Assignment Solutions: Basic SQL 2


Categories:
 Written by:
Written by:Nathan Rosidi
The explanations and solutions for answering the question in the Assignment: Basic SQL 2.
In the continuation of our Basic SQL 1 assignment, the Basic SQL 2 tested your SQL knowledge in a similar form. If you want to compare your solutions with the official ones and learn something through our code explanations, you’re in the right place.
JOINs
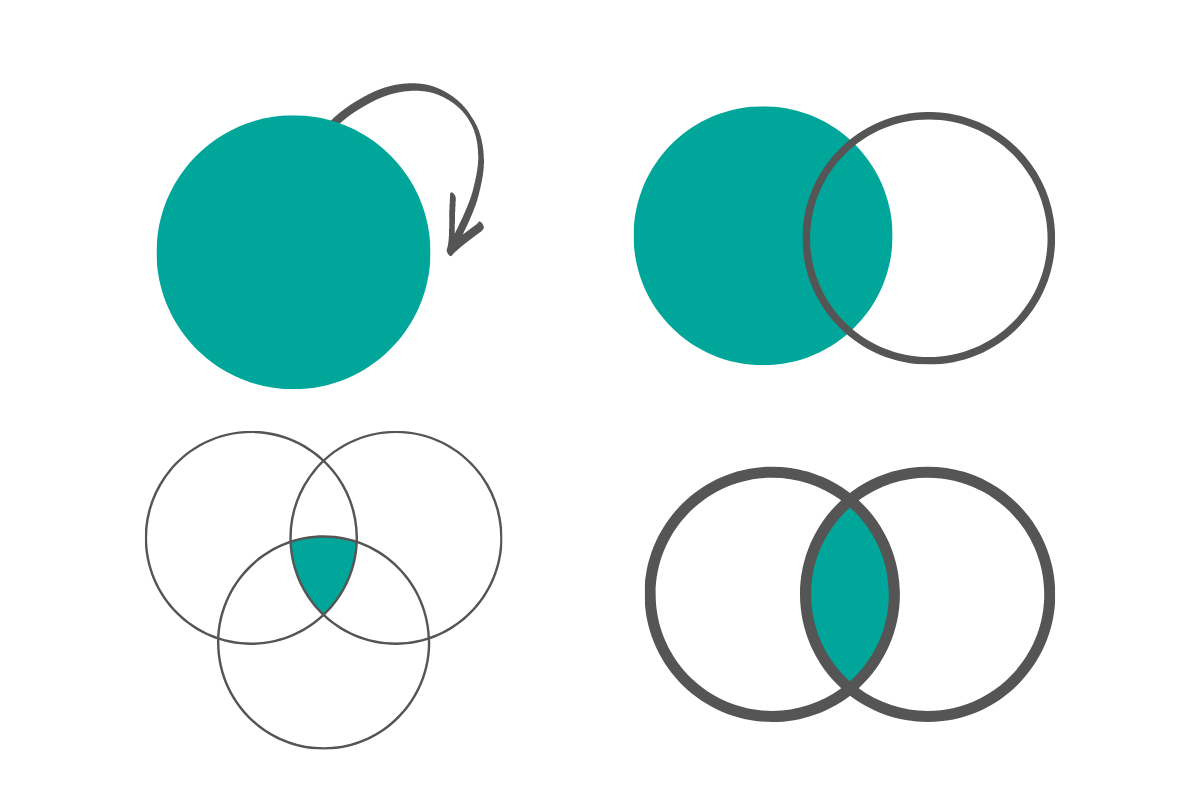
The JOIN keyword in SQL is used for joining two or more tables on a common column. That way, you’re able to use data from multiple tables, not just one.
Here’s an overview of the five distinct JOIN types in SQL.
| JOIN type | Description |
| (INNER) JOIN | Returns only matching rows from the joined tables. |
| LEFT (OUTER) JOIN | Returns all the rows from the first (left) table and only the matching rows from the second (right) table. |
| RIGHT (OUTER) JOIN | Opposite of the LEFT JOIN: Returns all the rows from the second (right) table and only the matching rows from the first (left) table. |
| FULL OUTER JOIN | Returns all the rows (matched and unmatched) from all the tables. |
| CROSS JOIN | Returns a Cartesian product: the combination of each row from the first table with each row from the second table. |
When there are unmatched rows in one of the joined tables, the rows will have the NULL values. You can get more information in the article about joining three or more tables and also in our SQL cheat sheet.
Question 1
Find Nexus5 control group users in Italy who don't speak Italian
“Find user id, language, and location of all Nexus 5 control group users in Italy who do not speak Italian. Sort the results in ascending order based on the occured_at value of the playbook_experiments dataset.”
Link to the question: https://platform.stratascratch.com/coding/9609-find-nexus5-control-group-users-in-italy-who-dont-speak-italian
Data
There are two tables available: playbook_experiments and playbook_users.
Table: playbook_experiments
| user_id | int |
| occurred_at | datetime |
| experiment | varchar |
| experiment_group | varchar |
| location | varchar |
| device | varchar |
Here’s the data from the table.

