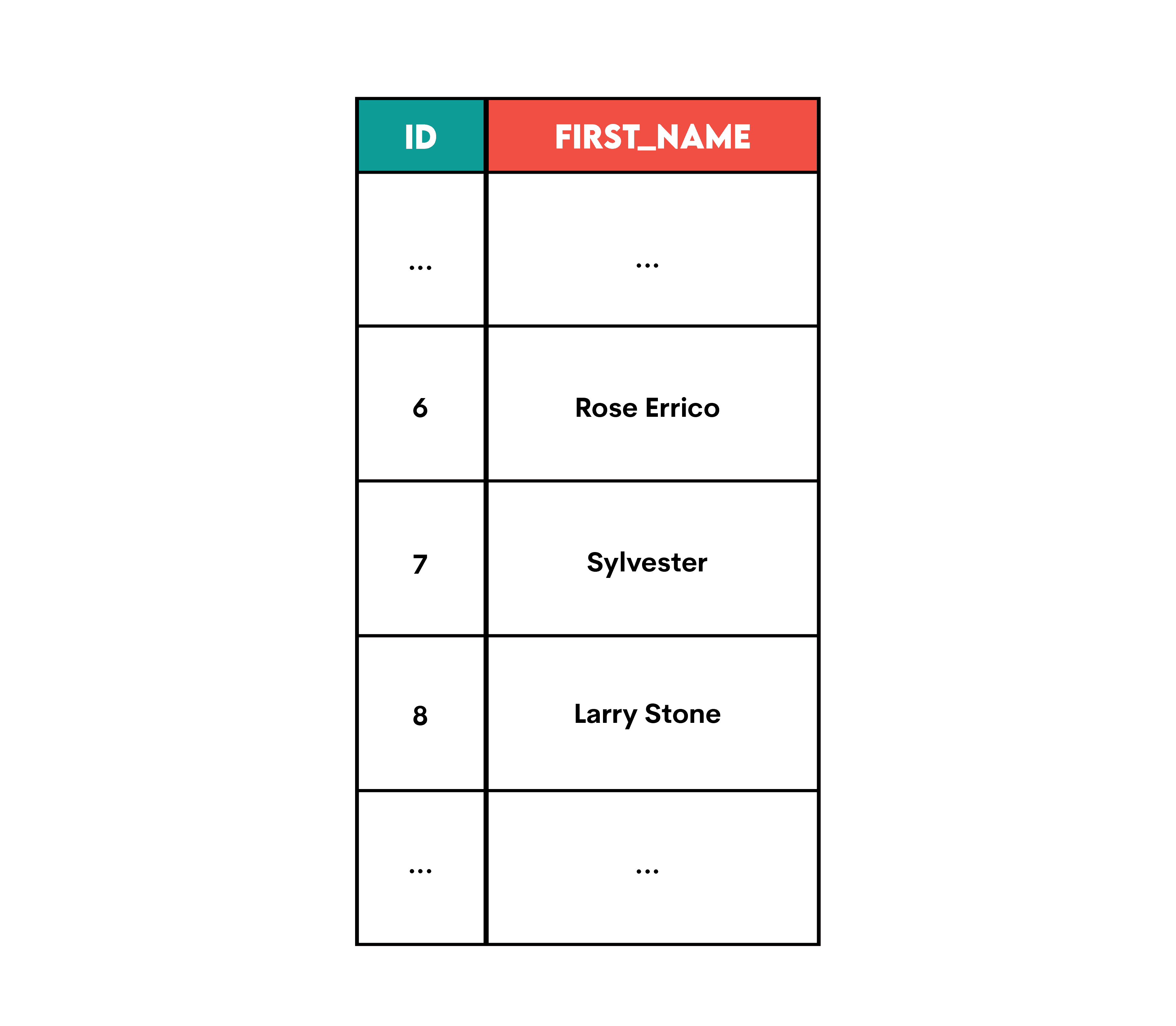
In other words, CONCAT() will concatenate and return whatever data it has, be it only the first or the last name.
Practical Example
Here’s a question by Google.
User with Most Approved Flags
Last Updated: April 2022
Which user flagged the most distinct videos that ended up approved by YouTube? Output, in one column, their full name or names in case of a tie. In the user's full name, include a space between the first and the last name.
