A Beginner’s Guide to Collinearity: What it is and How it affects our regression model

Categories:
 Written by:
Written by:Nathan Rosidi
What is Collinearity? How does it affect our model? How can we handle it?
When we are building a regression model, we obviously want to model the relationship between a dependent variable and one or more independent variables. However, more often than not, we might encounter a situation where the fitted coefficient of each independent variable ‘doesn’t make sense’ and we can’t explain why it occurs. If you ever encounter this situation, there might be a collinearity in your regression model.
What is Collinearity?
Collinearity occurs because independent variables that we use to build a regression model are correlated with each other. This is problematic because as the name suggests, an independent variable should be independent. It shouldn’t have any correlation with other independent variables.
If collinearity exists between independent variables, the key point of regression analysis is violated. In regression analysis, we want to isolate the influence of each independent variable to our dependent variable. This way, we can interpret the fitted coefficient of each independent variable as the mean change in the dependent variable for each 1 unit change in an independent variable while keeping the other independent variables constant.
Now if we have collinearity, the key point above is no longer valid, as if we change the value of one independent variable, the other independent variables that are correlated will also change.
In this post, we are going to see why collinearity becomes such a problem for our regression model, how we can detect it, how it affects our model, and what we can do to remove collinearity.
The Problem of Collinearity
There are several things how collinearity would affect our model, which are:
- The coefficient estimates of independent variables would be very sensitive to the change in the model, even for a tiny change. Let’s say we want to remove or add one independent variable, the coefficient estimates then will fluctuate massively. This makes it difficult for us to understand the influence of each independent variable.