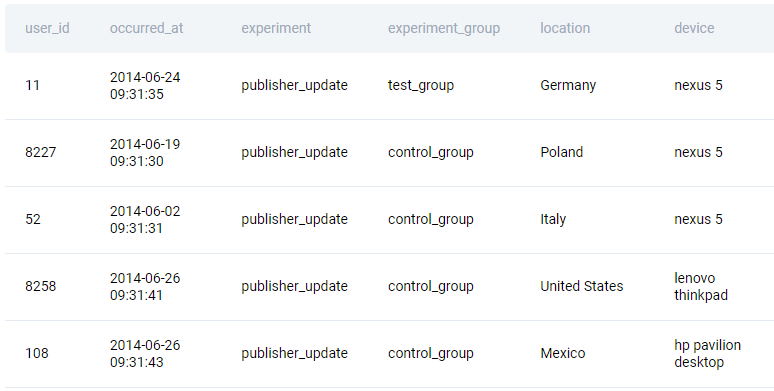
Table: playbook_users
| user_id | int |
| created_at | datetime |
| company_id | int |
| language | varchar |
| activated_at | datetime |
| state | varchar |
The data is shown below.

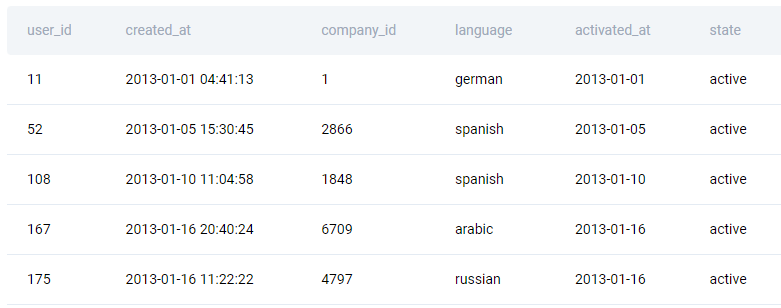
Solution
To solve this question, you will need to join both tables. In doing that, use the INNER JOIN statement. How to join tables? Write the name of the first table in the FROM clause and give it an alias to make writing a code easier. It is followed by the INNER JOIN statement and the second table.
The ON keyword indicates the columns from the first and second tables that are used for joining them.
After joining tables, you need to set the criteria stated in the question. Use the WHERE clause to find the users from Italy who belong to the control group, don’t speak Italian, and are using Nexus 5.
In the end, sort the output from the oldest to the newest date.
SELECT usr.user_id,
usr.language,
exp.location
FROM playbook_experiments exp
INNER JOIN playbook_users usr ON exp.user_id = usr.user_id
WHERE exp.device = 'nexus 5'
AND exp.experiment_group = 'control_group'
AND exp.location = 'Italy'
AND usr.language <> 'italian'
ORDER BY exp.occurred_at ASC;
The code will output four rows.

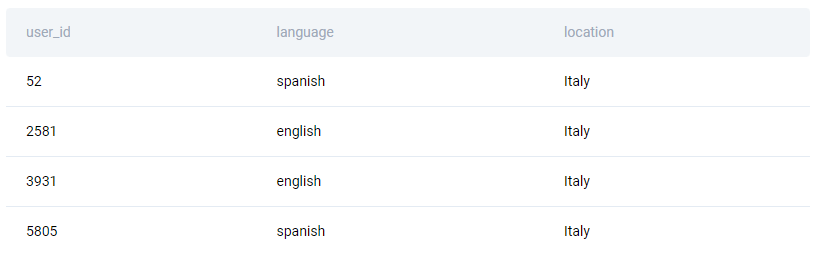
Question 2
SMS Confirmations From Users
“Meta/Facebook sends SMS texts when users attempt to 2FA (2-factor authenticate) into the platform to log in. In order to successfully 2FA they must confirm they received the SMS text message. Confirmation texts are only valid on the date they were sent. Unfortunately, there was an ETL problem with the database where friend requests and invalid confirmation records were inserted into the logs, which are stored in the 'fb_sms_sends' table. These message types should not be in the table. Fortunately, the 'fb_confirmers' table contains valid confirmation records so you can use this table to identify SMS text messages that were confirmed by the user.
Calculate the percentage of confirmed SMS texts for August 4, 2020.”
Link to the question: https://platform.stratascratch.com/coding/10291-sms-confirmations-from-users
Data
There are again two tables at your disposal.
Table: fb_sms_sends
| ds | datetime |
| country | varchar |
| carrier | varchar |
| phone_number | int |
| type | varchar |
The sample of data from the table is as follows.