Link to the question: https://platform.stratascratch.com/coding/2104-user-with-most-approved-flags
We’ll change the requirements slightly. Instead of finding the users who flagged the highest number of unique videos that ended up being approved by YouTube, we’ll look for the users who flagged the lowest number of videos and also those that have yet to be reviewed by YouTube.
The output requirements stay the same, i.e., we’ll show users’ full names with a space between the first and the last name.
We are provided with two tables; the first one is user_flags.
The second table is flag_review.
The most complex part of the code is the subquery, so let’s start with it. In the subquery, we join two tables on the flag_id column.
Then, we concatenate users’ first and last names with the space between them, just like the question asks. After that, we use DENSE_RANK() – you can also use RANK() – to rank data by the number of distinct flagged videos from the lowest to the highest number. In the WHERE clause, we include only data where the reviewed outcome is NULL, i.e., YouTube hasn’t yet reviewed the video. As the last step, the output is grouped by the username column.
SELECT CONCAT(uf.user_firstname, ' ', uf.user_lastname) AS username,
DENSE_RANK() OVER (ORDER BY COUNT(DISTINCT video_id) ASC) AS rn
FROM user_flags AS uf
INNER JOIN flag_review AS fr ON uf.flag_id = fr.flag_id
WHERE lower(fr.reviewed_outcome) IS NULL
GROUP BY username
The output shows all the users whose flagged videos still need to be reviewed and their rank according to the number of videos they flagged.
| username |
|---|
| Mark May |
| Richard Hasson |
Now, the only thing that remains is to select the username in the main query and leave only those users ranked first. Why? Because those are the ones with the least flagged videos.
SELECT username
FROM
(SELECT CONCAT(uf.user_firstname, ' ', uf.user_lastname) AS username,
DENSE_RANK() OVER (ORDER BY COUNT(DISTINCT video_id) ASC) AS rn
FROM user_flags AS uf
INNER JOIN flag_review AS fr ON uf.flag_id = fr.flag_id
WHERE lower(fr.reviewed_outcome) IS NULL
GROUP BY username
) AS sq
WHERE rn = 1;
Here’s the output. You can see that two usernames contain only the last name. This means that the column first_name was NULL for those users, which confirms that COALESCE() treats it as an empty string.
2. Performance Considerations
CONCAT() can slow down your queries, especially if you run them on large datasets. The main approach for optimizing query performance is to index columns that will be concatenated often. In addition, avoid using CONCAT() in WHERE, as it prevents the database from using indexes properly.
3. Concatenating With Functions and Expressions
CONCAT() in SQL can be used with other functions, like arithmetic, date, or string functions.
For example, this code…
SELECT CONCAT(first_name, ' ', UPPER(last_name), ' - Joined: ', YEAR(join_date)) AS employee_info
FROM employees;
…employs CONCAT() with UPPER() to format the last name in uppercase and YEAR() to show only the year of joining, not the whole date.
Practical Example
Let’s look at this question by Wine Magazine.
Top 3 Wineries In The World
Last Updated: March 2020
Find the top 3 wineries in each country based on the average points earned. In case there is a tie, order the wineries by winery name in ascending order. Output the country along with the best, second best, and third best wineries. If there is no second winery (NULL value) output 'No second winery' and if there is no third winery output 'No third winery'. For outputting wineries format them like this: "winery (avg_points)"
Link to the question: https://platform.stratascratch.com/coding/10042-top-3-wineries-in-the-world
The question wants you to find the top three wineries by country based on the average points earned. The output of the wineries should be formatted as “winery(avg_points)”.
You’re given the table winemag_p1.
The solution consists of several subqueries. The first subquery calculates the average points for each winery in each country. It excludes all the data where the country is NULL.
SELECT country,
winery,
AVG(points) AS avg_points
FROM winemag_p1
WHERE country IS NOT NULL
GROUP BY country, winery
Here are the first few rows of the subquery’s output.
| country | winery | avg_points |
|---|---|---|
| Portugal | Messias | 84 |
| US | Capture | 86 |
| Turkey | Camlibag | 86 |
| Argentina | Caligiore | 82 |
| US | Byington | 83 |
That subquery is then used in yet another subquery, which ranks wineries in each country based on the average points. I use the ROW_NUMBER() window function – you can also use RANK() or DENSE_RANK(), it doesn’t really matter here – to do it, as I partition the dataset by country, and rank by the average points descendingly and by winery name ascendingly. The latter is a question requirement, as it wants wineries ordered alphabetically in case of ties.