- Collinearity will inflate the variance and standard error of coefficient estimates. This in turn will reduce the reliability of our model and we shouldn’t trust the p-Value that our model showed us to judge whether an independent variable is statistically significant for our model or not.
To make it more clear why collinearity is such a problem, let’s take a look at the following use case.
Let’s imagine we want to predict the price of a car. To predict it, we have independent variables such as the car’s city MPG, highway MPG, horsepower, engine size, stroke, width, peak RPM, and compression ratio. Next, we build a regression model and below is the summary statistics of our model.
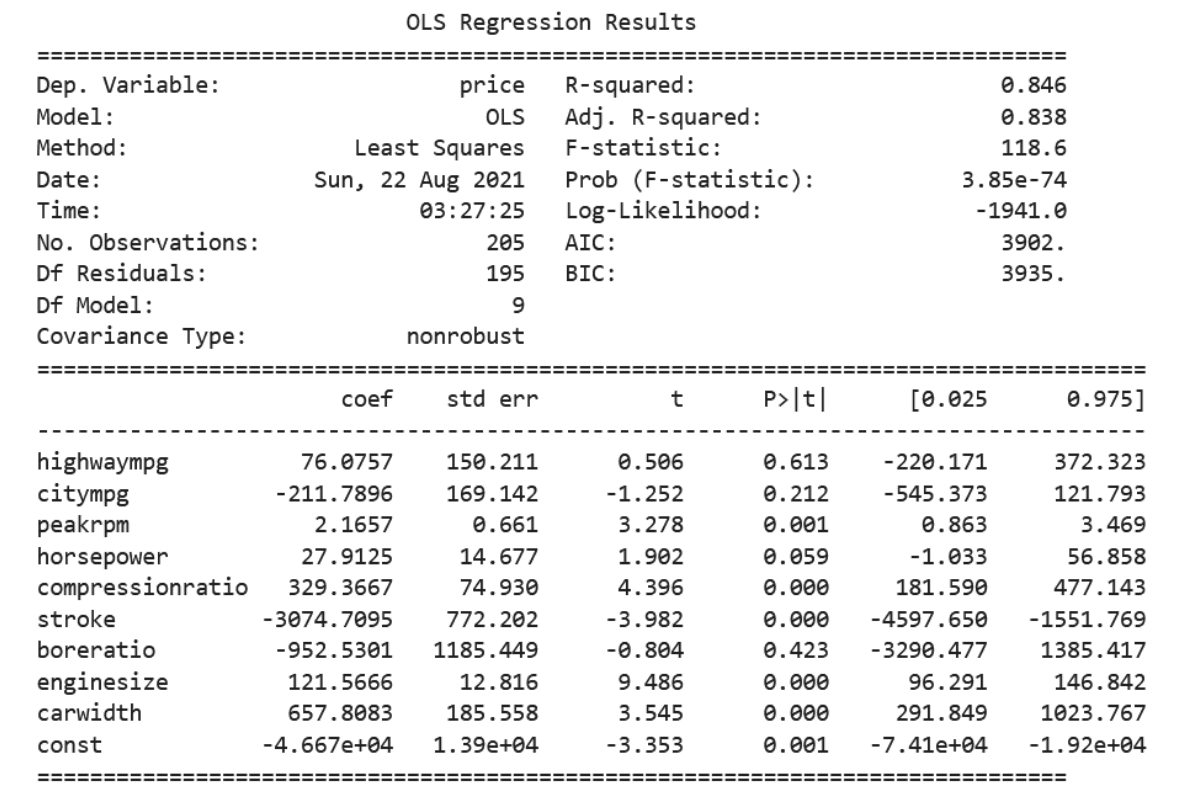
Our model is actually doing pretty good, as it has an R^2 of 84%. Now the problem comes when we try to interpret the model. If we take a look at the coefficient estimates, highway MPG (76.07) and city MPG (-211.78) have the opposite signs. This doesn’t make sense at all because if a highway MPG of a car increases its price, then city MPG should also do the same. But this is not the case.
Also, the p-Value of both highway MPG and city MPG are shown insignificant by the model (>0.05), indicating that we can exclude them from our regression model. But are they actually insignificant? If we reckon that there might be a slight chance of collinearity in the model, we shouldn’t trust this p-Value straight away.
Detecting Collinearity
There are two easy ways to detect if collinearity exists in our regression model.
Correlation Matrix
The first one is by looking at the correlation matrix of our independent variables. The rule of thumb is that if two independent variables have a Pearson’s correlation above 0.9, then we can say that both independent variables are highly correlated with each other and thus, they are collinear. This is the correlation matrix of our use case.
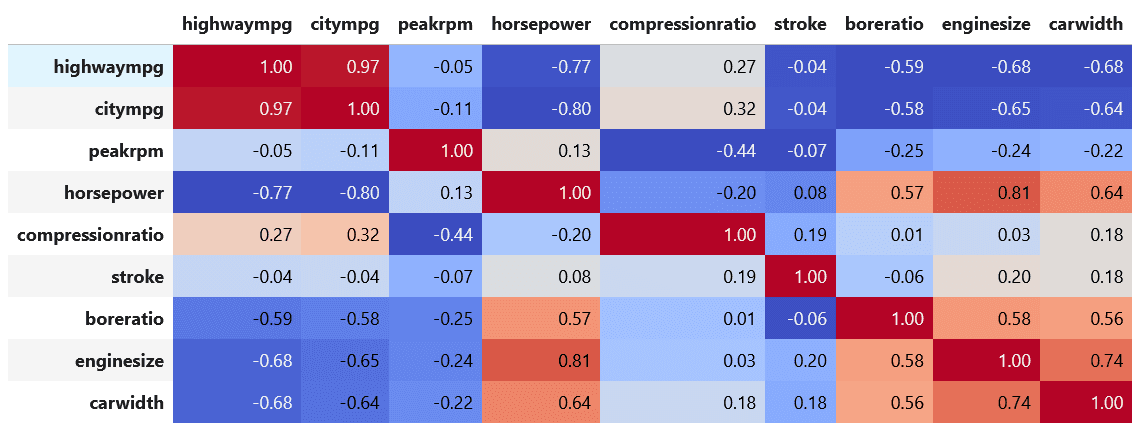
From the image above, we can clearly see that highway MPG and city MPG are highly correlated, as they have a Pearson’s correlation of 0.97. As they have a positive correlation, this means that if we increase the highway MPG, the city MPG will also increase in almost the same amount.