Table: fb_confirmers
| date | datetime |
| phone_number | int |
Here’s the data from the second table.

Solution
From the way the question is formulated, you should know that the solution will require using the LEFT JOIN. Why is that? Because the invalid confirmation records appear in the table fb_sms_sends, while they don’t appear in the table fb_confirmers.
SELECT COUNT(b.phone_number)::float / COUNT(a.phone_number) * 100 AS perc
FROM fb_sms_sends a
LEFT JOIN fb_confirmers b ON a.ds = b.date
AND a.phone_number = b.phone_number
WHERE a.ds = '08-04-2020'
AND a.type = 'message';
To calculate the percentage of the confirmed SMS texts divide the count of the phone numbers from fb_confirmers with the count of the phone numbers from the table fb_sms_sends and multiply by 100. Also, convert the integer data type of the phone number into a float by using the PostgreSQL shorthand for the CAST() function.
The tables are joined on two pairs of columns: ds and date, and the phone_number column from both tables.
Filter data by using the WHERE clause. The conditions are: SMS texts are for 4 August 2020, and the type is 'message'.
The solution will output only one value.


Question 3
DeepMind employment competition
“Find the winning teams of DeepMind employment competition.
Output the team along with the average team score.
Sort records by the team score in descending order.”
Link to the question: https://platform.stratascratch.com/coding/10070-deepmind-employment-competition
Data
The question gives you two little tables, both with two columns.
Table: google_competition_participants
| member_id | int |
| team_id | int |
Here are the first five rows from the table.

Table: google_competition_scores
| member_id | int |
| member_score | float |
The first five rows from this table are below, too.

Solution
You’ll have to use the aggregate function in this question, too. This time it's the AVG() function for calculating the average team score. The two tables are joined using the INNER JOIN on the column member_id.
To get the average team score and the team’s ID, group the output by the column team_id. Finally, sort data from the highest average team score to the lowest.
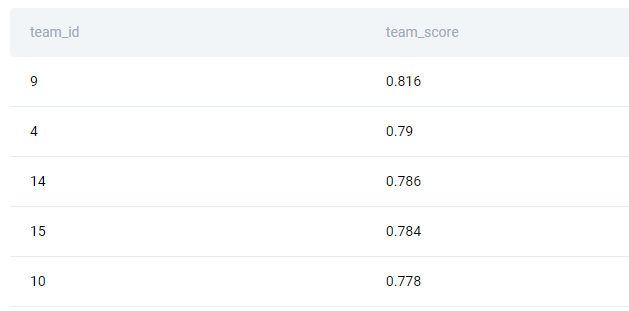
SELECT p.team_id,
AVG(s.member_score) AS team_score
FROM google_competition_participants p
INNER JOIN google_competition_scores s ON p.member_id = s.member_id
GROUP BY p.team_id
ORDER BY team_score DESC;
Again, there are only five rows out of much more appearing in the output.

Question 4
Finding User Purchases
“Write a query that'll identify returning active users. A returning active user is a user that has made a second purchase within 7 days of any other of their purchases. Output a list of user_ids of these returning active users.”
Link to the question: https://platform.stratascratch.com/coding/10322-finding-user-purchases
Data
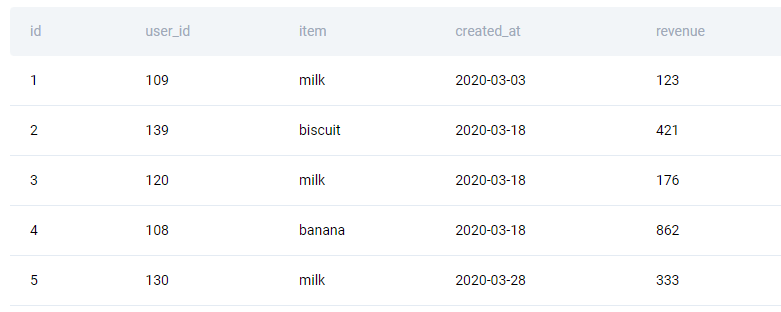
There’s only one table for solving this problem. It’s named amazon_transactions.
| id | int |
| user_id | int |
| item | varchar |
| created_at | datetime |
| revenue | int |
Here are the first few rows from the table.