Put together these two subqueries…
(SELECT country,
winery,
ROW_NUMBER() OVER (PARTITION BY country ORDER BY avg_points DESC, winery ASC) AS position,
avg_points
FROM
(SELECT country,
winery,
AVG(points) AS avg_points
FROM winemag_p1
WHERE country IS NOT NULL
GROUP BY country, winery
) tmp1
) tmp2
…and you get the (partial) output looking like this.
| country | winery | position | avg_points |
|---|---|---|---|
| Argentina | Bodega Noemaa de Patagonia | 1 | 89 |
| Argentina | Bodega Norton | 2 | 86 |
| Argentina | Rutini | 3 | 86 |
| Argentina | Finca El Origen | 4 | 84 |
| Argentina | Bodegas La Guarda | 5 | 83 |
Now, you need to add the third subquery, which uses the second subquery in FROM. It selects the top three wineries for each country and formats the output.
The selection of the top three wineries is achieved by using the CASE WHEN statements. Each case statement looks for one winery rank (the first, second, or third) and returns the winery name and average score rounded to the nearest integer.
You can do that because of the CONCAT() function. Concatenate the columns winery and avg_point while also using the ROUND() function to round the points and show them in the brackets.
In the WHERE clause, include only the first three positions in the output.
The code looks like this so far.
(SELECT country,
CASE
WHEN POSITION = 1 THEN CONCAT(winery, ' (', ROUND(avg_points), ')')
ELSE NULL
END AS top_winery,
CASE
WHEN POSITION = 2 THEN CONCAT(winery, ' (', ROUND(avg_points), ')')
ELSE NULL
END AS second_winery,
CASE
WHEN POSITION = 3 THEN CONCAT(winery, ' (', ROUND(avg_points), ')')
ELSE NULL
END AS third_winery
FROM
(SELECT country,
winery,
ROW_NUMBER() OVER (PARTITION BY country ORDER BY avg_points DESC, winery ASC) AS position,
avg_points
FROM
(SELECT country,
winery,
AVG(points) AS avg_points
FROM winemag_p1
WHERE country IS NOT NULL
GROUP BY country, winery
) tmp1
) tmp2
WHERE POSITION <= 3
) tmp3
The partial output of the code so far is shown below.
| country | top_winery | second_winery | third_winery |
|---|---|---|---|
| Argentina | Bodega Noemaa de Patagonia (89) | ||
| Argentina | Bodega Norton (86) | ||
| Argentina | Rutini (86) | ||
| Australia | Madison Ridge (84) | ||
| Austria | Schloss Gobelsburg (93) |
You can now write the main SELECT statement. You need to transform the above output so each country is shown only once, and their top three wineries are shown in that one row under the belonging column. To do that, use the MAX() aggregate function to select the top winery from the subqueries. By using the aggregate functions that way, you don’t need to include the columns with winery names in GROUP BY so that you can show all three wineries in one output row.
In addition, use COALESCE() to output ‘No second winery’ or ‘No third winery’ in case of NULLs, which is the question’s requirement.
The final solution is this.
SELECT country,
MAX(top_winery) AS top_winery,
COALESCE(MAX(second_winery), 'No second winery') AS second_winery,
COALESCE(MAX(third_winery), 'No third winery') AS third_winery
FROM
(SELECT country,
CASE
WHEN POSITION = 1 THEN CONCAT(winery, ' (', ROUND(avg_points), ')')
ELSE NULL
END AS top_winery,
CASE
WHEN POSITION = 2 THEN CONCAT(winery, ' (', ROUND(avg_points), ')')
ELSE NULL
END AS second_winery,
CASE
WHEN POSITION = 3 THEN CONCAT(winery, ' (', ROUND(avg_points), ')')
ELSE NULL
END AS third_winery
FROM
(SELECT country,
winery,
ROW_NUMBER() OVER (PARTITION BY country ORDER BY avg_points DESC, winery ASC) AS position,
avg_points
FROM
(SELECT country,
winery,
AVG(points) AS avg_points
FROM winemag_p1
WHERE country IS NOT NULL
GROUP BY country, winery
) tmp1
) tmp2
WHERE position <= 3
) tmp3
GROUP BY country;
Here’s the output.