Variance Inflation Factor
Variance Inflation Factor or VIF measures the influence of collinearity on the variance of our coefficient estimates. VIF can be described mathematically as follows:
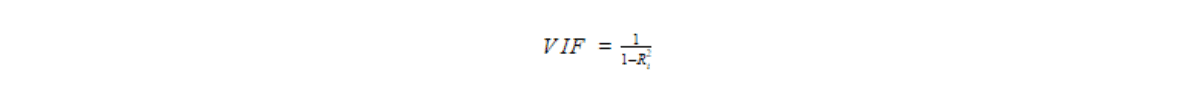
From the equation above, we know that if Ri^2 of independent variable xi is large or close to 1, then the corresponding VIF of xi would be large as well. This means that independent variable xi can be explained by other independent variables or in other words, xi is highly correlated with other independent variables. Thus, the variance of the coefficient estimate βi is also high.
Below is the VIF of our independent variables in our use case:

There are a lot of discussions about what would be the appropriate threshold value of VIF before we decide that the collinearity of our independent variables is a cause of concern, but most research papers agree that VIF above 10 indicates a severe collinearity among independent variables.
In our use case, we can see that highway MPG and city MPG have VIF scores way above 10, indicating that they are highly correlated with each other. We can see this phenomenon as well from the correlation matrix above.
Check out our comprehensive statistics cheat sheet to know about important terms and equations for statistics and probability
Removing Collinearity
Now that we know severe collinearity exists in our independent variables, we need to find a way to fix this. There are two common ways to remove collinearity.
Variable Selection
This is the most straightforward solution to remove collinearity and oftentimes, domain knowledge would be extremely helpful to achieve the best solution. To remove collinearity, we can exclude independent variables that have a high VIF value from our regression model. Let’s take a look at the example of our use case why domain knowledge would be helpful in this case:
- We know that highway MPG and city MPG have a high VIF value. If we have domain knowledge, we know that it’s not necessary to exclude both from our regression model. Instead, we only need to pick either one of them. Let’s say that we exclude highway MPG from our model.
- We also know that horsepower and engine size have moderately high VIF value as well. Although they measure different things, higher engine size or engine displacement generally corresponds to higher horsepower. Thus, we exclude horsepower from our model.
In the end, we built our regression model once again, but this time without highway MPG and horsepower.

And now we don’t have a severe collinearity among independent variables anymore. Now we can proceed with our regression analysis.
Principal Component Analysis
The second method to remove collinearity is by using Principal Component Analysis or PCA, which is a method that is commonly used for dimensionality reduction. This method would be beneficial to remove collinearity because PCA will decompose our independent variables into a certain number of independent factors.
However, removing collinearity with PCA comes with a big drawback. Since the independent factors that we got from PCA are totally different from our original independent variables, we don’t have the identity of our independent variables anymore. This seems rather counter-intuitive, since the main reason why we remove collinearity is to make it easier for us to interpret the influence of independent variables to our dependent variable.
The Effect of Removing Collinearity in Regression Model
Now that we remove collinearity in our independent variables, let’s compare the regression model with collinearity and without collinearity.