Solution
You might wonder what this question is doing in the JOINs section having only one table. There’s a reason: you can join a table with itself. It’s called self-joining, and that’s exactly what you’ll have to do to answer the question.
The self-join is not a distinct type of JOIN; any JOIN type can be used to join the table with itself. You can see in the below solution how this is done. Name the table in the FROM clause and give it an alias. After the JOIN statement, write the table’s name again. This time, give it another alias. That way, you’ll be able to treat one table as two tables. The tables are joined on the column user_id. To make sure there was a second purchase by the same user, also join tables where the columns id are not equal. The second purchase needs to be made within seven days, so the tables have also to be joined where the difference between the purchase creation dates is between zero and seven.
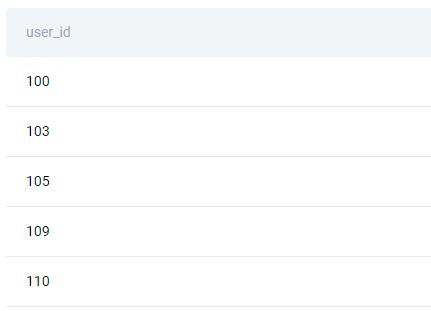
SELECT DISTINCT(a1.user_id)
FROM amazon_transactions a1
JOIN amazon_transactions a2 ON a1.user_id=a2.user_id
AND a1.id <> a2.id
AND a2.created_at::date-a1.created_at::date BETWEEN 0 AND 7
ORDER BY a1.user_id;
Here’s a partial list of such users.

Subqueries

A subquery is a query written (or nested) inside the larger query. The result of the subquery will be used by the main query to return the final output.
Subqueries are used in the following SQL statements or clauses.
| Statement/Clause |
| SELECT |
| FROM |
| WHERE |
| HAVING |
| INSERT |
| UPDATE |
| DELETE |
Question 5
Top Cool Votes
“Find the review_text that received the highest number of 'cool' votes.
Output the business name along with the review text with the highest number of 'cool' votes.”
Link to the question: https://platform.stratascratch.com/coding/10060-top-cool-votes
Data
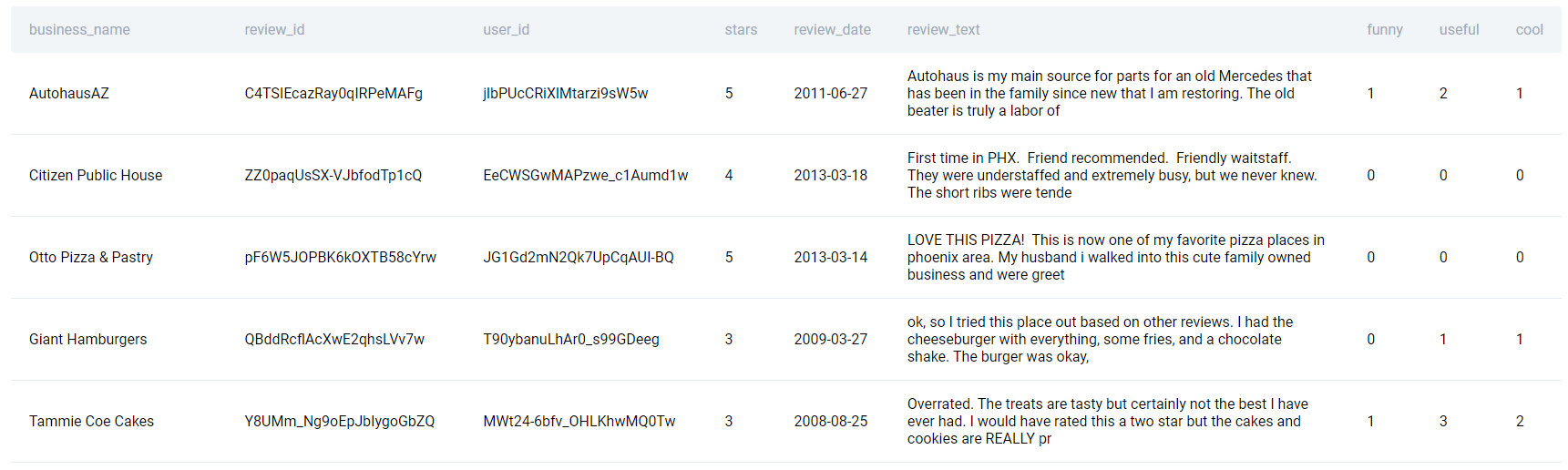
The data for solving the question can be found in the table yelp_reviews.
| business_name |
| review_id |
| user_id |
| stars |
| review_date |
| review_text |
| funny |
| useful |
| cool |
Here’s the sample data.