| country | top_winery | second_winery | third_winery |
|---|---|---|---|
| Argentina | Bodega Noemaa de Patagonia (89) | Bodega Norton (86) | Rutini (86) |
| Australia | Madison Ridge (84) | No second winery | No third winery |
| Austria | Schloss Gobelsburg (93) | Hopler (83) | No third winery |
| Bulgaria | Targovishte (84) | No second winery | No third winery |
| Chile | Altaa¸r (85) | Francois Lurton (85) | Santa Carolina (85) |
| France | Domaine Faiveley (94) | Roche de Bellene (92) | Alain Jaume et Fils (89) |
| Germany | Maximin Granhauser (92) | Bollig-Lehnert (91) | A. Christmann (89) |
| Greece | Santo Wines (90) | No second winery | No third winery |
| Italy | Roagna (93) | Il Mosnel (91) | Ca' du RabajaŠ (90) |
| Moldova | Vinaria din Vale (88) | No second winery | No third winery |
| New Zealand | Peregrine (90) | Catalina Sounds (88) | Dashwood (87) |
| Portugal | Aveleda (91) | Quinta do Boicao (89) | Messias (84) |
| South Africa | The Berrio (87) | No second winery | No third winery |
| Spain | Jaspi (87) | Atalayas de Golba?n (85) | Grandes Vinos y Vinedos (85) |
| Turkey | Camlibag (86) | No second winery | No third winery |
| US | Niebaum-Coppola (97) | Yao Ming (97) | Joseph Phelps (96) |
Database-Specific Variations
I’ll now walk you through the specifics of concatenation in the four most common SQL dialects.
1. Syntax and Features of CONCAT() in MySQL
CONCAT() is the only way to concatenate in MySQL, with the syntax the same as the one shown at the beginning of the article. The NULL values are treated as empty strings.
2. Syntax and Features of CONCAT() in SQL Server
SQL Server, too, supports CONCAT(), with the syntax and the NULL treatment the same as in MySQL.
In addition, SQL Server supports the + operator for concatenation with the following syntax.
string1 + string2 + … +, stringN
However, this concatenation method treats NULLs differently. If one string is NULL, the whole concatenation output becomes NULL.
3. Syntax and Features of CONCAT() in PostgreSQL
CONCAT() in PostgreSQL is the same as in the previous two SQL flavors.
In addition, PostgreSQL supports the || operator, a standard SQL operator for concatenation. Its syntax is shown below.
string1 || string2 || … || stringN
With this method, if one string is NULL, the output becomes NULL, too.
4. Syntax and Features of CONCAT() in Oracle
There are no features of CONCAT(), as that function doesn’t exist in Oracle. The only concatenation method is the standard one – the || operator – with the same syntax as in PostgreSQL.
Like in PostgreSQL, NULLs are contagious: one NULL results in the whole output being NULL.
Best Practices of Using SQL CONCAT()
There are several best practices to follow when using CONCAT().

1. Handling NULL Values Properly
Be aware of NULLs in your data. Use functions like COALESCE() or IFNULL() to replace NULLs with custom strings. With CONCAT(), this is only for the output customization. However, with the + and || operators, handling NULLs explicitly becomes necessary if you want to output anything other than only NULLs.
2. Minimize Concatenation in WHERE
This is something we already mentioned. Concatenating in WHERE prevents databases from using indexes efficiently, so it’s best avoided, especially with large datasets.
3. Combine With Other Functions
Leverage the possibility of using CONCAT() with other functions. For example, SUBSTRING(), UPPER(), LOWER(), or ROUND().
4. Be Aware of the Database Specifics
You should know whether your database supports CONCAT(). If it does, are there also alternative concatenation ways, and if so, do they behave differently than CONCAT()? If there’s no CONCAT(), then how can you concatenate values?
The answer to all these questions is given in the previous section.
Conclusion
It is quite a long article, but learning SQL CONCAT() asks for it. We managed to cover many important topics:
- CONCAT() syntax
- Common CONCAT() uses
- Advanced CONCAT() techniques
All this is supported by practical examples. In addition, we also discussed the concatenation best practices.
Now, to turn all this into coherent knowledge, try solving some more StrataScratch analytical coding questions that require CONCAT().
Share