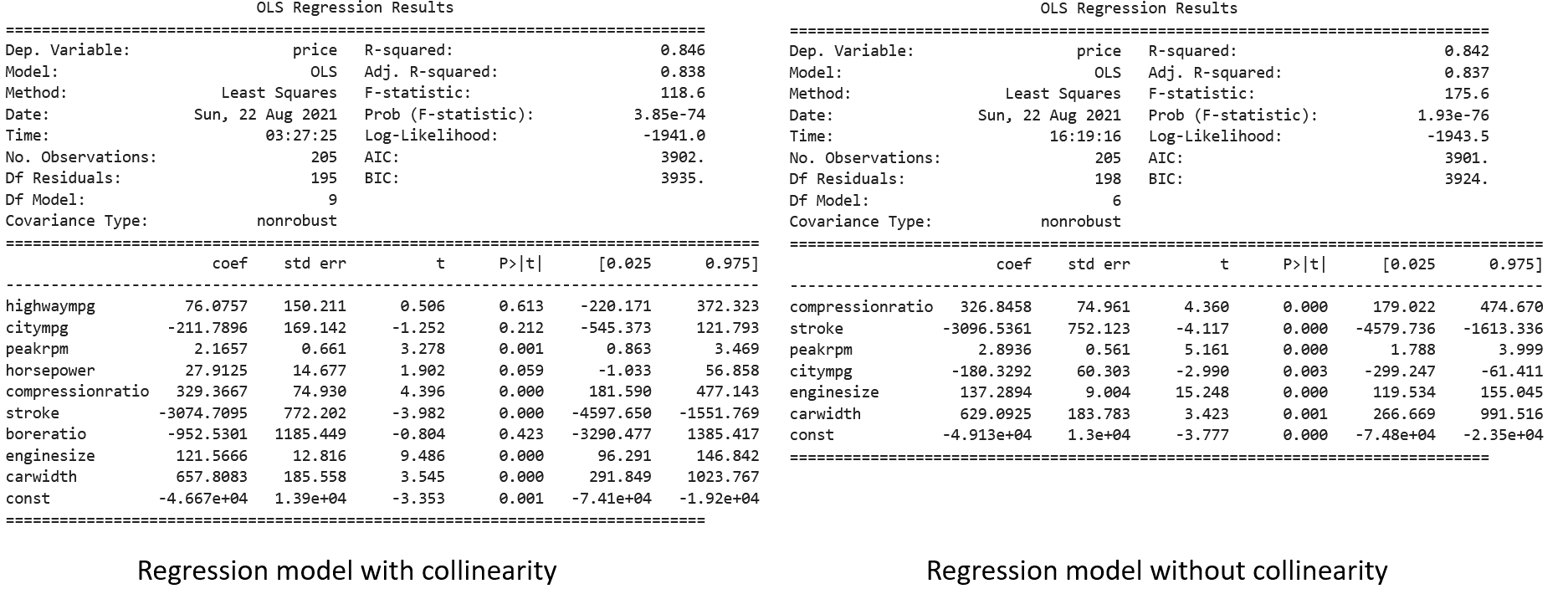
In the left hand side, we have our regression model with collinearity and in the right hand side, we have our regression model after we remove collinearity with variable selection.
The problem with collinearity is that it will inflate the variance or standard error of coefficient estimates. Now if we take a look at both models, the standard error of coefficient estimates in a regression model without collinearity is much less than the model with collinearity. The most apparent one is the city MPG variable. When collinearity exists, the standard error of the coefficient estimates of this variable is 169.14 compared to 60.30 when the collinearity is removed.
If we take a look at the p-Value, the model with collinearity concludes that the city MPG variable is statistically insignificant, meaning we can exclude this variable from our model for better performance. However, when we remove the collinearity, the p-Value of this variable is 0.003, which is actually statistically significant. Collinearity will inflate the variance of coefficient estimates of independent variables, making it difficult for us to trust the resulting p-Value from the model.
Moreover, with sufficient variable selection, the F-statistics of the model without collinearity is much more significant than the model with collinearity, although the model with collinearity has more independent variables.
Do we Need to Remove Collinearity?
One important thing that we should notice is that collinearity would not affect the model prediction or the accuracy of the model. If you look at the R^2 comparison between the model with and without collinearity above, they are both similar. In fact, the model with collinearity typically yields to a better accuracy due to the fact it generally has more independent variables.
Collinearity only affects the variance of coefficient estimates and the p-Values. It affects the interpretability of the model, not the ability of the model to predict.
So, if you want to build a regression model to make predictions and you don’t need to understand the influence of each independent variable, then you don’t need to remove collinearity in your model.
However, if model interpretation is important for you and you need to understand the influence of each independent variable to model’s prediction, then removing collinearity in your model is necessary.
Share