Solution
Select the business name and the text of the business’s review. Use the WHERE clause to output the businesses whose number of cool votes is equal to the maximum number of the cool votes.
Get that maximum by using the MAX() aggregate function in the subquery.
SELECT business_name,
review_text
FROM yelp_reviews
WHERE cool =
(SELECT MAX(cool)
FROM yelp_reviews);
The code will fetch only two rows.

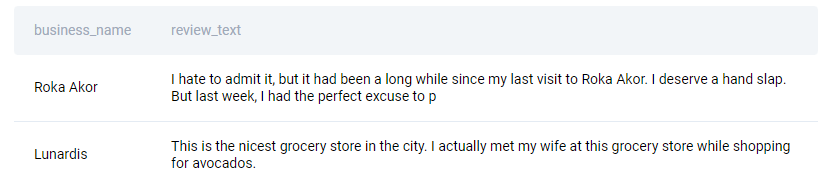
Question 6
Cities With The Most Expensive Homes
“Write a query that identifies cities with higher than average home prices when compared to the national average. Output the city names.”
Link to the question: https://platform.stratascratch.com/coding/10315-cities-with-the-most-expensive-homes
Data
The question gives you the table zillow_transactions.
| id | int |
| state | varchar |
| city | varchar |
| street_address | varchar |
| mkt_price | int |
The sample data is shown below.

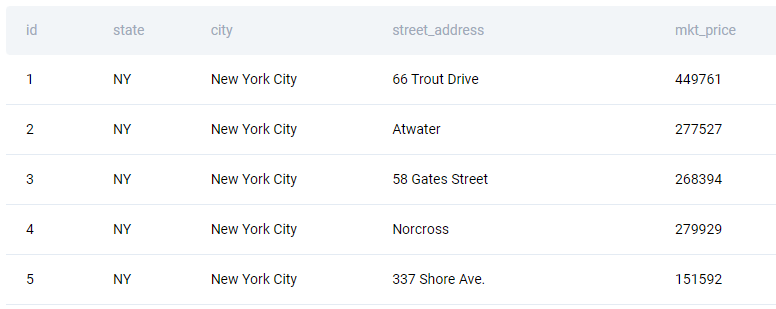
Solution
The subquery in this solution is also used to filter data. This time, it’s in the HAVING, not the WHERE clause. The reason is the filtering needs to be done after the aggregation.
So, after selecting the column city and grouping the output by it comes the filtering. You’ll calculate the average market price in the HAVING clause, which will be the average market price by city.
You need to show only the cities with the average home prices higher than the national average. Calculate the national average using the AVG() function in the subquery.
In the end, sort data alphabetically by city.
SELECT city
FROM zillow_transactions a
GROUP BY city
HAVING AVG(a.mkt_price) >
(SELECT AVG(mkt_price)
FROM zillow_transactions)
ORDER BY city ASC;
There are three cities with the average prices higher than the national average.

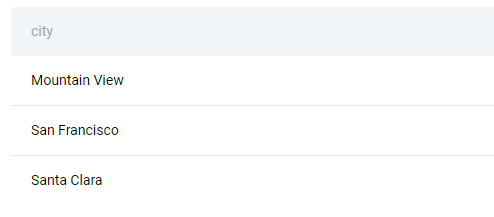
Question 7
Class Performance
“You are given a table containing assignment scores of students in a class. Write a query that identifies the largest difference in total score of all assignments.
Output just the difference in total score between the two students.”
Link to the question: https://platform.stratascratch.com/coding/10310-class-performance
Data
You had to work on the solution using the table box_scores.
| id | int |
| student | varchar |
| assignment1 | int |
| assignment2 | int |
| assignment3 | int |
There’s not plenty of data, so we’ll show it all.

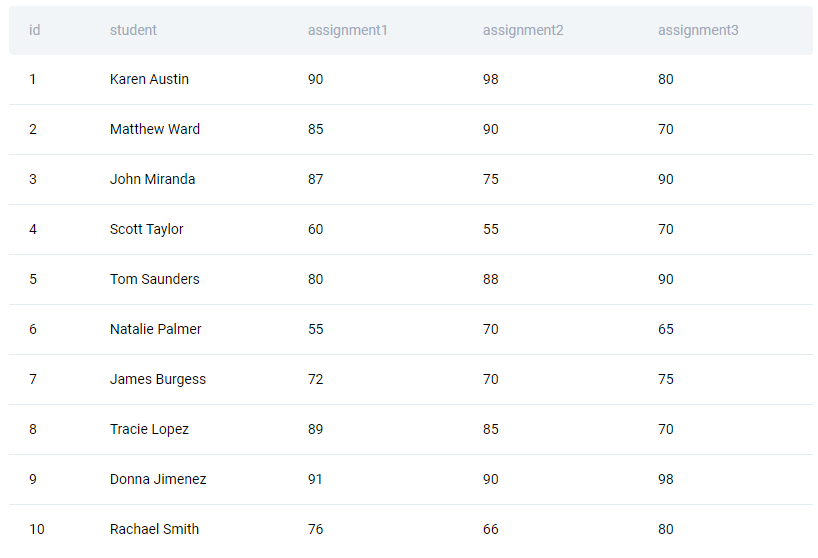
Solution
To find the largest difference in all assignments’ total scores, you need to use the MAX() and MIN() functions, i.e., the difference between them.
But first, you need to sum up the total score for every student. The easiest way to do this is by writing the subquery with the SUM() function in the FROM clause.
The result of this sum will be used in the MAX() and MIN() functions in the main query.
SELECT MAX(score)-MIN(score) AS difference_in_scores
FROM
(SELECT student,
SUM(assignment1+assignment2+assignment3) AS score
FROM box_scores
GROUP BY student) a;
This solution shows that by using the subquery in the FROM clause, you can reference it in the SELECT statement just like any table.
Run the query to output an answer to the question.


Question 8
Email Details Based On Sends
“Find all records from days when the number of distinct users receiving emails was greater than the number of distinct users sending emails.”
Link to the question: https://platform.stratascratch.com/coding/10086-email-details-based-on-sends
Data
The data you’ll be using in this exercise is google_gmail_emails.
| id | int |
| from_user | varchar |
| to_user | varchar |
| day | int |
The example of the data is given below.

Solution
Using the subquery as all other tables in the FROM clause also means the subquery can be joined with a table. This code showcases it.
First, select all the columns from the table. Then join it with a subquery. This subquery is used to calculate the sent/received ratio using the COUNT() function. To get it in decimal format, convert the data type to numeric.
Joining is done where the column day is equal in both table and subquery and also where the sent/received ratio is lower than one.
SELECT g.*
FROM google_gmail_emails g
INNER JOIN
(SELECT day,
COUNT(DISTINCT from_user) :: NUMERIC / COUNT(DISTINCT to_user) AS sent_received_ratio
FROM google_gmail_emails
GROUP BY DAY) base ON g.day = base.day
AND base.sent_received_ratio < 1;
Here’s part of the data comprising the output.

CASE Statement

The CASE statement is an SQL version of the IF-THEN-ELSE logic. It will go through the data, return data that meets the condition(s), and allocate designated value to it. The data that doesn’t meet the condition(s) will get the value specified after the ELSE keyword.
The general syntax of the CASE statement is
CASE
WHEN condition THEN value1
ELSE value 2
END AS name;
There can be as many conditions as you want and is logically justified.
Question 9
Reviews Bins on Reviews Number
“To better understand the effect of the review count on the price of accommodation, categorize the number of reviews into the following groups along with the price.
0 reviews: NO
1 to 5 reviews: FEW
6 to 15 reviews: SOME
16 to 40 reviews: MANY
more than 40 reviews: A LOT
Output the price and its categorization. Perform the categorization on accommodation level.”
Link to the question: https://platform.stratascratch.com/coding/9628-reviews-bins-on-reviews-number
Data
The question uses table airbnb_search_details.
| id | int |
| price | float |
| property_type | varchar |
| room_type | varchar |
| amenities | varchar |
| accommodates | int |
| bathrooms | int |
| bed_type | varchar |
| cancellation_policy | varchar |
| cleaning_fee | bool |
| city | varchar |
| host_identity_verified | varchar |
| host_response_rate | varchar |
| host_since | datetime |
| neighbourhood | varchar |
| number_of_reviews | int |
| review_scores_rating | float |
| zipcode | int |
| bedrooms | int |
| beds | int |
Here’s a data sample.

Solution
The CASE statement is here used to organize data into groups. You don’t need to think of your own criteria; it’s already there in the question.
Translate this to an SQL syntax.
SELECT CASE
WHEN number_of_reviews = 0 THEN 'NO'
WHEN number_of_reviews BETWEEN 1 AND 5 THEN 'FEW'
WHEN number_of_reviews BETWEEN 5 AND 15 THEN 'SOME'
WHEN number_of_reviews BETWEEN 15 AND 40 THEN 'MANY'
WHEN number_of_reviews > 40 THEN 'A LOT'
END AS reviews_qualificiation,
price
FROM airbnb_search_details;
Here’s the organized data.

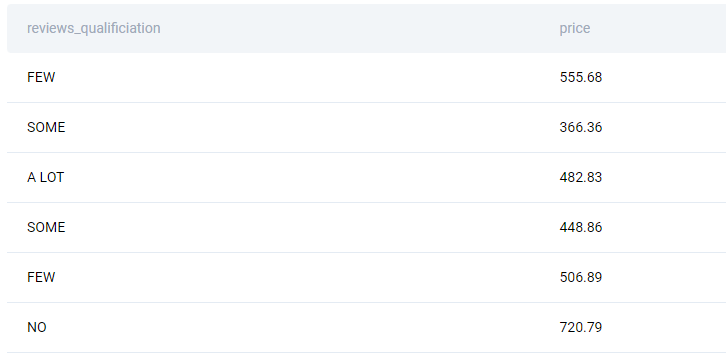
Question 10
European and Non-European Olympics
“Add a column to each row which will classify Olympics that athlete is competing in as 'European' or 'NonEuropean' based on the city it was hosted. Output all details along with the corresponding city classification.
European cities are Athina, Berlin, London, Paris, Albertville, and Lillehammer.”
Link to the question: https://platform.stratascratch.com/coding/10185-european-and-non-european-olympics
Data
The table olympics_athletes_events has all the data you need.
| id | int |
| name | varchar |
| sex | varchar |
| age | float |
| height | float |
| weight | datetime |
| team | varchar |
| noc | varchar |
| games | varchar |
| year | int |
| season | varchar |
| city | varchar |
| sport | varchar |
| event | varchar |
| medal | varchar |
Here’s the illustration of how data looks like.

Solution
There are no requests other than classifying the cities, so you can select all the columns from the table.
Instead of writing six different WHEN expressions, it’s easier to state all the conditions in the IN clause. All these cities will be categorized as European, while all other are NonEuropean.
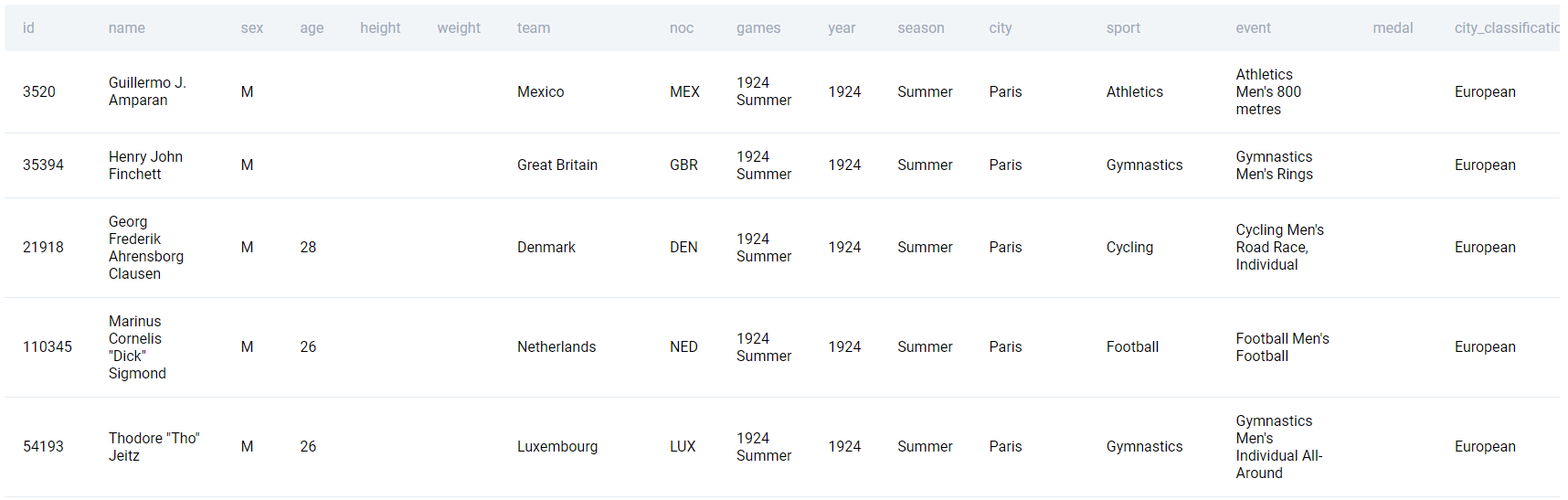
SELECT *,
(CASE
WHEN city IN ('Athina',
'Berlin',
'London',
'Paris',
'Lillehammer',
'Albertville') THEN 'European'
ELSE 'NonEuropean'
END) AS city_classification
FROM olympics_athletes_events;
The code returns the following data.

Question 11
Requests Acceptance Rate
“Find the acceptance rate of requests which is defined as the ratio of accepted contacts vs all contacts. Multiply the ratio by 100 to get the rate.”
Link to the question: https://platform.stratascratch.com/coding/10133-requests-acceptance-rate
Data
There’s a table airbnb_contacts provided.
| id_guest | varchar |
| id_host | varchar |
| id_listing | varchar |
| ts_contact_at | datetime |
| ts_reply_at | datetime |
| ts_accepted_at | datetime |
| ts_booking_at | datetime |
| ds_checkin | datetime |
| ds_checkout | datetime |
| n_guests | int |
| n_messages | int |
Here’s the data from the table.

Solution
The CASE statement can also be used in the aggregate functions, as shown below.
We’re using it for summing up the number of accepted contracts. If there is a value other than NULL in the column ts_accepted_at, that means the contract was accepted. For every such contract, allocate value 1 to the column ts_accepted_at. That way, you’ll be able to sum these values using the SUM() function.
Divide the result by the count of all contracts, and multiply it by a hundred to get the rate.
SELECT 100.0*SUM(CASE
WHEN ts_accepted_at IS NOT NULL THEN 1
ELSE 0
END)/COUNT(*) acceptance_rate
FROM airbnb_contacts;
Here’s the required rate value.


Question 12
Workers With The Highest Salaries
“Find the titles of workers that earn the highest salary. Output the highest-paid title or multiple titles that share the highest salary.”
Link to the question: https://platform.stratascratch.com/coding/10353-workers-with-the-highest-salaries
Data
To get the solution, use these two tables: worker and title.
Table: worker
| worker_id | int |
| first_name | varchar |
| last_name | varchar |
| salary | int |
| joining_date | datetime |
| department | varchar |
The data is given below.

Table: title
| worker_ref_id | int |
| worker_title | varchar |
| affected_from | datetime |
Here are the workers’ titles.

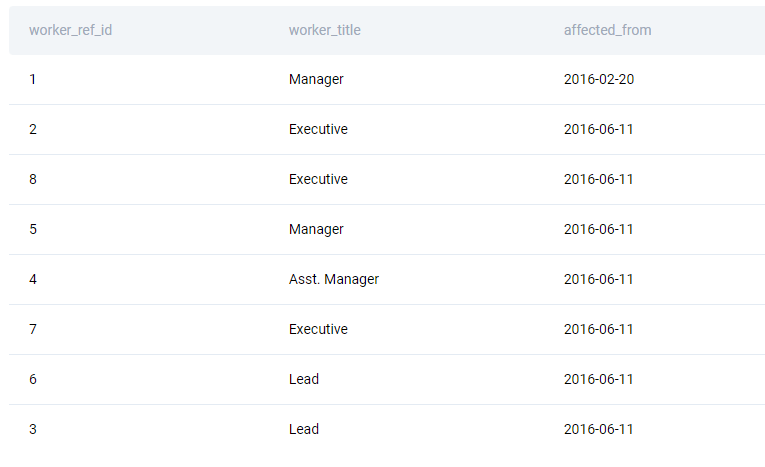
Solution
The solution is heavily reliant on you knowing all three concepts covered in the Basic SQL 2 assignment: JOINs, subqueries, and CASE statements.
The subquery will first be used in the FROM clause. The CASE statement is used to output the title of the worker whose salary is equal to the highest salary of all the employees. To get the highest salary, you need another subquery with the MAX() function in the WHEN expression.
The first subquery fetches data from both worker and title tables. Finally, the output has to exclude the rows with NULL values.
SELECT *
FROM
(SELECT CASE
WHEN salary =
(SELECT max(salary)
FROM worker) THEN worker_title
END AS best_paid_title
FROM worker a
INNER JOIN title b ON b.worker_ref_id=a.worker_id
ORDER BY best_paid_title) sq
WHERE best_paid_title IS NOT NULL;
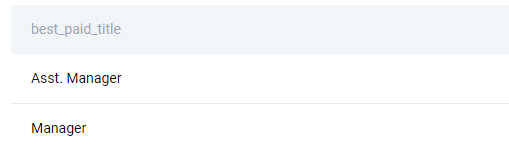
There are only two job titles with the highest salary.

Share


